11 Assumptions of the One-Sample t-Test
In this chapter you will learn about the assumptions that we need to make in order for the results of a one-sample t-test to be statistically valid.
11.1 Assumptions
Whether or not the results we obtain from the t-test are accurate depends on a set of statistical assumptions about the population. Remember that the t-value we use to compute the p-value is computed as:
where, , SD is the sample standard deviation, and n is the sample size. A critical part of this is that the formula we use to compute the standard error gives us a good estimation of the standard error. This, it turns out, is only true under a particular set of statistical assumptions.
If the assumptions are violated and the formula we used for the SE is wrong, that implies the t-value will be wrong because we used the wrong value in the denominator. And, if the t-value is incorrect, that means the p-value is also incorrect since it is based on the t-value. This would mean further that all of our inferences that we draw about the population mean are dubious, since these inferences are based on the p-value. Because of this, it is critical that we have some sense of whether these statistical assumptions we are making are valid.
For the one-sample t-test there are two statistical assumptions we make about the population:
- The distribution of values in the population is normally distributed.
- The values in the population are independent from each other.
For example, in the teen sleep case study we need to know that:
- If you took the hours of sleep measurements from every teen and plotted them, the distribution would be normally distributed.
- The hours of sleep measurements from every teen is independent from those of every other teen.
Unfortunately, we can never know for sure whether these assumptions are met since we do not have data from the entire population. Instead, we have to decide whether these assumptions seem tenable based on the sample of data we have.
11.1.1 Evaluating the Assumption of Normality
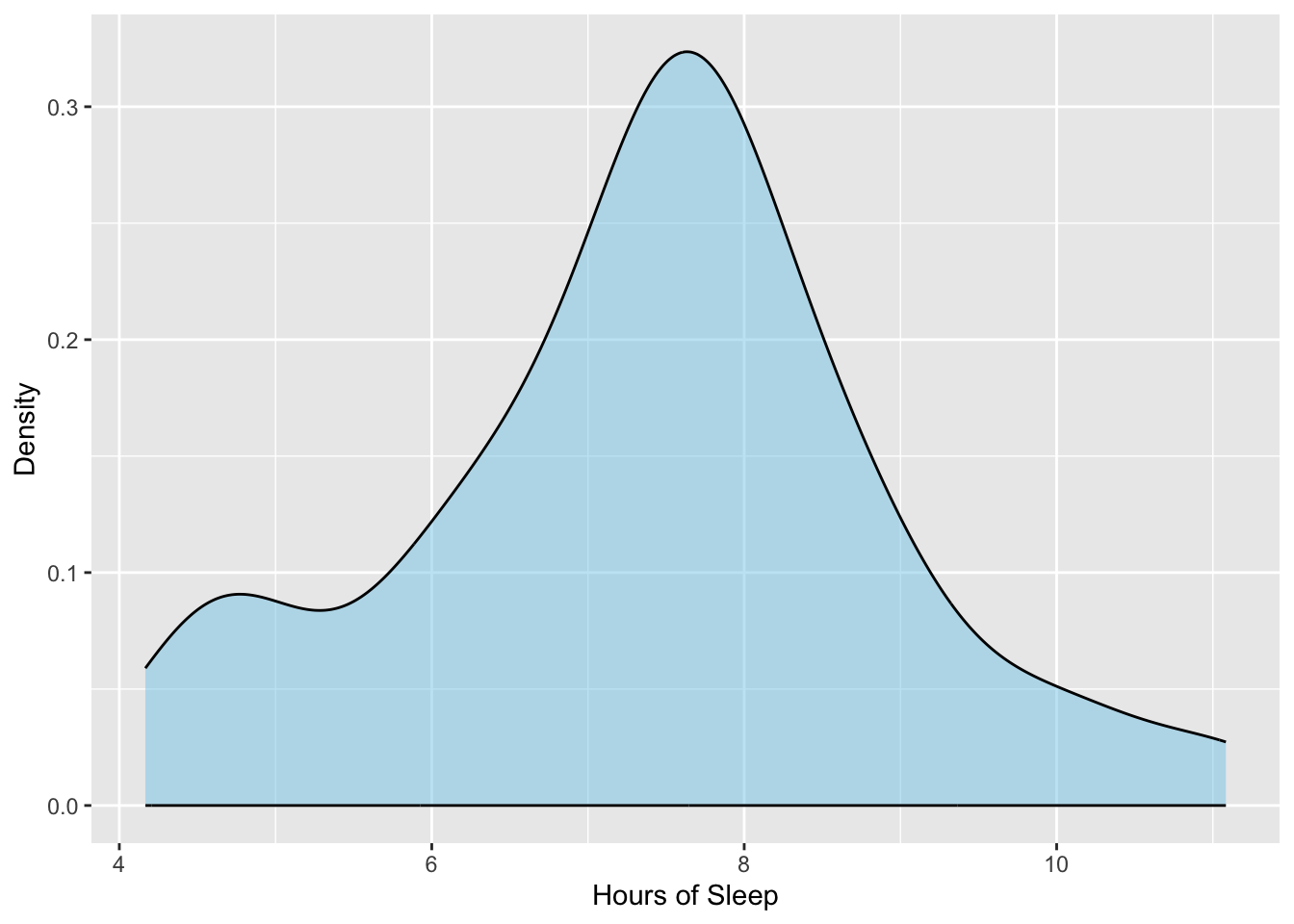
To evaluate the first assumption that the distribution of values in the population is normally distributed, we plot the sample data and then ask the question: Is this distribution close to normal? The density plot of the sample teen sleep data is shown in Figure 11.1.
The sample distribution looks symmetric, but perhaps not exactly normal. This is okay since the assumption is about whether the POPULATION distribution is normal, not whether the sample distribution is normal. We are only asking whether we believe that the population distribution is normal based on what we see in the sample distribution. To answer this question, we need some idea of what sample distributions of size 75 look like if they truly do come from a population that is normally distributed. Below are the distributions for five samples of size 75 that were actually drawn from a normal distribution.
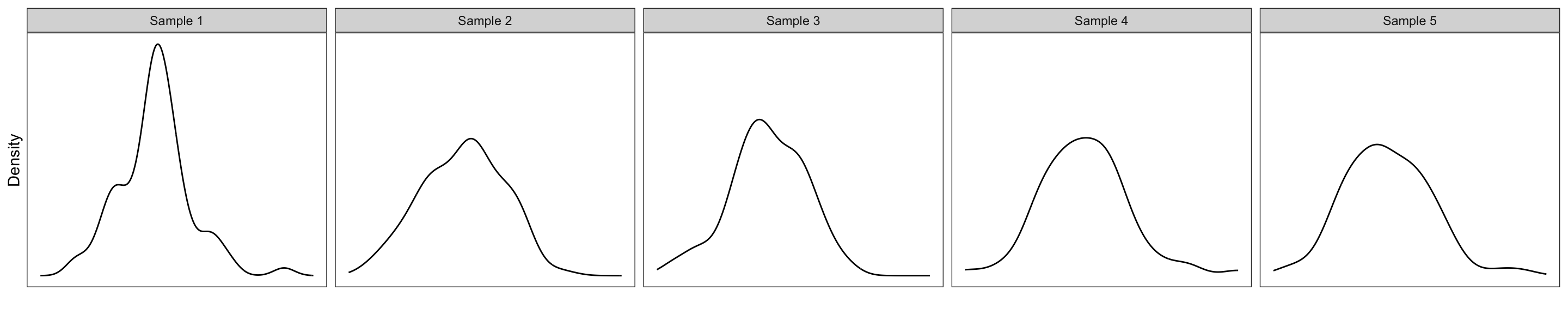
The density plots in Figure 11.2 suggest that the distribution for a sample that was actually drawn from a normal distribution does not necessarily look exactly normal. For example the plots for Sample 1 and Sample 3 look slightly right-skewed, while the plots for Samples 2, 4, and 5 look more symmetric. Some of the plots look more peaked (Samples 1 and 2) while others look thicker in the middle (Samples 4 and 5). All of this suggests that the sample doesn’t have to look perfectly normal for it to have been drawn from a population that is normal.
Looking back at the sample distribution of teen sleep measurements in Figure 11.1, it seems that this distribution is not so different from the distributions of the five other samples. This suggests that it too might have been drawn from a normally distributed population. In light of this, we would say:
The assumption of normality seems tenable given the distribution of the sample data.
11.1.1.1 Sample Size and the Assumption of Normality
How different would the sample distribution have to look in order for us to conclude that the assumption of normality was not tenable given the distribution of the sample data? This is a difficult question to answer without other statistical tools.1 One tool that we rely on a great deal is something called the Central Limit Theorem (CLT). This theorem basically says that if the sample size of your data is over 30 that it doesn’t matter if the normality assumption is met, the p-value will not be impacted if the population is not normal.
In our example the sample size is 75. This means that it doesn’t matter if the population is normal or not—the CLT basically says that we can assume that the p-value is not impacted by any deviation in the population distribution from normality. This is good news as it means we don’t have to guess whether or not our sample distribution of teen sleep measurements actually comes from a population that is normally distributed.
11.1.2 Evaluating the Independence Assumption
The definition of independence relies on formal mathematics. Loosely speaking a set of observations is independent if knowing the value for one observation in the distribution conveys no information about the value for any other observation in the same distribution. If observations are not independent, we say they are dependent or correlated.
To evaluate the independence assumption we need to know something about the the study design, in particular how the data were collected. Using random chance to select the sample data (random sampling) will guarantee independence of the observations. There are also a few times that we can ascertain that the independence assumption would be violated. These instances are also a function of the data collection process. One such instance common to social science research is when the observations (i.e., cases, subjects) are collected within a physical or spatial proximity to one another. For example, this is typically the case when a researcher gathers a convenience sample based on location, such as sampling students from the same school. Another violation of independence occurs when observations are collected over time (longitudinally), especially when the observations are repeated measures from the same subjects.
Independence is often difficult to ascertain, and its tenability is made via a logical argument. In the teen sleep case study, for example, the study design did not employ random sampling—the participants volunteered to be a part of the study—so we can not guarantee independence that way. (If a study uses random sampling in the data collection, it will say this directly in the paper.) On the other hand, all the participants did come from the same school district. This may violate the independence assumption since the teens in the study are all from the area (i.e., there was some degree of spatial proximity that influenced the data collection process).
The violation of independence is, however, not clear cut. The big question is does knowing that one teen’s sleep duration convey any information about any other teen’s sleep duration? If for example all the teens came from the same family this would likely be the case since teens in a family are often similar sleep schedules. It is less likely that this is a case for teens in the same school district. Because of this, we could argue that the independence assumption seems tenable.
FYI
Because the tenability of the independence assumption is made via a logical argument, outside the use of random sampling to collect the data, different scholars might disagree about whether this assumption is tenable. In this class, and in your own work, you need to lay out the argument for why you think the independence assumption is reasonable or not.
Exercises: Your Turn
- In the continuous assessment case study from Chapter 10, we evaluated whether, on average, Ethiopian primary school teachers agree/disagree with the statement that they assess students’ prior knowledge. The histogram of the 30 teachers’ responses is shown below. Based on this plot and the sample size, do you believe the normality assumption is tenable?
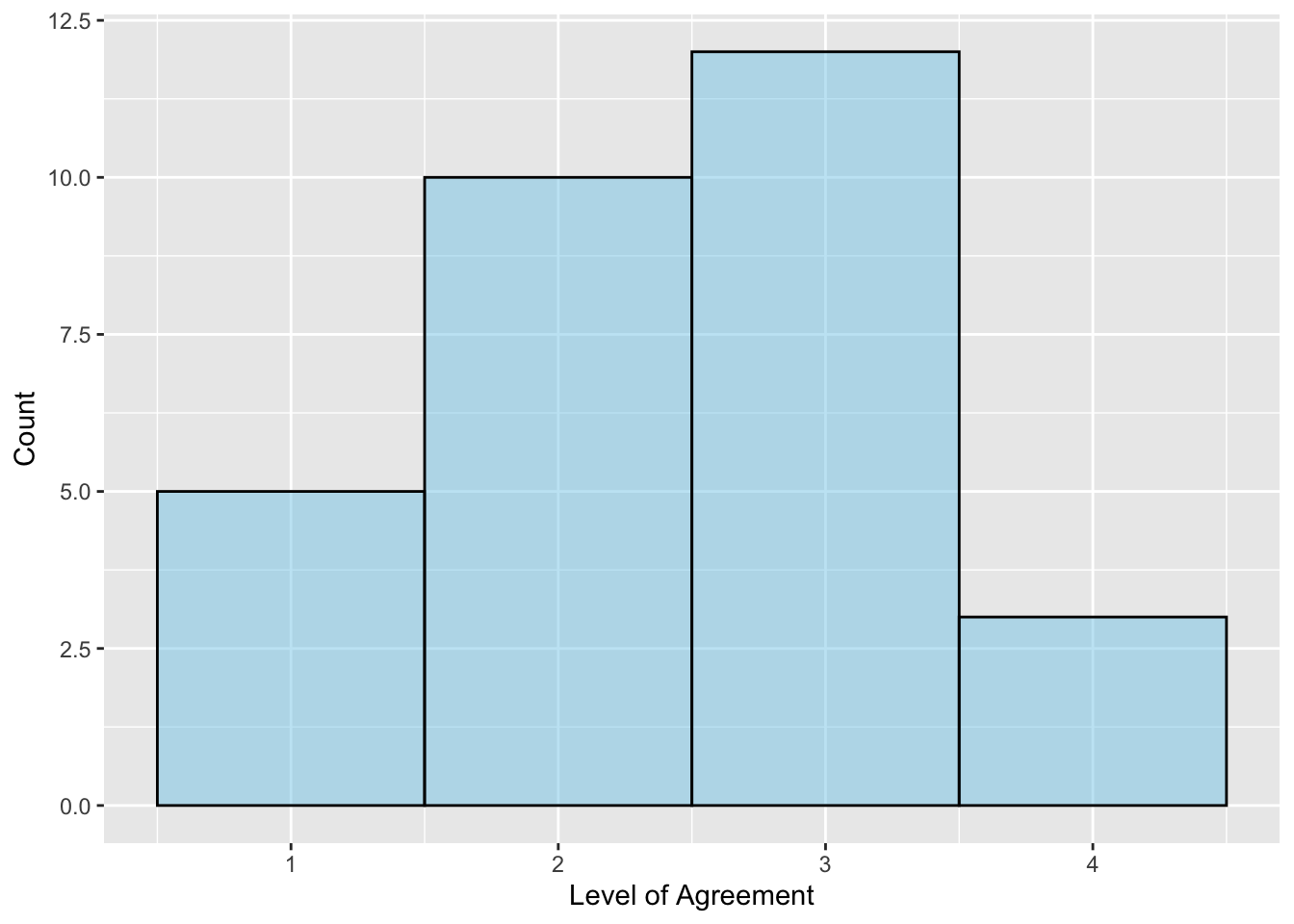
- Based on the data collection process described in the data codebook, do you believe the independence assumption is tenable?
- In the house prices case study from Chapter 10, we evaluated whether, on average, houses near the University of Minnesota campus are more expensive than $322.46k (the average price of a single-family house in Minneapolis as of May 2023). The histogram of the 15 sample house prices is shown below. Based on this plot and the sample size, do you believe the normality assumption is tenable?
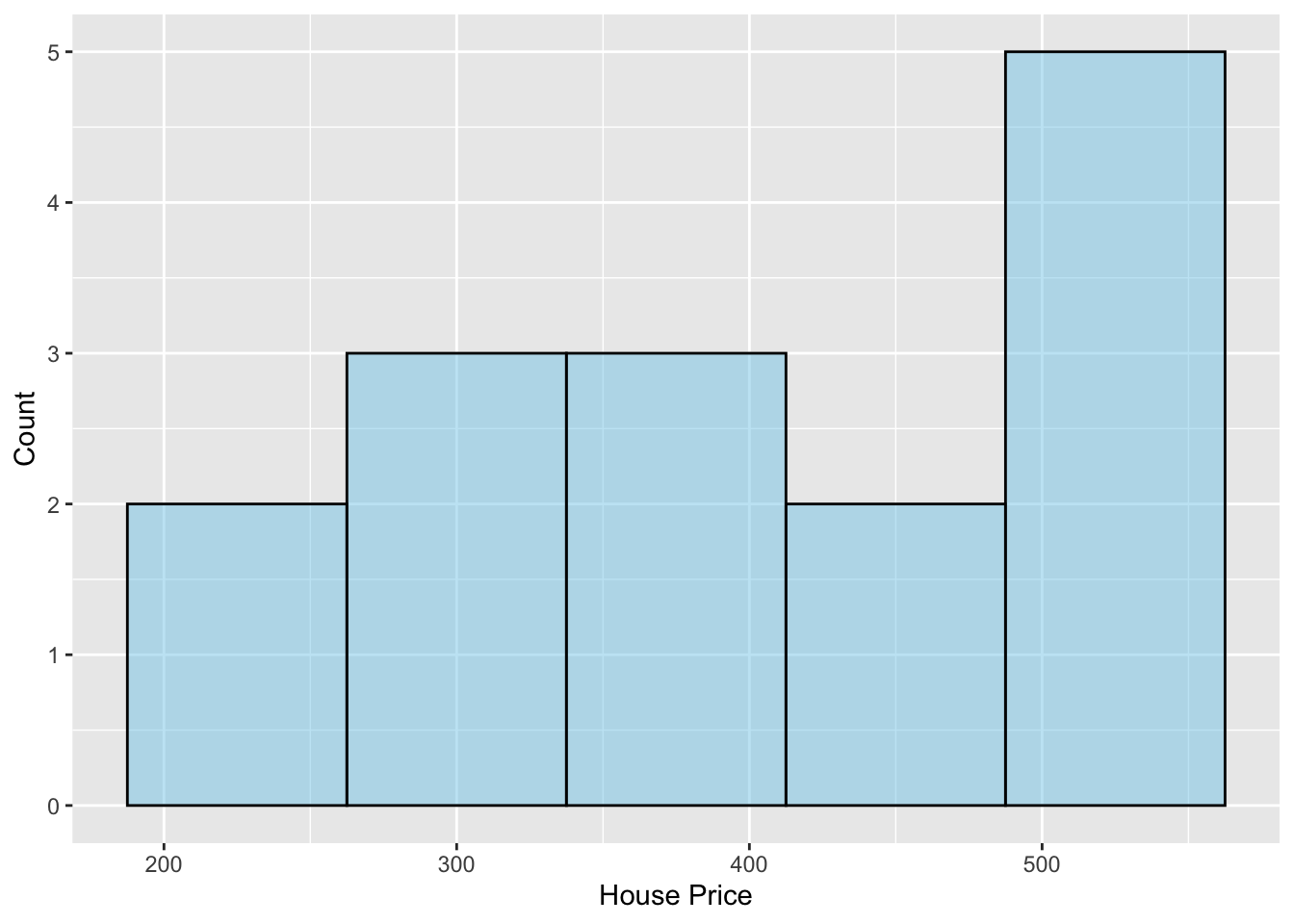
- Based on the data collection process described in the data codebook, do you believe the independence assumption is tenable?
11.2 References
If you go on and take EPsy 8251, you will learn about some of these tools.↩︎