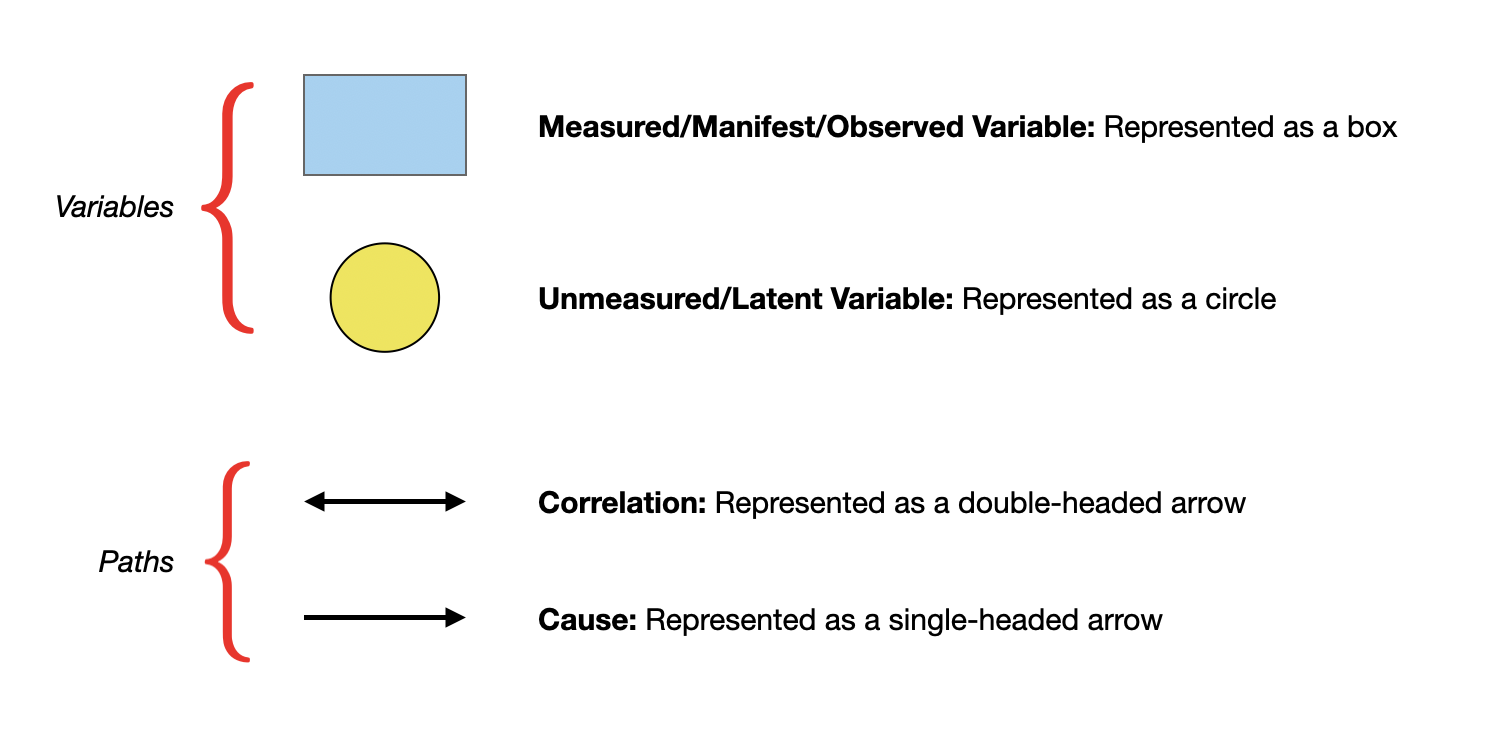
📝 Path Analysis
12/1/22
Reading a Path Diagram (cntd.)
Two Example Path Diagrams
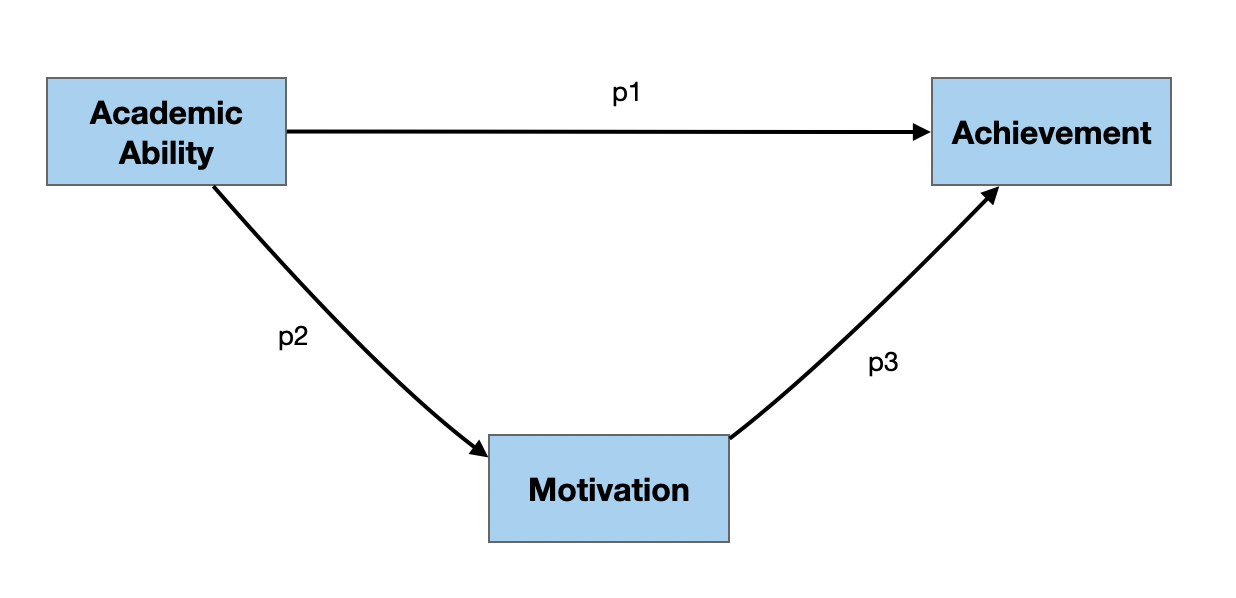
In both of the examples below, there are three manifest/measured variables (academic ability, motivation, and achievement) and three paths (p1, p2, and p3). The difference between the two is that in the right-hand diagram, there are hypothesized causal relationships, while in the left-hand diagram the relationships are not presumed to be causal.
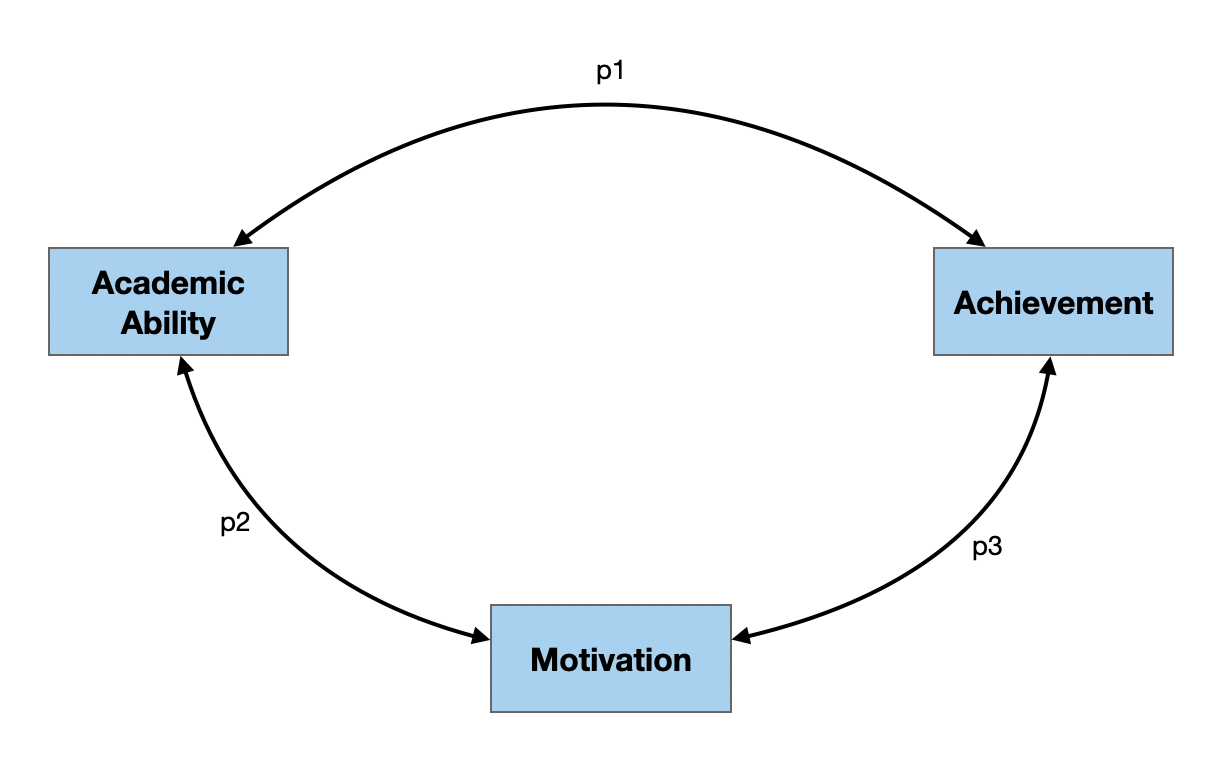
Path Diagram 1
The model depicted in this path diagram posits that there are relationships between:
- Academic ability and achievement (p1);
- Academic ability and motivation (p2); and
- Motivation and achievement (p3).
The double-headed arrows on the paths indicate that the variables are related (i.e., correlated), although there is no causal direction hypothesized.
Estimating Path Coefficients in Path Diagram 1
In a path analysis, one goal is to estimate path coefficients. In this model, since the paths represent the relationship between two variables, the path coefficients are simply the bivariate correlations between each set of variables.
Path Model 2: Weak Causal Ordering
The model depicted in this path diagram posits the following causal relationships:
- If academic ability and achievement are causally related, then academic ability is the cause of achievement.
- If academic ability and motivation are causally related, then academic ability is the cause of motivation.
- If motivation and achievement are causally related, then motivation is the cause of achievement.
Example of the Tracing Rule
As an example, consider all the tracings (routes) that allow us to start at the academic ability variable and go to the achievement variable in the path diagram at right.
There are two possible tracings that conform to the tracing rule:
- Start at the academic ability variable and take p1 to the achievement variable.
- Start at the academic ability variable and take p2 to the motivation variable, then take p3 to the achievement variable.
Example of the Tracing Rule (cntd.)
Similarly, we could have started at the achievement variable and determined the tracings to get to the academic ability variable:
- Start at the achievement variable and take p1 to the academic ability variable.
- Start at the achievement variable and take p3 to the motivation variable, then take p2 to the academic ability variable.
Your Turn
Use the tracing rule to write two more equations. The first equation should represent the correlation between motivation and achievement, and the second equation should represent the correlation between ability and motivation.
Check Your Work
To represent the correlation between motivation and achievement we have two potential tracings:
- Start at the motivation and take p3 to the achievement variable.
- Start at the motivation variable and take p2 to the academic ability variable, then take p1 to the achievement variable.
\[ \begin{split} r_{\mathrm{motivation,~ achievement}} &= p3 + p2(p1) \\[1em] .255&= p3 + p2(p1) \end{split} \]
Check Your Work
To represent the correlation between academic ability and motivation we have one tracing:
- Start at the academic ability and take p2 to the motivation variable.
\[ \begin{split} r_{\mathrm{academic~ability,~ motivation}} &= p2 \\[1em] .205&= p2 \end{split} \]
QUESTION: Why can’t we use the tracing that takes p1 from academic ability to achievement then takes p3 to motivation??
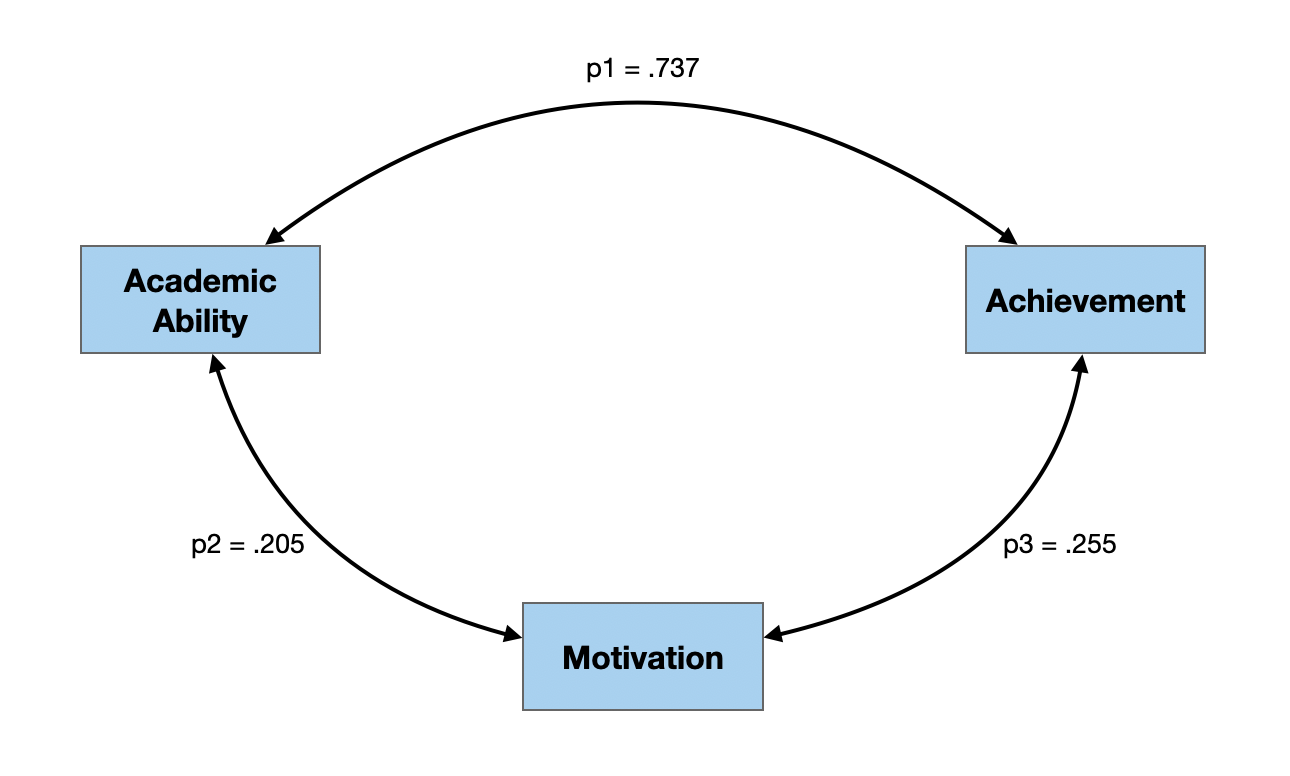
Path Diagram with Estimated Path Coefficients
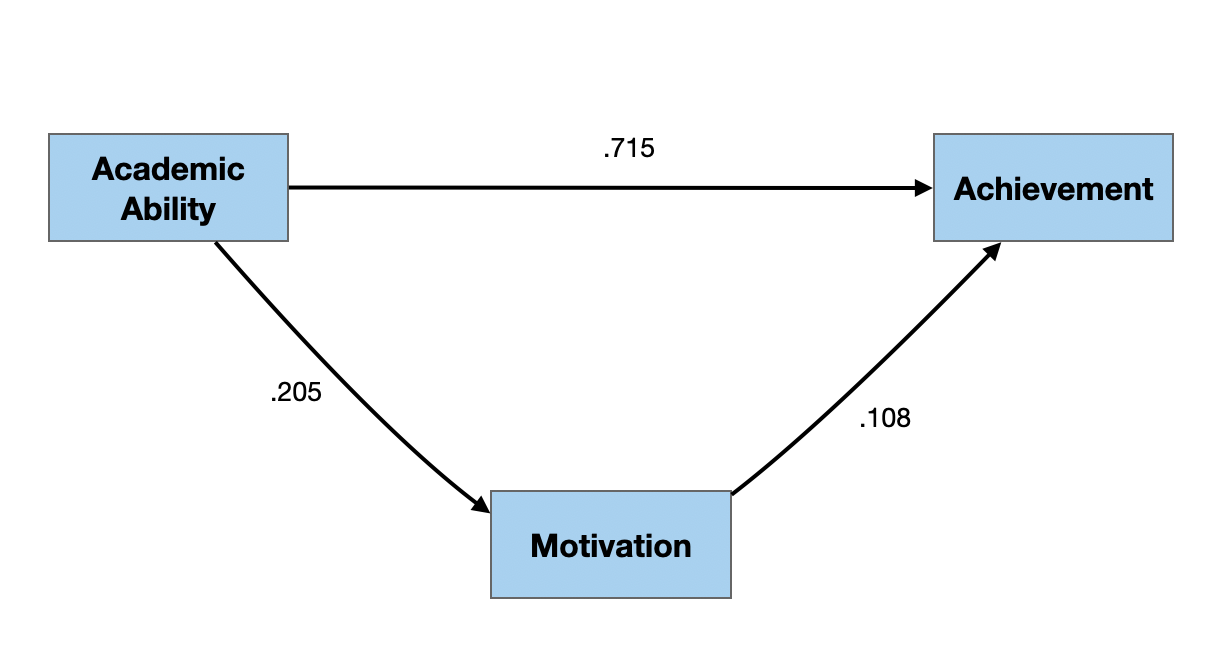
Interpreting Path Coefficients
Path coefficients are standardized coefficients which can be interpreted similar to standardized regression coefficients.
- Given the adequacy of the path model, each 1-standard deviation increase in motivation increases achievement by .108 standard deviations, on average.
- Given the adequacy of the path model, each 1-standard deviation increase in academic ability increases achievement by .715 standard deviations, on average.
- Given the adequacy of the path model, each 1-standard deviation increase in academic ability increases motivation by .205 standard deviations, on average.
Estimating Path Coefficients via Regression
We can also find the path coefficients using regression rather than algebra. To determine the path coefficients in the weak causal model, we fit a set of regression models using the “causes” as predictors of any particular effect.
In our path diagram there are two effects, so we would need to fit two separate regression models. The syntax for these models would be:
achievement ~ 0 + ability + motivation
motivation ~ 0 + abilityResidual Variation
Even if the causal relationships were specified correctly, the model likely does not include ALL of the causes for motivation and achievement. There is also unaccounted for variation due to random variation and measurement error. To account for these three sources of variation in the weak causal model, we will add an error term to eavch of the effects in the path model.
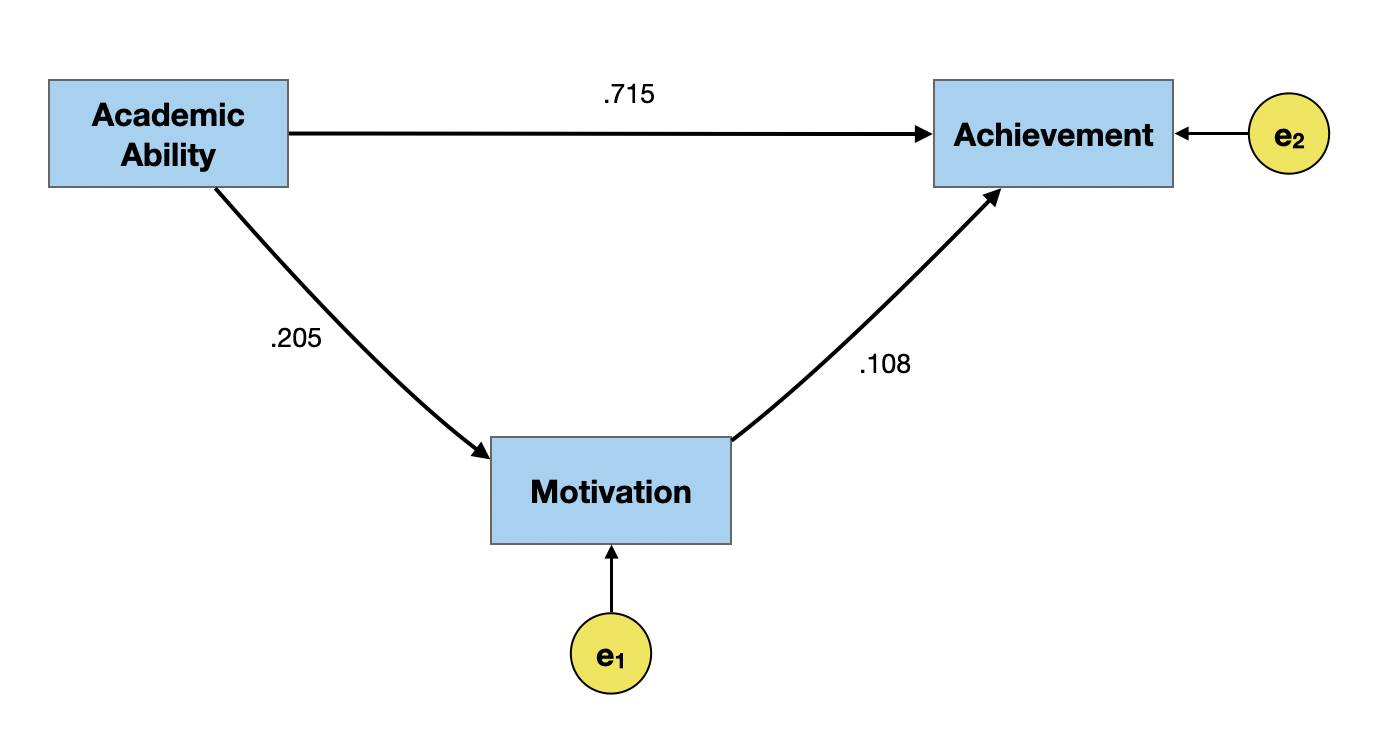
Estimating Residual Variation (cntd.)
# Path coefficients for error term on achievement
glance(lm(achievement ~ 0 + ability + motivation, data = sim_dat))# A tibble: 1 × 12
r.squared adj.r.squ…¹ sigma stati…² p.value df logLik AIC BIC devia…³
<dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 0.554 0.554 0.668 621. 6.36e-176 2 -1014. 2034. 2049. 445.
# … with 2 more variables: df.residual <int>, nobs <int>, and abbreviated
# variable names ¹adj.r.squared, ²statistic, ³deviance[1] 0.6678323# Path coefficient for error term on motivation
glance(lm(motivation ~ 0 + ability, data = sim_dat))# A tibble: 1 × 12
r.squ…¹ adj.r…² sigma stati…³ p.value df logLik AIC BIC devia…⁴ df.re…⁵
<dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <int>
1 0.0420 0.0411 0.979 NA NA NA -1397. 2798. 2808. 957. 999
# … with 1 more variable: nobs <int>, and abbreviated variable names
# ¹r.squared, ²adj.r.squared, ³statistic, ⁴deviance, ⁵df.residual[1] 0.9787747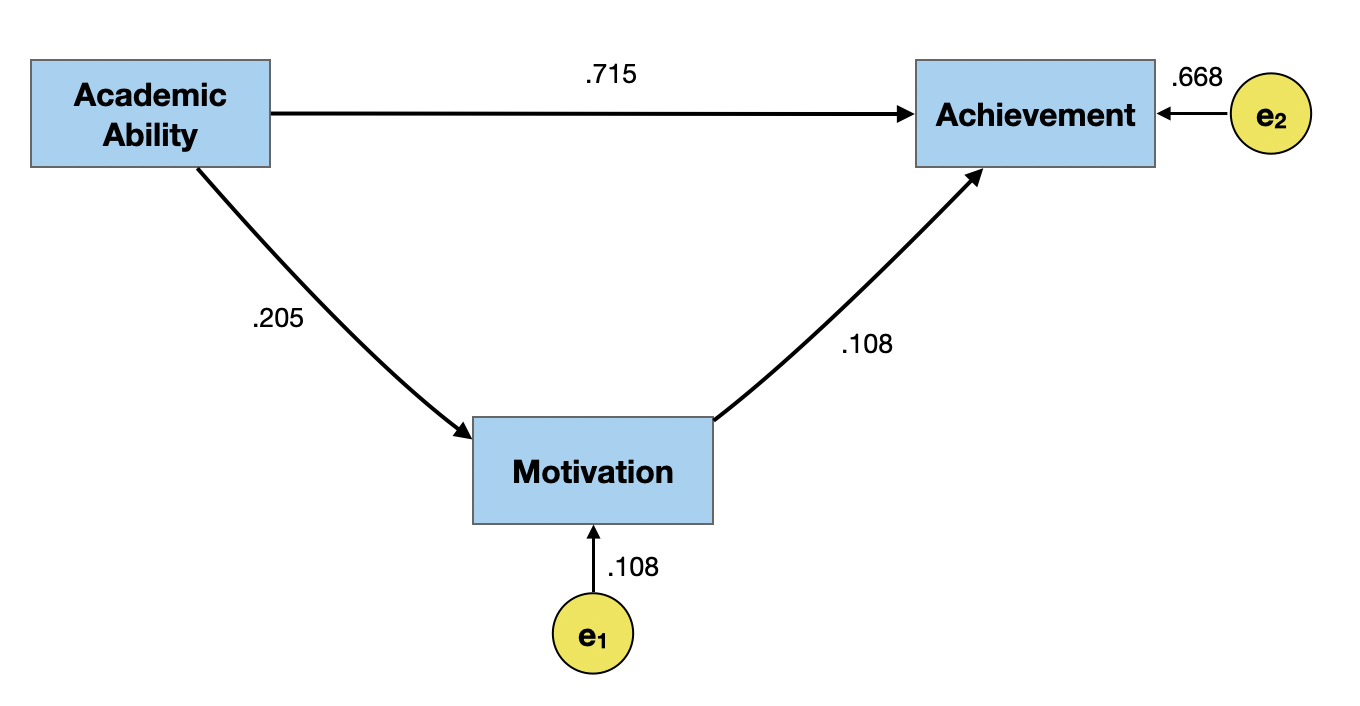
A Little More About Cause
What do we mean when we say “X causes Y”? Contrary to popular belief, we do not mean that changing X has a direct, and immediate change on Y. For example, it is now well known that smoking causes lung cancer.
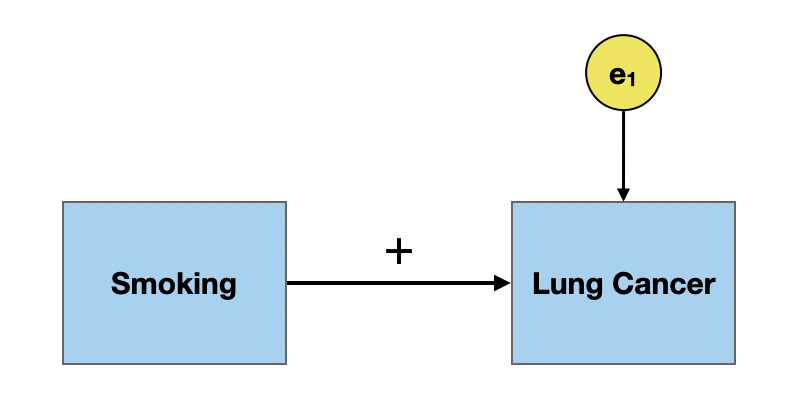
But, not everyone who smokes ends up getting lung cancer.
Including Time Precedence in the Path Diagram
Time precedence is often reflected in the orientation of the model. Variables that occur earlier in time are oriented further to the left side of the diagram than variables that occur later.
In the smoking example, to be considered the cause for lung cancer, smoking has to occur prior to the onset of lung cancer.1
Including Time Precedence in the Path Diagram (cntd.)
In our path diagram relating academic ability and motivation to acheivement, academic ability is furthest to the left (it occurs earliest), followed by motivation, and then academic achievement.
Common Cause
A common cause is a variable that is a cause of both X and Y which accounts for the relationship between X and Y. Consider the following example where we want to look at the causal impact of participation in Head Start programs on academic achievement.
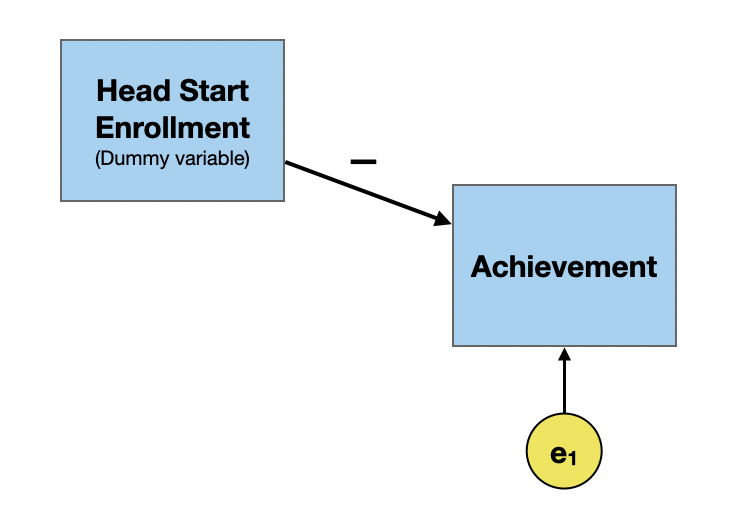
In practice, the path coefficient tends to be negative. That is Head Start participants tend to have lower academic achievement than their non-Head Start peers.
Common Cause (cntd.)
A common cause of both Head Start participation and academic achievement is poverty. This is shown below.
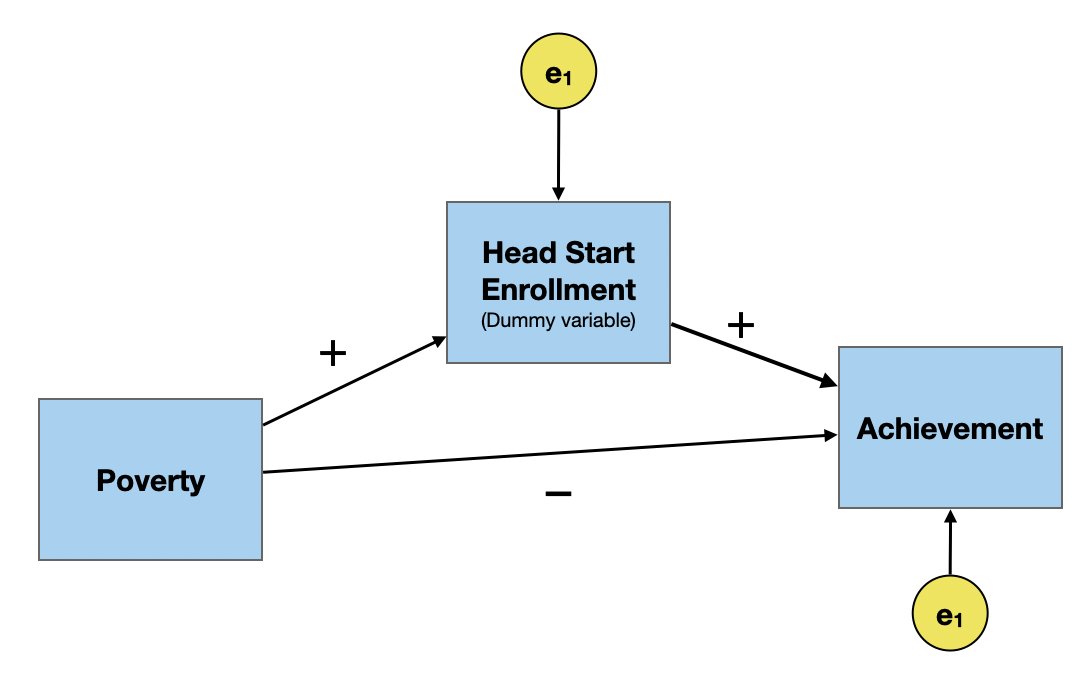
Once we include poverty as a common cause, the path coefficient between Head Start participation and academic achievement switches direction. That is, after including poverty in the path model, Head Start participants tend to have higher academic achievement than their non-Head Start peers. This is akin to how effects in a regression model might change after we control for other predictors.
Non-Recursive Models
In the path diagrams we have looked at so far, the causal paths have gone in only one direction; there is a distinct cause and effect. The error terms on the effect variables are also all uncorrelated. These are called recursive models. It is possible for variables to effect each other (e.g., predator–prey relationships), or for the error terms to be correlated. This is called a non-recursive model.
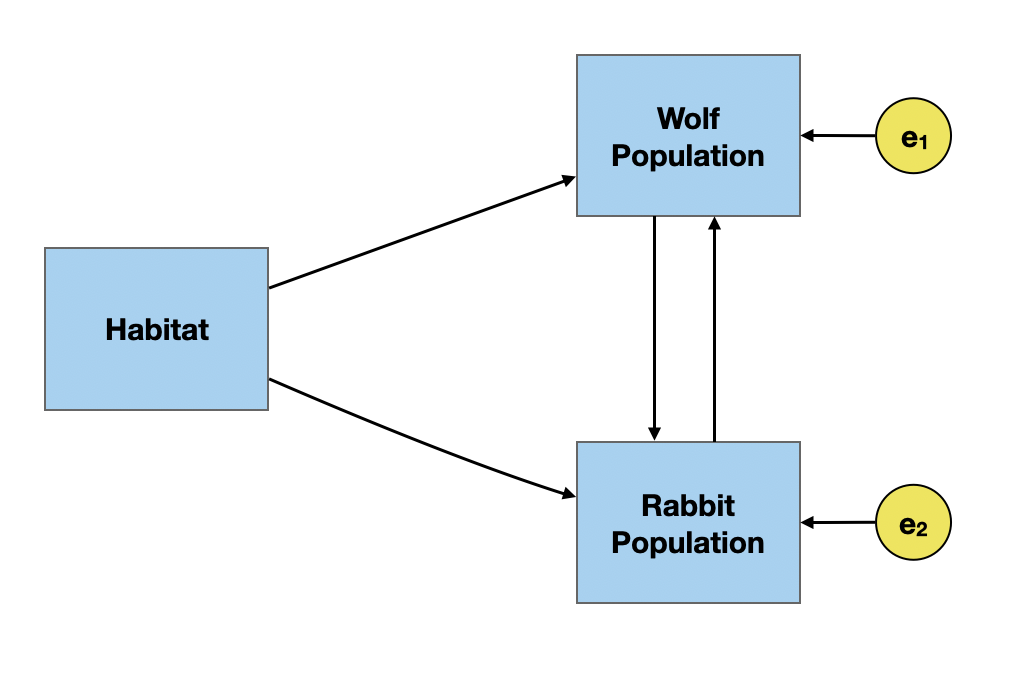
Under-Identified Models
The problem with estimating the path coefficients in the non-recursive model is it is under-identified. In our predator–prey model, we need to estimate four path coefficients, but only have three correlations (equations) from which to do so. We can’t solve this without adding additional constraints!
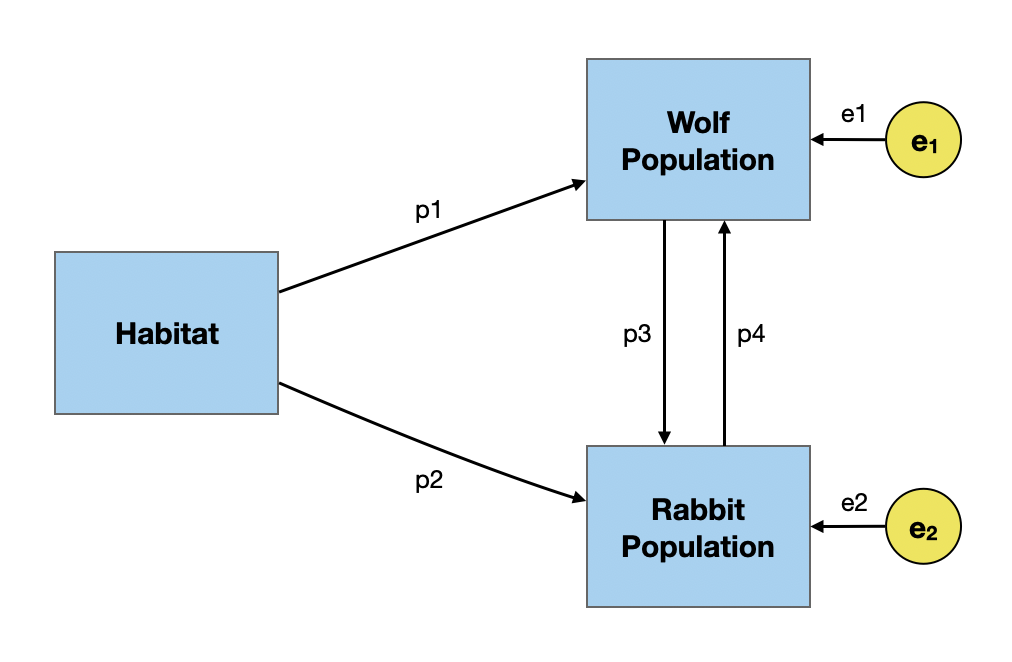
\[ \begin{split} r_{\mathrm{H,W}} &= p1 + p2(p4) \\[1em] r_{\mathrm{H,R}} &= p2 + p1(p3) \\[1em] r_{\mathrm{H,W}} &= p3 + p4 + p1(p2) \end{split} \]