In this set of notes, you will expand your knowledge of the logistic regression model to include categorical predictors, non-linear predictor effects, covariates, and interaction terms. We will again use data from the file graduation.csv to explore predictors of college graduation.
Within the analysis, we will focus on the research question of whether the probability of obtaining a degree differs for first and non-first generation students. We will use information criteria as the framework of evidence to adopt different models, along with an evaluation of the models’ residuals.
# Load librarieslibrary(AICcmodavg)library(broom)library(corrr)library(patchwork)library(performance)library(texreg)library(tidyverse)# Read in data and create dummy variable for categorical variablesgrad =read_csv(file ="https://raw.githubusercontent.com/zief0002/benevolent-anteater/main/data/graduation.csv") |>mutate(got_degree =if_else(degree =="Yes", 1, 0),is_firstgen =if_else(first_gen =="Yes", 1, 0),is_nontrad =if_else(non_traditional =="Yes", 1, 0), )# View datagrad
# Fit models from previous notesglm.0=glm(got_degree ~1, data = grad, family =binomial(link ="logit"))glm.1=glm(got_degree ~1+ act, data = grad, family =binomial(link ="logit"))
Categorical Predictors
We will next turn to evaluating whether first generation students have a different predicted probability of obtaining a degree than non-first generation students. As always, we start with computing summary statistics and plots. Because both the predictor and outcome are categorical, we will again focus on counts and proportions.
# Counts of students by degree and first gen statusgrad |>group_by(degree, first_gen) |>summarize(N =n() )
Contingency Tables
The primary method of displaying summary information when both the predictor and outcome are categorical is via a contingency table. In our two-way table, we will display counts from the four different combinations of first generation and degree obtainment status. Since each of those variables includes two levels (degree/no degree and first gen/non-first gen), this is referred to as a 2x2 table; each number refers to the number of levels in one of the variables being displayed.
Table 1: 2x2 table of counts for degree obtainment by first generation status.
First Generation Status
Obtained Degree
Total
No
Yes
No
267
440
707
Yes
360
1277
1637
Total
627
1717
2344
There are three types of counts (sample sizes) that are typically included in contingency tables:
Cell Counts: The “cells” in the two-way table include counts for the four combinations of first generation and degree obtainment status. The counts in those four cells are referred to as cell counts or cell sample sizes. These are generally notated symbolically as \(n_{i,j}\) where i indicates the row and j indicates the column. For example, \(n_{1,2}=440\) indicates the number of non-first generation students who obtained a degree.
Marginal Counts: The counts in the “Total” row and column are called the marginal counts, or marginal sample sizes. They indicate the total counts collapsing across either rows or columns. These are generally notated symbolically as \(n_{\bullet,j}\) or \(n_{i, \bullet}\) where the dot indicates that we are collapsing across either rows or columns. For example, \(n_{2,\bullet}=1637\) indicates the number of first generation students.
Grand Count: Finally, there is the cell that includes the grand total sample size. This is usually just denoted as N (or sometimes \(n_{\bullet,\bullet}\)). In our example, \(n=2344\), the total number of students in the sample.
The three different totals (row total, column total, grand total) means that we can compute three different proportions for each of the four cells. Each proportion has a different interpretation depending on which total is used in the denominator. For example, consider the cell that designates first generation students who obtained a degree (\(n_{2,2}=1227\)).
The grand total of 2344 indicates all student, so computing the proportion using that denominator, \(1227/2344 = 0.523\), indicates that 0.523 of all students are first generation who obtained a degree.
The row total of 1637 indicates the number of students who are first generation students, so computing the proportion using that denominator, \(1227/1637 = 0.750\), indicates that 0.750 of all first generation students obtained a degree.
The column total of 1717 indicates the number of students who obtained a degree, so computing the proportion using that denominator, \(1227/1717 = 0.715\), indicates that 0.715 of students who obtained a degree are first generation students.
Computing Proportions: Order in group_by() Matters
We can compute proportions using the row and column totals in the denominator by using the same set of dplyr operations we used previously, namely grouping by the predictor and outcome, summarizing to compute the sample size, and then mutating to find the proportion. The key is the order in which we include the variables in group_by().
If we want to use the row totals (the number of first generation and non-first generation students) in the denominator, we need to include first_gen in the group_by() prior to degree. The computation of sum() in mutate() will continue to be based on the first generation grouping (group_by() is in effect until we explicitly use ungroup()).
# Use first generations status totals in proportiongrad |>group_by(first_gen, degree) |>summarize(N =n()) |>mutate(Prop = N /sum (N) )
To compute proprtions based on the number of students who obtained a degree and the number who did not obtain a degree, we need to include degree in the group_by() function prior to first_gen.
# Use degree status totals in proportiongrad |>group_by(degree, first_gen) |>summarize(N =n()) |>mutate(Prop = N /sum (N) )
If you want to base the proportions on the grand total, the order in group_by() doesn’t matter, but you need to explicitly ungroup() prior to computing the proportions.
# Use grand total in proportiongrad |>group_by(degree, first_gen) |>summarize(N =n()) |>ungroup() |>mutate(Prop = N /sum (N) )
You need to select the the denominator to compute your proportions based on your research questions. You also need to make sure that if you are using R (or another software) to compute proportions that the proportions you want are being outputted.
Back to the RQ
We wanted to know whether first generation students have a different predicted probability of obtaining a degree than non-first generation students. Thus, we want to use the row totals in our denominator. So we are comparing the proportion of all first generation students who got a degree to the proportion of all non-first generation students who got a degree.
# Proportions to answer our RQgrad |>group_by(first_gen, degree) |>summarize(N =n()) |>mutate(Prop = N /sum (N) ) |>ungroup() |>filter(degree =="Yes")
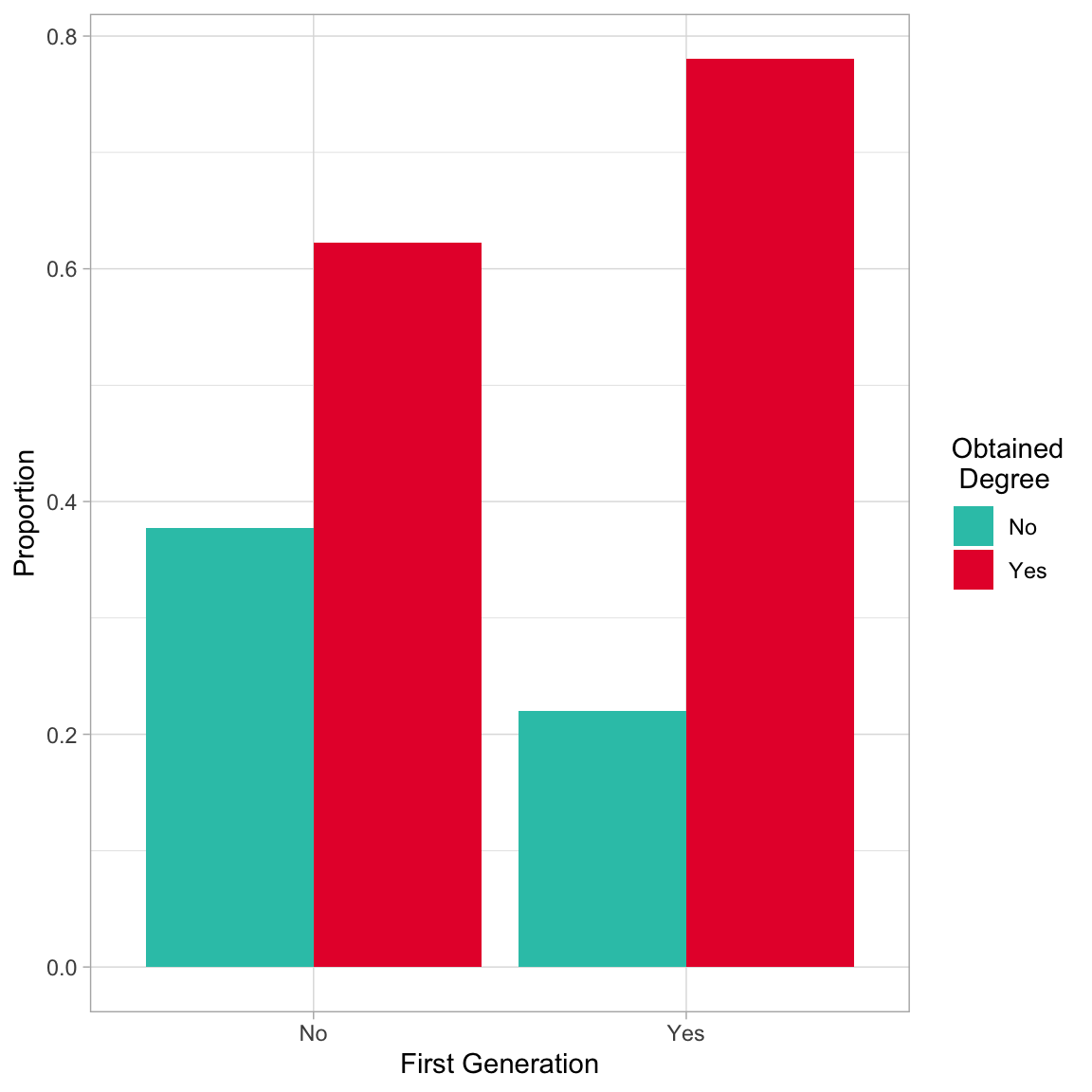
Based on the sample proportions, the proportion of first generation students who obtain a degree (0.780) is higher by 0.158 than the proportion of non-first generation students who obtain a degree (0.622). We could also plot this using a bar chart. The argument position=position_dodge() creates the side-by-side plot. Otherwise the plot would be a stacked bar chart which gives the same information.
# Side-by-side bar chartgrad |>group_by(first_gen, degree) |>summarize(N =n()) |>mutate(Prop = N /sum (N) ) |>ungroup() |>ggplot(aes(x = first_gen, y = Prop, fill = degree)) +geom_bar(stat ="Identity", position =position_dodge()) +theme_light() +xlab("First Generation") +ylab("Proportion") +scale_fill_manual(name ="Obtained\n Degree",values =c("#2EC4B6", "#E71D36") )
Side-by-side barplot showing the proportion of first generation and non-first generation students in the sample who obtained and did not obtain a degree.
To evaluate whether this sample difference is more than we expect because of chance, we could create a dummy-coded indicator for first generation status and use that as a predictor in our logistic regression model.
# Dummy code first_gengrad = grad |>mutate(is_firstgen =if_else(first_gen =="Yes", 1, 0) )# Fit modelglm.2=glm(got_degree ~1+ is_firstgen, data = grad, family =binomial(link ="logit"))# Evaluate first generation predictoraictab(cand.set =list(glm.0, glm.2),modnames =c("Intercept-Only", "Effect of First Gen"))
Given the data and candidate models, the model that includes first generation status in the model has more evidence. Since we are comparing to the intercept-only model in this output, We can also use the information in the residual deviance column to compute a pseudo-\(R^2\) value.
# Compute pseudo R2(2722.6-2662.1) /2722.6
[1] 0.02222141
The pseudo-\(R^2\) value of 0.022 is close to 0, which suggests that first generation status although statistically relevant, is not incredibly predictive of the log-odds (or odds or probability) of obtaining a degree. Next we turn to the fitted equation:
coef(glm.2)
(Intercept) is_firstgen
0.4995261 0.7666388
Based on this output, the fitted equation for the model is:
# Transform coefficients to odds metricexp(coef(glm.2))
(Intercept) is_firstgen
1.647940 2.152519
Interpreting these coefficients in the odds metric:
Non-first generation students’ predicted odds of obtaining a degree is 1.65. That is their probability of obtaining a degree is 1.64 times that of not obtaining a degree.
First generation students’ predicted odds of obtaining a degree is 2.15 times higher than non-first generation students’ odds of obtaining a degree.
To determine first generation students’ odds of obtaining a degree, we can either substitute 1 into the transformed fitted equation:
# Prob non-first gen studentsexp(0.50) / (1+exp(0.50))
[1] 0.6224593
# Prob first gen studentsexp(0.50+0.77) / (1+exp(0.50+0.77))
[1] 0.7807427
In the probability metric we just compute the predicted probabilities and report/compare them. There is no easy conversion of the slope coefficient to interpret how much higher the probability of obtaining a degree for first generation students is than for non-first generation students.
Evaluating Assumptions
When the only predictor in a logistic model is categorical, the only thing we need to pay attention to is whether the average residual for each level of the predictor is close to 0. We can again use the binned_residuals() function to evaluate this. When the predictor is categorical, the binning will be done on the levels of the predictor.
# Obtain average fitted values and average residualsout.2=binned_residuals(glm.2)# View data frameas.data.frame(out.2)
Figure 1: Binned residuals versus the binned fitted values for the model that includes the effect of first generation status to predict the log-odds of obtaining a degree.
Here we see the average residual (ybar) for both groups is near zero. This satisfies the linearity assumption. If you examined the binned residual plot, you would also see this, albeit in a graphical form.
The results from glm.2 indicated that there were differences between first and non-first generation students in the probability of obtaining a degree. Based on this model’s result, we found that the predicted probability of obtaining a degre for first generation students was 0.780 while that for non-first generation students was 0.622. Does this difference persist after controlling for other covariates?
To examine this, we want to fit a set of models that systematically include potential covariates along with first generation status. Our strategy for this is to start with the most important covariate. We can compare the model that includes first generation status and this covariate to a model that just includes first generation status. If the evidence indicates that the model with only first generation status is important we are done. If the evidence points toward the model that also includes the most important covariate, then we will continue by comparing that model to one that includes first generation status and the two most important covariates. We will continue with these comparisons until we adopt a final model or models.
To determine the order of importance, we can compute the correlations between each covariate and the dummy-coded outcome.
grad |>select(got_degree, act, scholarship, ap_courses,is_nontrad) |>correlate()
The rank ordering of covariates (based on the absolute value of the correlation coefficients) will be:
ACT scores (\(r = 0.195\), most important)
Number of AP courses (\(r = 0.149\))
Scholarship amount (\(r = 0.142\))
Non-traditional status (\(r = -0.084\))
Non-Linear Effect of ACT
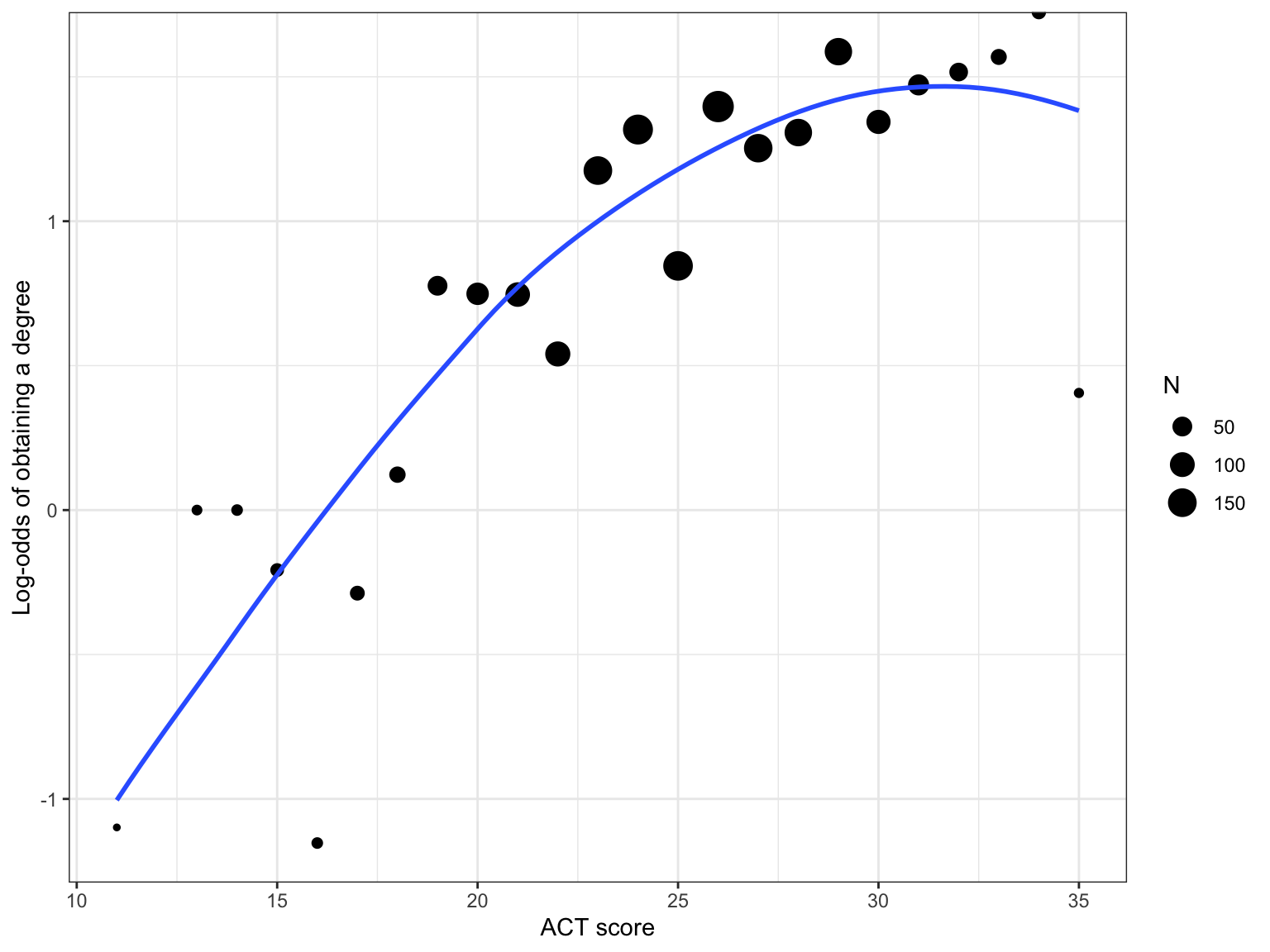
To begin the analysis, we will include ACT scores as a covariate in the model. Since the act variable is continuous, we need to use the “correct” functional form when we include it in the model. In the previous set of notes, we saw some misfit when we examined the binned residual plot for the logistic regression model that included ACT as a predictor of the probability of obtaining a degree. One possibility is that this may be because the effect of ACT on these probabilities is non-linear. To examine this, we can plot the empirical log-odds of obtaining a degree versus ACT scores, and examine the functional form of the relationship.
Code
# Obtain the log-odds who obtain a degree for each ACT scoreprop_grad = grad |>group_by(act, degree) |>summarize(N =n()) |>mutate(Prop = N /sum (N) ) |>ungroup() |>filter(degree =="Yes") |>mutate(Odds = Prop / (1- Prop),Logits =log(Odds) )# Scatterplotggplot(data = prop_grad, aes(x = act, y = Logits)) +geom_point(aes(size = N)) +geom_smooth(aes(weight = N), method ="loess", se =FALSE) +theme_bw() +xlab("ACT score") +ylab("Log-odds of obtaining a degree")
Figure 2: Log-odds of obtaining a degree conditional on ACT score. Size of the dot is proportional to sample size. The loess smoother is also weighted based on the sample size.
This suggests a non-linear relationship between ACT score and the log-odds of obtaining a degree. Using the Rule-of-the-Bulge, we can try to linearize this relationship by:
Including a quadratic effect of ACT; or
Log-transforming the ACT variable.
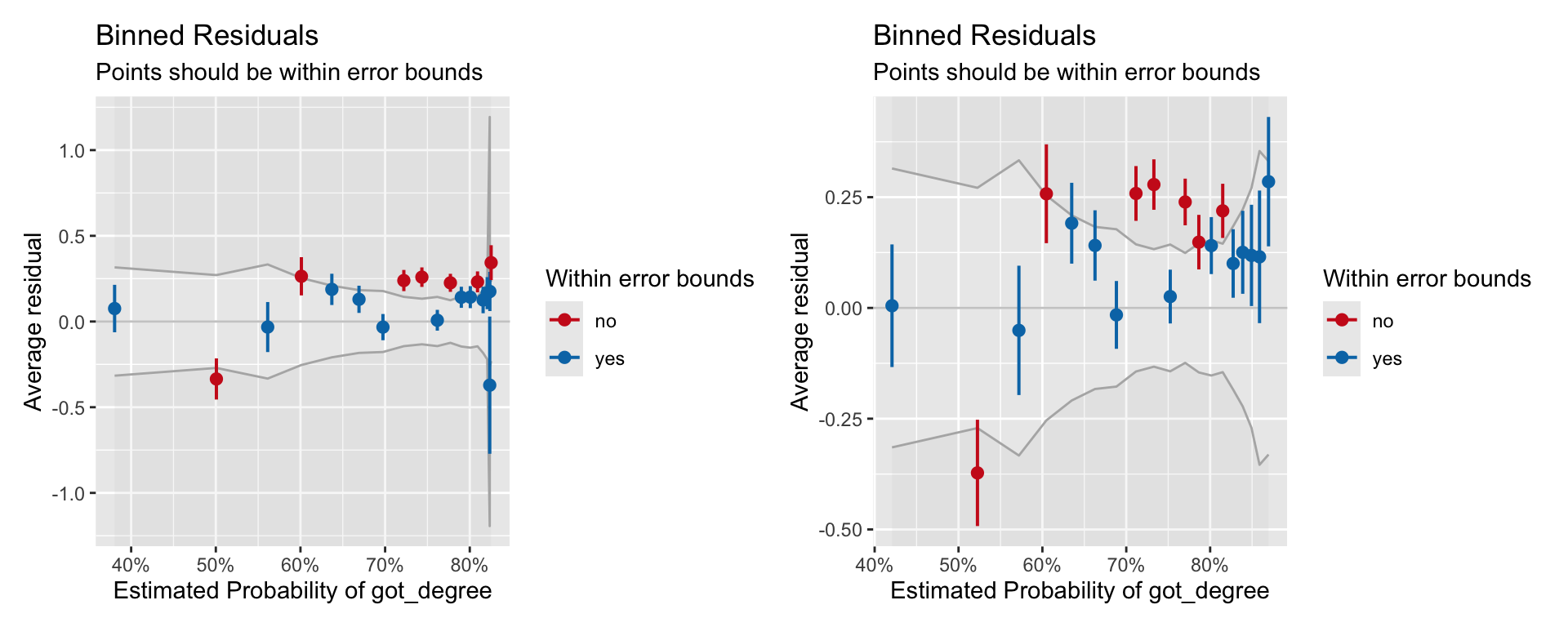
# Fit non-linear modelsglm.1_quad =glm(got_degree ~1+ act +I(act^2), data = grad, family =binomial(link ="logit"))glm.1_log =glm(got_degree ~1+log(act), data = grad, family =binomial(link ="logit"))# Obtain binned residualsout.1_quad =binned_residuals(glm.1_quad)out.1_log =binned_residuals(glm.1_log)# Binned residual plotsplot(out.1_quad) |plot(out.1_log)
Figure 3: Binned residual plots for two models that include non-linear effects of ACT. The quadratic model (LEFT) and the log-linear model (RIGHT).
The binned residuals show slight misfit to both the log-linear model and the quadratic model. We also examine the empirical support via information criteria.
Here the most empirically supported model (given the data and the candidate models) is the quadratic model, although there is also a great deal of support for the log-linear model. I would probably adopt the log-linear model based on its simplicity and the theoretical rationale that I would not expect the probability of graduating to be smaller for high ACT values. But, for pedagogical purposes, we will look at and interpret the output for both models.
Quadratic Effect of ACT
We will start our interpretation by examining the coef() output.
Since this is an interaction model, we interpret the effect of ACT as: The effect of ACT on the log-odds of obtaining a degree depends on ACT. (We could also graph this effect if we were interested in the effect of ACT on the log-odds of obtaining a degree.)
Transforming the fitted equation to the odds metric:
Because changing ACT now impacts two exponent terms, one of which includes the quadratic of ACT, it is super essential that we create a plot to interpret the effects of ACT on the odds of obtaining a degree.
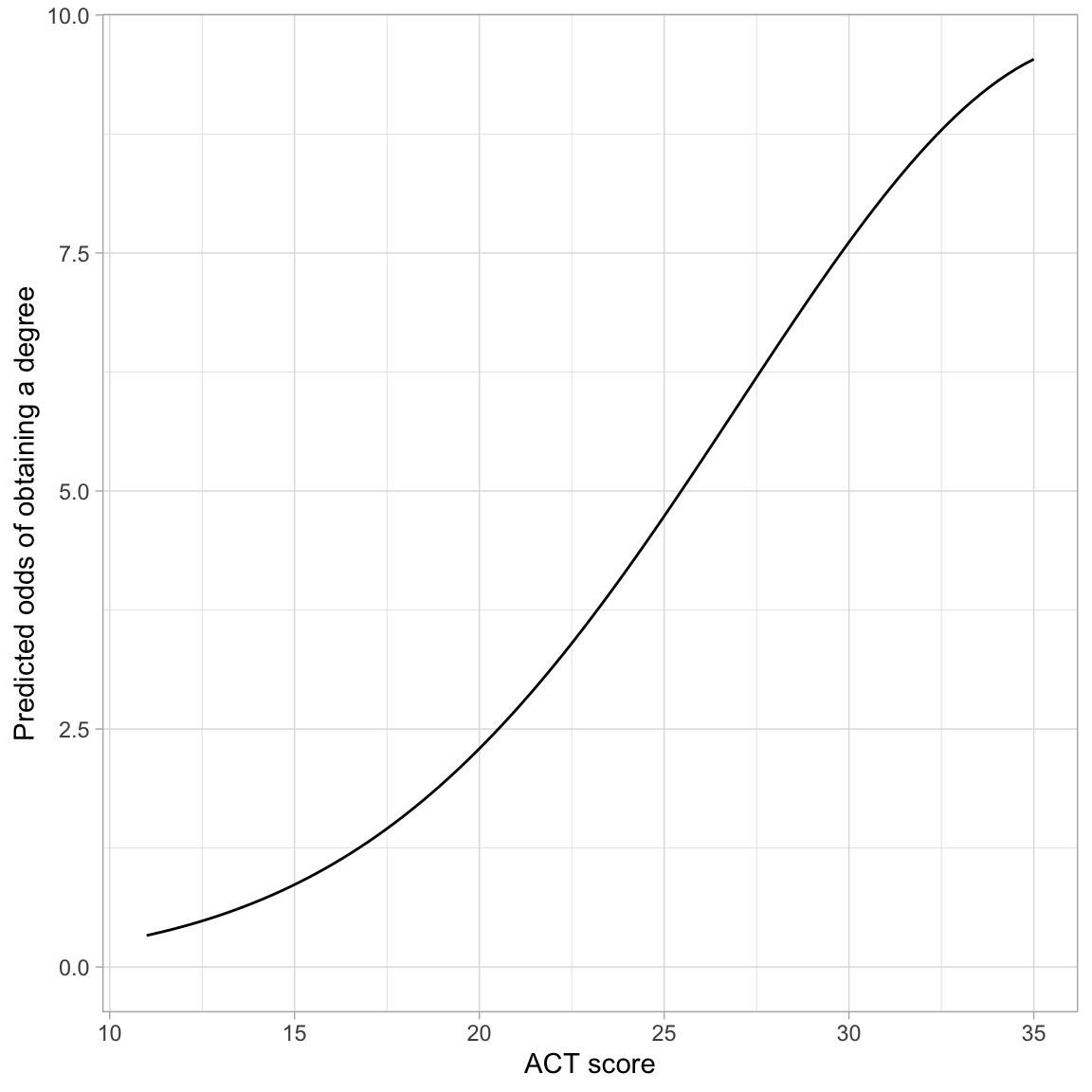
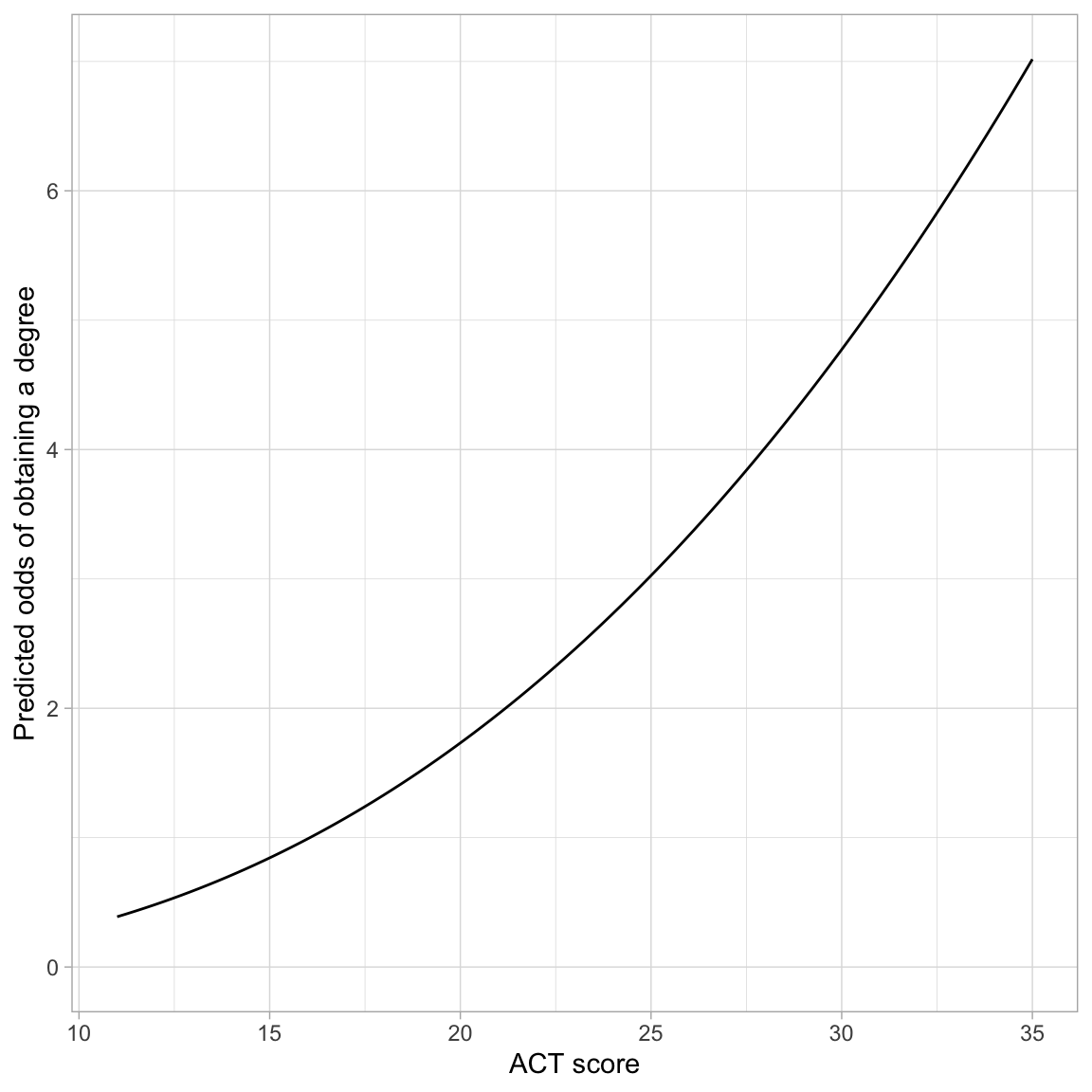
# Plot the fitted equationggplot(data = grad, aes(x = act, y = got_degree)) +geom_point(alpha =0) +geom_function(fun =function(x) {exp(-4.57+0.37*x -0.005*x^2)} ) +theme_light() +xlab("ACT score") +ylab("Predicted odds of obtaining a degree")
Figure 4: Predicted odds of obtaining a degree as a function of ACT score.
The odds curve is somewhat “S”-shaped (although it is not constrained between 0 and 1 like the probability curve). This is because of the quadratic effect of ACT. The overall trend is one of exponential growth, although the rate-of-change is not constant within this curve. The most rapid change in the odds of obtaining a degree occurs at ACT scores between 20 and 30.
Finally, we could also transform the equation into the probability metric. The fitted equation is:
Again, it is worthwhile to create a plot to interpret the effects of ACT on the probability of obtaining a degree.
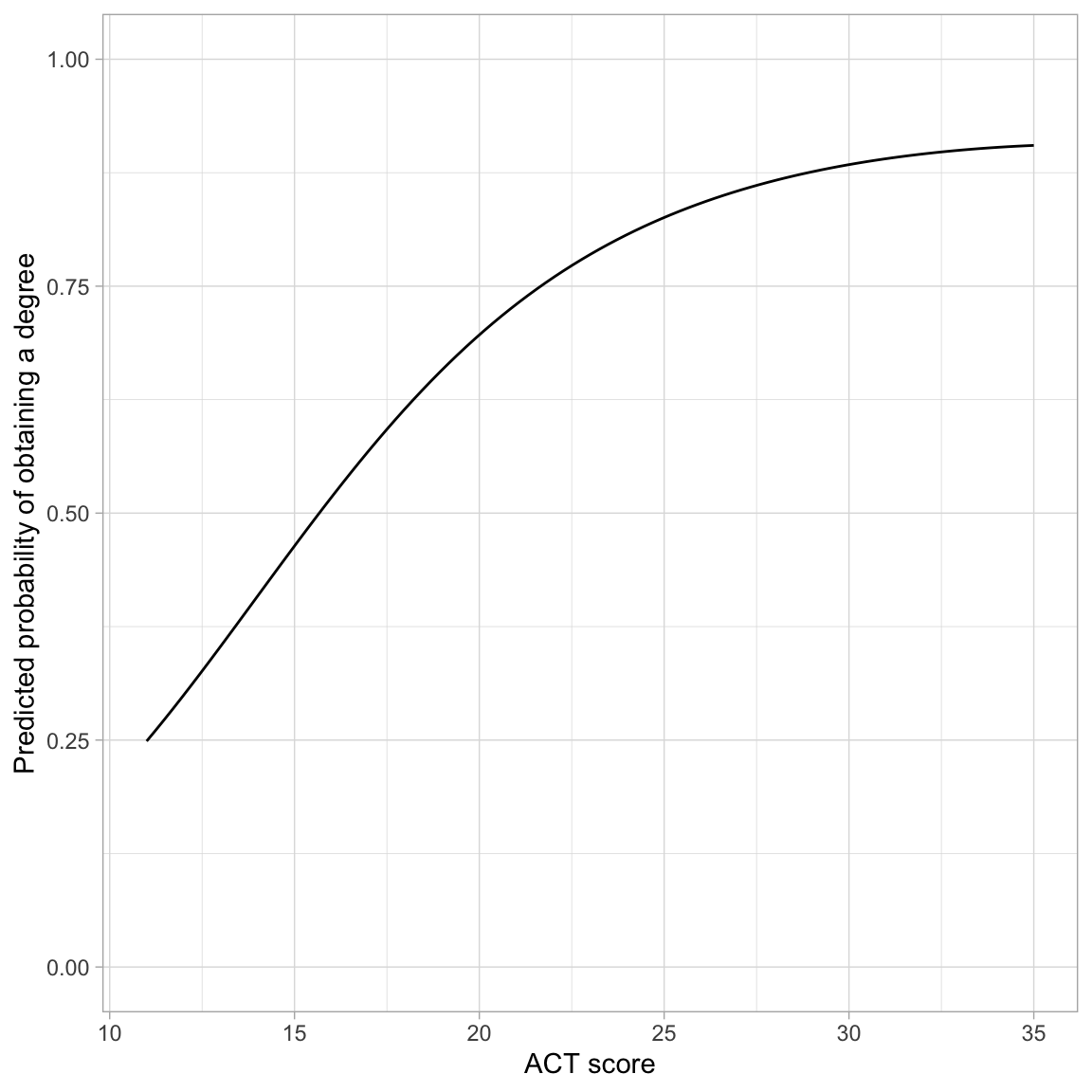
# Plot the fitted equationggplot(data = grad, aes(x = act, y = got_degree)) +geom_point(alpha =0) +geom_function(fun =function(x) {exp(-4.57+0.37*x -0.005*x^2) / (1+exp(-4.57+0.37*x -0.005*x^2))} ) +theme_light() +xlab("ACT score") +ylab("Predicted probability of obtaining a degree")
Figure 5: Predicted probability of obtaining a degree as a function of ACT score.
The probability curve is “S”-shaped and constrained between 0 and 1. The left-hand side of the “S” is compressed, probably due to the range of ACT scores. ACT has the largest effect on the probability of obtaining a degree for scores less than 25, and then the effect begins to plateau (although it is still growing as the logistic curve is monotonic).
Log-Linear Effect of ACT
We will again start our interpretation by examining the coef() output.
It is again easier to interpret the effects of ACT on the odds of obtaining a degree by creating a plot .
# Plot the fitted equationggplot(data = grad, aes(x = act, y = got_degree)) +geom_point(alpha =0) +geom_function(fun =function(x) {exp(-6.94+2.50*log(x))} ) +theme_light() +xlab("ACT score") +ylab("Predicted odds of obtaining a degree")
Figure 6: Predicted odds of obtaining a degree as a function of ACT score.
The effect of ACT on the probability of obtaining a degree is positive and non-linear (exponential growth). The predicted odds of obtaining a degree increases exponentially for higher ACT scores.
Finally, we could also transform the equation into the probability metric. The fitted equation is:
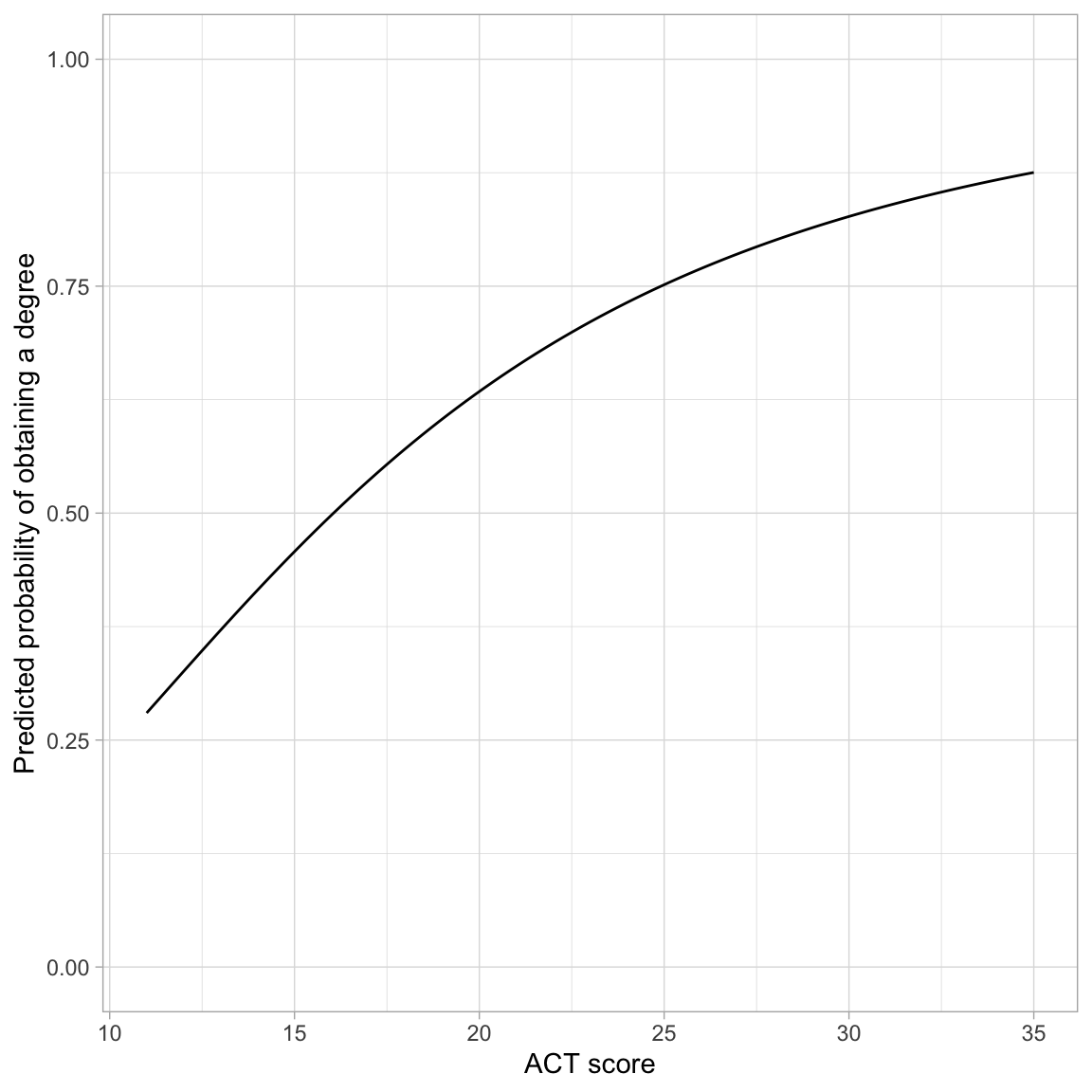
Again, it is worthwhile to create a plot to interpret the effects of ACT on the probability of obtaining a degree.
# Plot the fitted equationggplot(data = grad, aes(x = act, y = got_degree)) +geom_point(alpha =0) +geom_function(fun =function(x) {exp(-6.94+2.50*log(x)) / (1+exp(-6.94+2.50*log(x)))} ) +theme_light() +xlab("ACT score") +ylab("Predicted probability of obtaining a degree")
Figure 7: Predicted probability of obtaining a degree as a function of ACT score.
The effect of ACT on the probability of obtaining a degree is positive and non-linear. ACT has a larger effect on the probability of obtaining a degree for smaller ACT scores and this effect, while still positive, diminishes for higher ACT scores.
Once you include non-linear effects in the model, always create a plot of the fitted equation to try and interpret odds or probabilities.
Adding Covariates: Main Effects Models
Now that we have settled on a functional form for the effect of ACT, we can include it as a covariate in a model with first generation status. Including covariates in the logistic model is done the same way as for lm() models. We fit that model with the following syntax:
# Fit main effects modelglm.3=glm(got_degree ~1+ is_firstgen +log(act), data = grad, family =binomial(link ="logit"))
To evaluate this model, and to begin to provide an answer for our research question, we will examine the model evidence comparing this model to both the baseline model (intercept-only) and the model that included the main-effect of first generation status.
# Model evidenceaictab(cand.set =list(glm.0, glm.2, glm.3),modnames =c("Intercept-Only", "First Gen.", "First Gen. + ACT"))
Given the data and candidate models fitted, the empirical evidence overwhelmingly supports including both ACT scores and first generation status in the model. Adopting this model, we next look at the coefficients:
Using the logit/log-odds metric, we interpret the coefficients as:
Non-first generations students with an ACT score of 1 have a predicted log-odds of graduating of \(-5.91\).
Each 1% difference in ACT score is associated with a difference of 0.02 in the predicted log-odds of graduating, after controlling for first generation status.
First generation college students, have a predicted log-odds of graduating that is 0.51 higher than students who are not first generation students, after controlling for differences in ACT scores.
Back-Transforming to Odds
If we back-transform the coefficients to facilitate interpretations using the odds metric, the fitted equation is:
We can interpret the intercept and the effect of first generation status directly:
Non-first generations students with an ACT score of 1 have a predicted odds of graduating of \(e^{-5.91}=.003\).
First generation college students, have a predicted odds of graduating that is \(e^{0.51}=1.66\) times higher than that for non-first generations students, after controlling for differences in ACT scores.
Each one-point difference in ACT score is associated with improving the odds of graduating 1.09 times, on average, after controlling for whether or not the students are first generation college students.
While it is not pertinent to the research question, if you wanted to interpret the effect of ACT, you could plot the fitted model. As always with main effects models, we find the fitted equation for first generation and non-first generation students, and plot the two curves separately using multiple geom_function() layers.
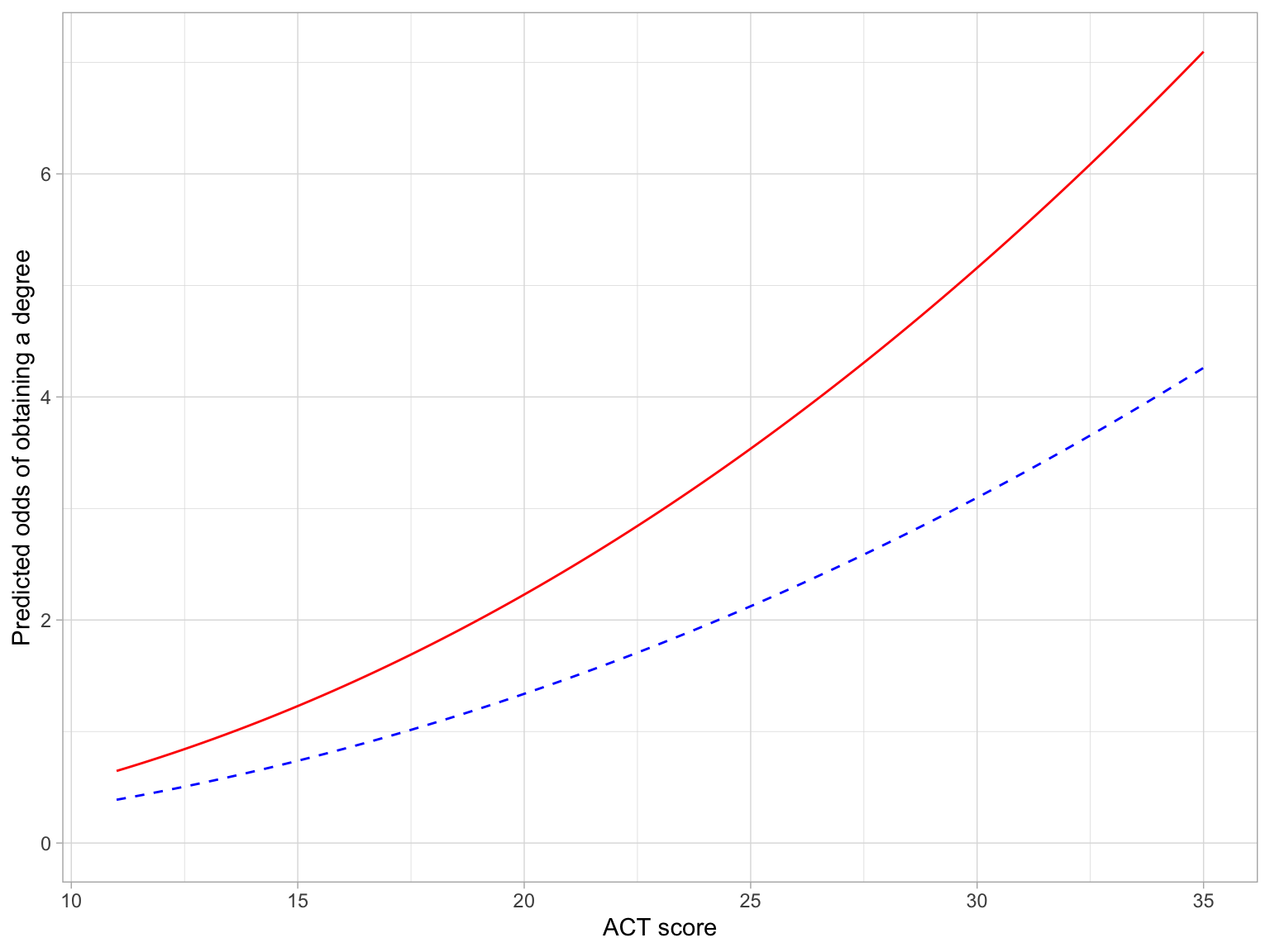
# Plot the fitted equationggplot(data = grad, aes(x = act, y = got_degree)) +geom_point(alpha =0) +# Non-first generation studentsgeom_function(fun =function(x) {exp(-5.91+2.07*log(x))},linetype ="dashed",color ="blue" ) +# First generation studentsgeom_function(fun =function(x) {exp(-5.40+2.07*log(x))},linetype ="solid",color ="red" )+theme_light() +xlab("ACT score") +ylab("Predicted odds of obtaining a degree")
Figure 8: Predicted odds of obtaining a degree as a function of ACT score first generation (solid, red line) and non-first generation (dashed, blue line) students.
Here we see that the odds of graduating increase exponentially at higher ACT scores for both first generation and non-first generation students, on average. This rate of increase, however, is higher for first generation students. Moreover, first generation students have higher odds of graduating than non-first generation students, regardless of ACT score.
Back-Transforming to Probability
Again, while not related to the research question, we can also plot the predicted probability of graduating as a function of ACT score. Algebraically manipulating the fitted equation,
We can then produce the fitted equations for non-first generation and first generation students by substituting either 0 or 1, respectively, into the firstgen variable. These equations are:
We can include each of these in a geom_function() layer in our plot.
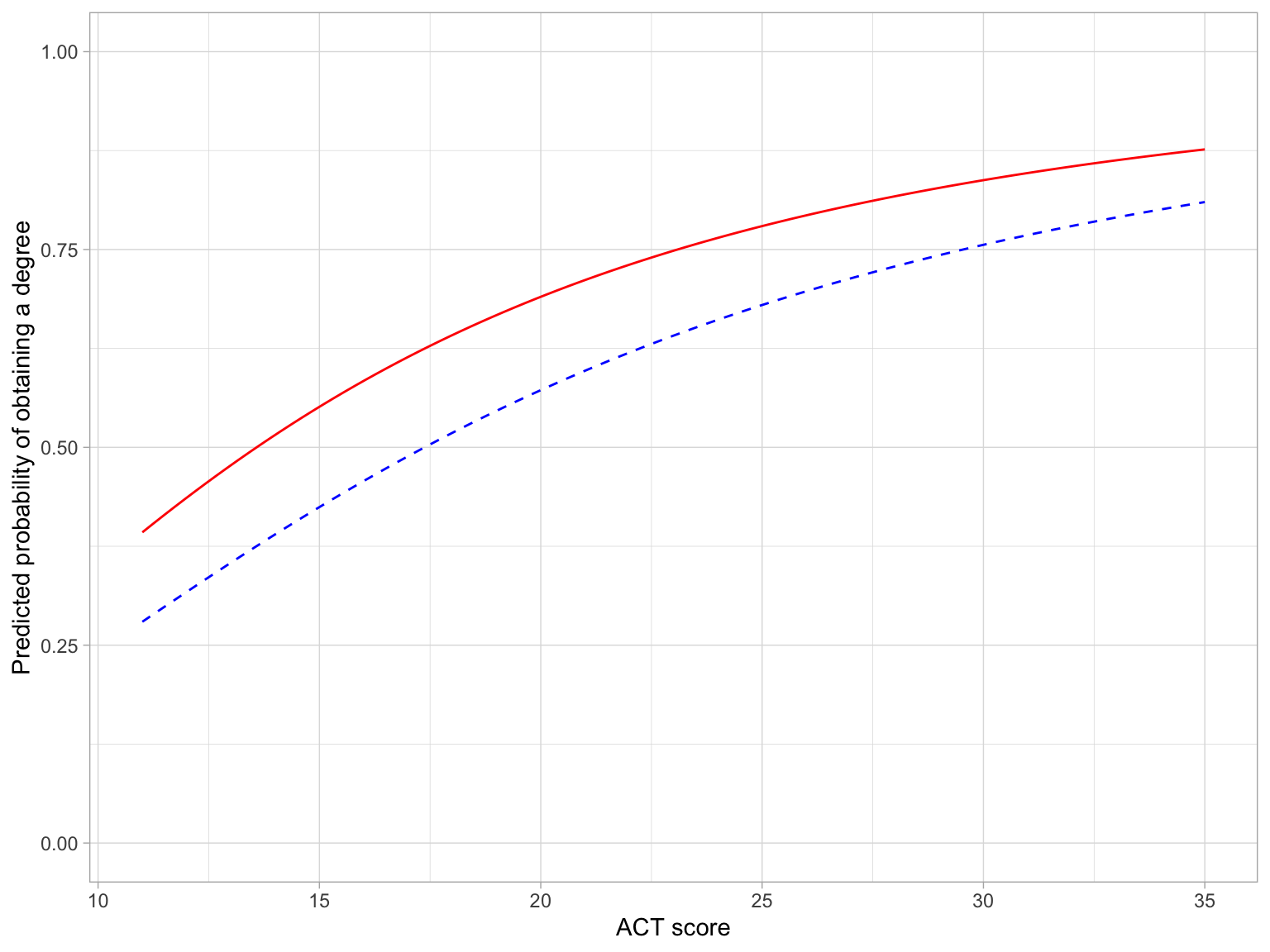
# Plot the fitted equationsggplot(data = grad, aes(x = act, y = got_degree)) +geom_point(alpha =0) +# Non-first generation studentsgeom_function(fun =function(x) {exp(-5.91+2.07*log(x)) / (1+exp(-5.91+2.07*log(x)))},linetype ="dashed",color ="blue" ) +# First generation studentsgeom_function(fun =function(x) {exp(-5.40+2.07*log(x)) / (1+exp(-5.40+2.07*log(x)))},linetype ="solid",color ="red" ) +theme_light() +xlab("ACT score") +ylab("Predicted probability of obtaining a degree") +ylim(0, 1)
Figure 9: Predicted probabilities of obtaining a degree as a function of ACT score first generation (solid, red line) and non-first generation (dashed, blue line) students.
Here we see that the probability of graduatingobtaining a degree is positively associated with ACT score for both first generation and non-first generation students. The magnitude of the effect of ACT depends on ACT score for both groups. Although first generation students have higher probability of obtaining a degree than non-first generation students regardless of ACT score, the magnitude of this difference decreases at higher ACT scores.
Including Other Covariates in the Model
We will now fit a series of models that systematically include the remainder of the potential covariates based on their importance. We will have to adopt the correct functional form for ALL continuous variables by examining the plots of the data and residuals from potential transformations. (NOTE: This work is not shown here, but you should undertake it.)
The second covariate we will include is the number of AP courses taken. We use a log-transformation of this variable given its curvilinear status with the empirical log-odds of obtaining a degree. Because it has values of 0, we also add 1 before log-transforming.
# Log-linear effect of AP coursesglm.4=glm(got_degree ~1+ is_firstgen +log(act) +log(ap_courses +1), data = grad, family =binomial(link ="logit"))
Next, we include scholarship amount into the model. An examination of the empirical log-odds of obtaining a degree versus scholarship amount also suggested a curvilinear relationship. We adopt a log-linear model, again adding 1 prior to transforming using the logarithm since there are 0s in the variable.
# Effect of scholarshipglm.5=glm(got_degree ~1+ is_firstgen +log(act) +log(ap_courses +1) +log(scholarship +1), data = grad, family =binomial(link ="logit"))
Finally, we include the effect of non-traditional student status. Since it is a dummy-coded variable, we do not have to worry about the functional form. However, since we don’t know the functional form we need for scholarship amount, we will consider both when we include this covariate.
# Effect of non-traditional studentglm.6=glm(got_degree ~1+ is_firstgen +log(act) +log(ap_courses +1) +log(scholarship +1) + is_nontrad, data = grad, family =binomial(link ="logit"))
Now we will use information criteria to select from these potential models.
Here the empirical evidence supports the model that includes all the covariates. Examining the binned residuals (not shown), the model does not seem adequate. Next we turn to evaluating potential interaction terms to see if that improves the residual fit.
Interaction Between ACT Score and First Generation Status
Since this is an exploratory analysis, we should only fit first-order interactions, and only with the focal predictor (i.e., first generation status). We will adopt the same modeling strategy as before, building up interaction terms in the order of covariate importance.
While the model that includes the interaction between first generation status and ACT has the most empirical evidence (given the data and candidate models), there is some degree of empirical evidence for almost all of the interaction models fitted. Evaluating the binned residuals (not shown) there is a reasonable (and roughly equal) degree of residual fit for glm.7, glm.8, and glm.10. Given this, the information from the AICc table, and the rule of parsimony, we will adopt glm.7.
We will plot these two equations using the probability metric.
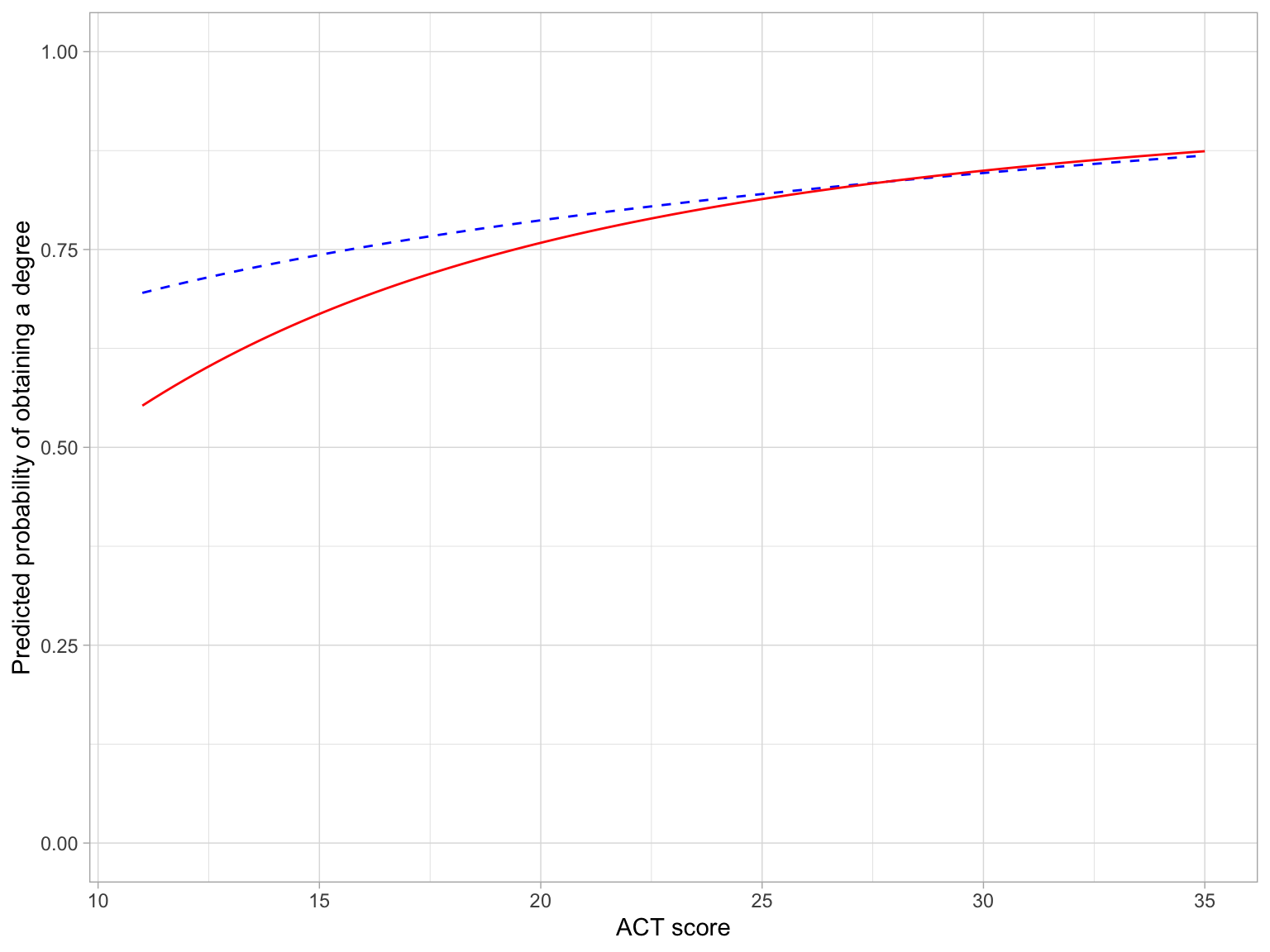
# Plot the fitted equationsggplot(data = grad, aes(x = act, y = got_degree)) +geom_point(alpha =0) +# Non-first generation studentsgeom_function(fun =function(x) {exp(-0.66+0.54*log(x)) / (1+exp(-0.66+0.5*log(x)))},linetype ="dashed",color ="blue" ) +# First generation studentsgeom_function(fun =function(x) {exp(-3.70+1.64*log(x)) / (1+exp(-3.70+1.647*log(x)))},linetype ="solid",color ="red" ) +theme_light() +xlab("ACT score") +ylab("Predicted probability of obtaining a degree") +ylim(0, 1)
Figure 10: Predicted probability of obtaining a degree as a function of ACT score for first generation (solid, red line) and non-first generation (dashed, blue line) who ar 18 years old at the time of enrollment. The effects for the number of AP credits and scholarship amount (in thousands of dollars) were controlled by setting them to their mean values of 3.28 and 0.18, respectively.
Because our research question is about the effect of first generation status, we will focus the interpretation from this plot on that effect.
Here we see that first generation status and ACT score interact on the probability of obtaining a degree. For students with lower ACT scores the probability of obtaining a degree is smaller for first generation students than for non-first generation students. However, this difference diminishes for students with higher ACT scores.
Presenting a Table of Logistic Regression Results
We can present selected fitted models from the analysis in a table similar to those we have created for OLS models. In this analysis I would present glm.0, glm.2, glm.3, glm.6, and glm.7. Note that we do not have to present ALL the models we fitted in the table, only those that tell a coherent story about the analysis. (If you are worried about transparency, you can always link to our script file or RMD document which includes all the models fitted in the paper, or include some prose that indicates there were other models fitted.) For these models, we want to report:
Coefficients and SEs
Residual Deviance
AICc values (This can be computed from the df and residual deviances, but since it was our main criterion for model selection, it is a good idea to report it!)
Pseudo-\(R^2\) values
Here is a table I might present for this analysis.
Code
# Create the tablehtmlreg(l =list(glm.0, glm.2, glm.3, glm.6, glm.7),stars =numeric(0), #No p-value starsdigits =2,padding =20, #Add space around columns (you may need to adjust this via trial-and-error)custom.model.names =c("Model A", "Model B", "Model C", "Model D", "Model E"),custom.coef.names =c("Intercept", "First Generation", "ln(ACT Score)","ln(AP Courses + 1)", "ln(Scholarship Amount + 1)", "Non-Traditional Student","First Generation x ln(ACT Score)"),reorder.coef =c(2:7, 1), #Put intercept at bottom of tableinclude.aic =FALSE, #Omit AICinclude.bic =FALSE, #Omit BICinclude.nobs =FALSE, #Omit sample sizeinclude.loglik =FALSE, #Omit log-likelihoodcustom.gof.rows =list(AICc =c(AICc(glm.0), AICc(glm.2), AICc(glm.3), AICc(glm.6), AICc(glm.7)),R2 = (2722.5-c(NA, 2662.09, 2605.00, 2540.35, 2536.67)) /2722.5 ), # Add AICc valuesreorder.gof =c(3, 1, 2),caption =NULL,caption.above =TRUE, #Move caption above tableinner.rules =1, #Include line rule before model-level outputouter.rules =1 , #Include line rules around tablecustom.note ="The $R^2$ value is based on the proportion of reduced deviance from the intercept-only model (Model A)" )
Table 2: Five candidate models predicting variation in the log-odds of obtaining a degree. The first generation and non-traditional student predictors were dummy-coded.
Model A
Model B
Model C
Model D
Model E
First Generation
0.77
0.51
0.42
-3.04
(0.10)
(0.10)
(0.11)
(1.80)
ln(ACT Score)
2.07
1.11
0.54
(0.28)
(0.30)
(0.42)
ln(AP Courses + 1)
0.29
0.28
(0.06)
(0.06)
ln(Scholarship Amount + 1)
1.16
1.11
(0.26)
(0.26)
Non-Traditional Student
-0.84
-0.83
(0.33)
(0.33)
First Generation x ln(ACT Score)
1.10
(0.57)
Intercept
1.01
0.50
-5.91
-3.03
-1.25
(0.05)
(0.08)
(0.86)
(0.94)
(1.31)
Deviance
2722.55
2662.09
2605.00
2540.35
2536.67
AICc
2724.55
2666.09
2611.01
2552.39
2550.72
R2
0.02
0.04
0.07
0.07
The \(R^2\) value is based on the proportion of reduced deviance from the intercept-only model (Model A)
Pseudo-\(R^2\) values are commonly reported in applied research. Because there are many potential pseudo-\(R^2\) values, you should always indicate the method used to calculate this metric.
Footnotes
Another analyst might choose to use the non-traditional group or to show the effect by displaying both groups, perhaps in different panels.↩︎