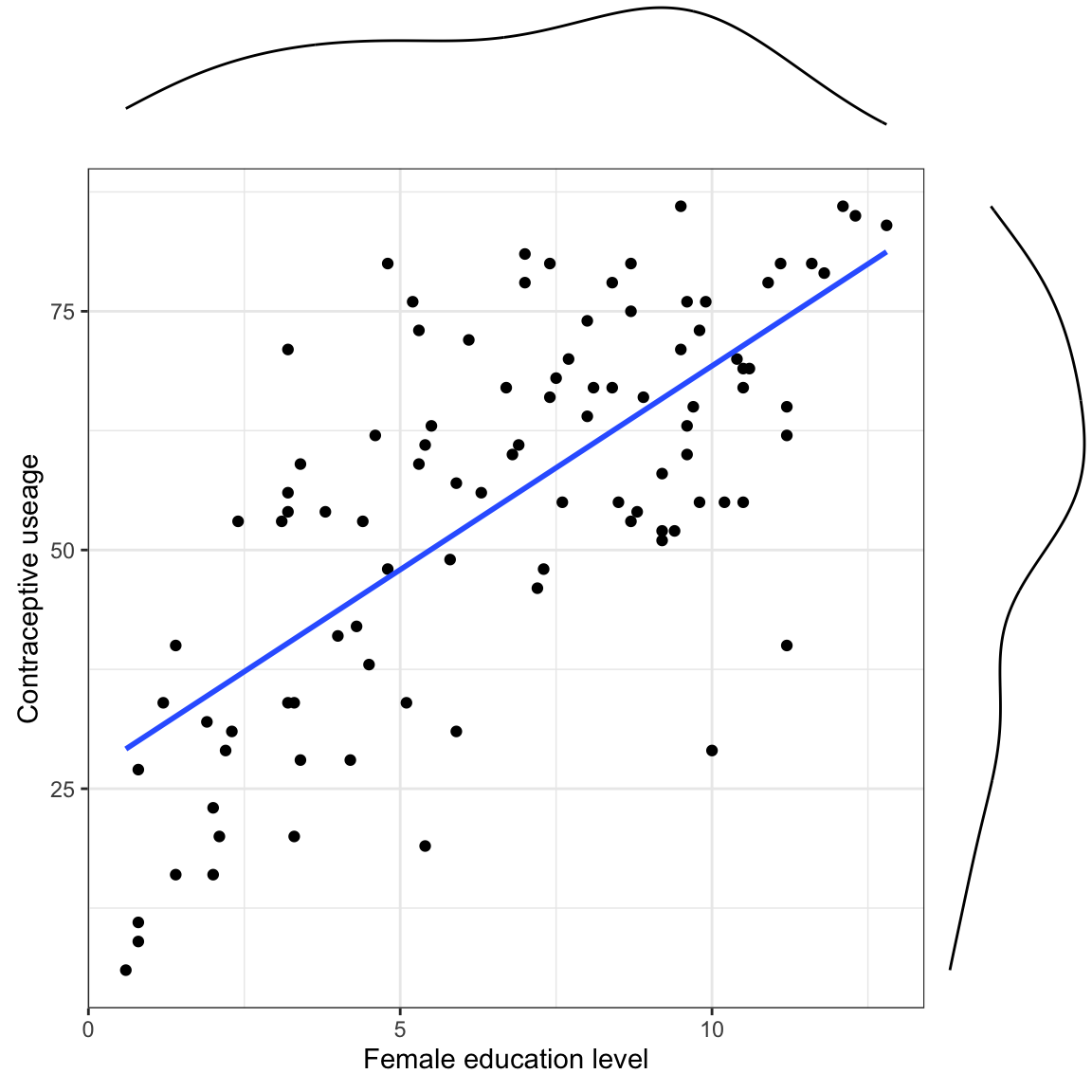
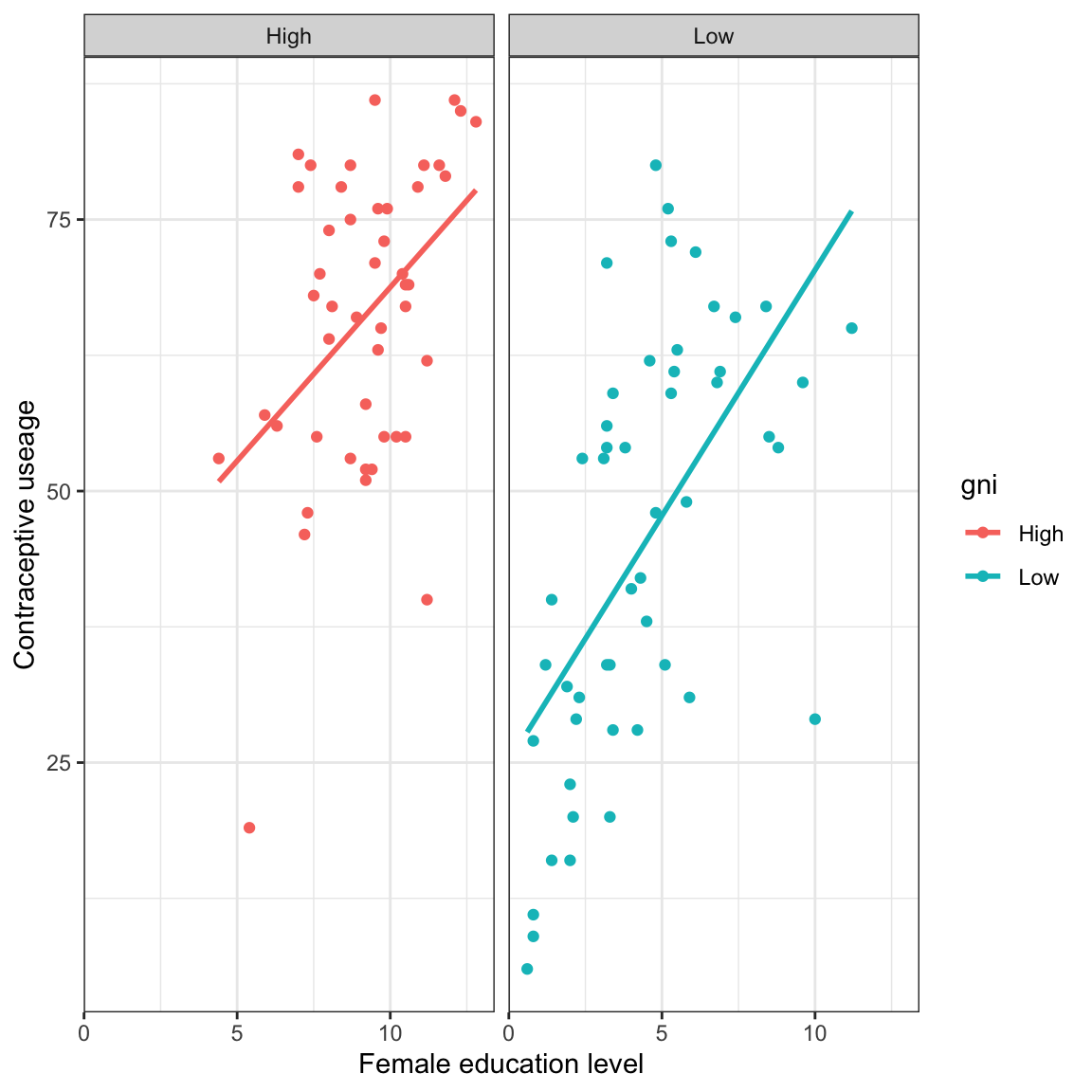
In this document we will use the data in contraception.csv to examine whether female education level explains variation in contraceptive useage after controlling for GNI.
Here we will focus on the effects of female education level since it is our focal predictor. (GNI is a control.) Note this is the second effect in the b vector and in the V matrix. We will test the hypothesis:
# Evaluate t-valuedf = n - k -1p =2* (1-pt(abs(t_0), df = df))p
[1] 0.00000001143799
Here,
\[
t(94) = 6.26,~p=0.0000000114
\]
The evidence suggests that the data are not very compatible with the hypothesis that there is no effect of female education level on contraceptive useage, after controlling for differences in GNI.
Statistical Inference: Confidence Intervals for the Coefficients
From the hypothesis test, we believe there is an effect of female education level on contraceptive useage, after controlling for differences in GNI. What is that effect? To answer this we will compute a 95% CI for the effect of female education.
The 95% CI indicates that the population effect of female education level on contraceptive useage, after controlling for differences in GNI is between 2.79 and 5.39.
# Create L (hypothesis matrix)L =matrix(data =c(0, 1, 0, 0, 0, 1),byrow =TRUE,ncol =3)# Create vector of hypothesized valuesC =matrix(data =c(0, 0),ncol =1)q =2F_num =t(L %*% b - C) %*%solve(L %*%solve(t(X) %*% X) %*%t(L)) %*% (L %*% b - C)F_denom = q * s_e^2F_0 = F_num / F_denomF_0
[,1]
[1,] 45.46611
# Evaluate F_01-pf(F_0, df1 = q, df2 = (n - k -1))
[,1]
[1,] 1.532108e-14
Here,
\[
F(2, 94) = 45.47,~p=0.0000000000000153
\]
The data are not very compatible with the hypothesis that the model explains no variation in the outcome. It is likely there is a controlled effect of female education level, or GNI (or both) on contraceptive usage. That is, the explained variation of 49.1% is more than we would expect because of chance.
In Practice
In practice, you would simply use built-in R functions to do all of this. Note that you can use a categorical variable in the lm() function directly (without dummy coding it beforehand), but it will pick the reference category for you (alphabetically). For example:
# Fit modellm.1=lm(contraceptive ~1+ educ_female + gni, data = contraception)# Coefficient-level outputtidy(lm.1)
# Coempute confidence intervals for coefficientsconfint(lm.1)
The design matrix is given and information about this design matrix is also encoded. There is an attribute “assign”, an integer vector with an entry for each column in the matrix giving the term in the formula which gave rise to the column. Value 0 corresponds to the intercept (if any), and positive values to terms in the order given by the term.labels attribute of the terms structure corresponding to object. There is also an attribute called “contrasts” that identifies any factors (categorical variables) in the model and indicates how the contrast testing (comparison of the factor levels) will be carried out. Here “contr.treatment” is used. This compares each level of the factor to the baseline (which is how dummy coding works).