In this chapter, you will learn about how to include categorical predictors with more than two categories in the regression model. To do so, we will use the pew.csv data to examine whether American’s news knowledge differs based on the source of their news. To begin, we will load several libraries and import the data into an object called pew.
PROTIP
The tidyverse library is a meta-package that includes dplyr, forcats, ggplot2, purrr, readr, stringr, tibble, and tidyr. Loading tidyverse allows you to use all of the functionality in these other packages without having to load eight different packages.
# Load librarieslibrary(broom)library(corrr)library(ggridges)library(patchwork)library(tidyverse)# Read in datapew =read_csv(file ="https://raw.githubusercontent.com/zief0002/modeling/main/data/pew.csv")# View datapew
To begin, as always, we will plot the marginal distributions of news knowledge (knowledge) and new source (news_source).
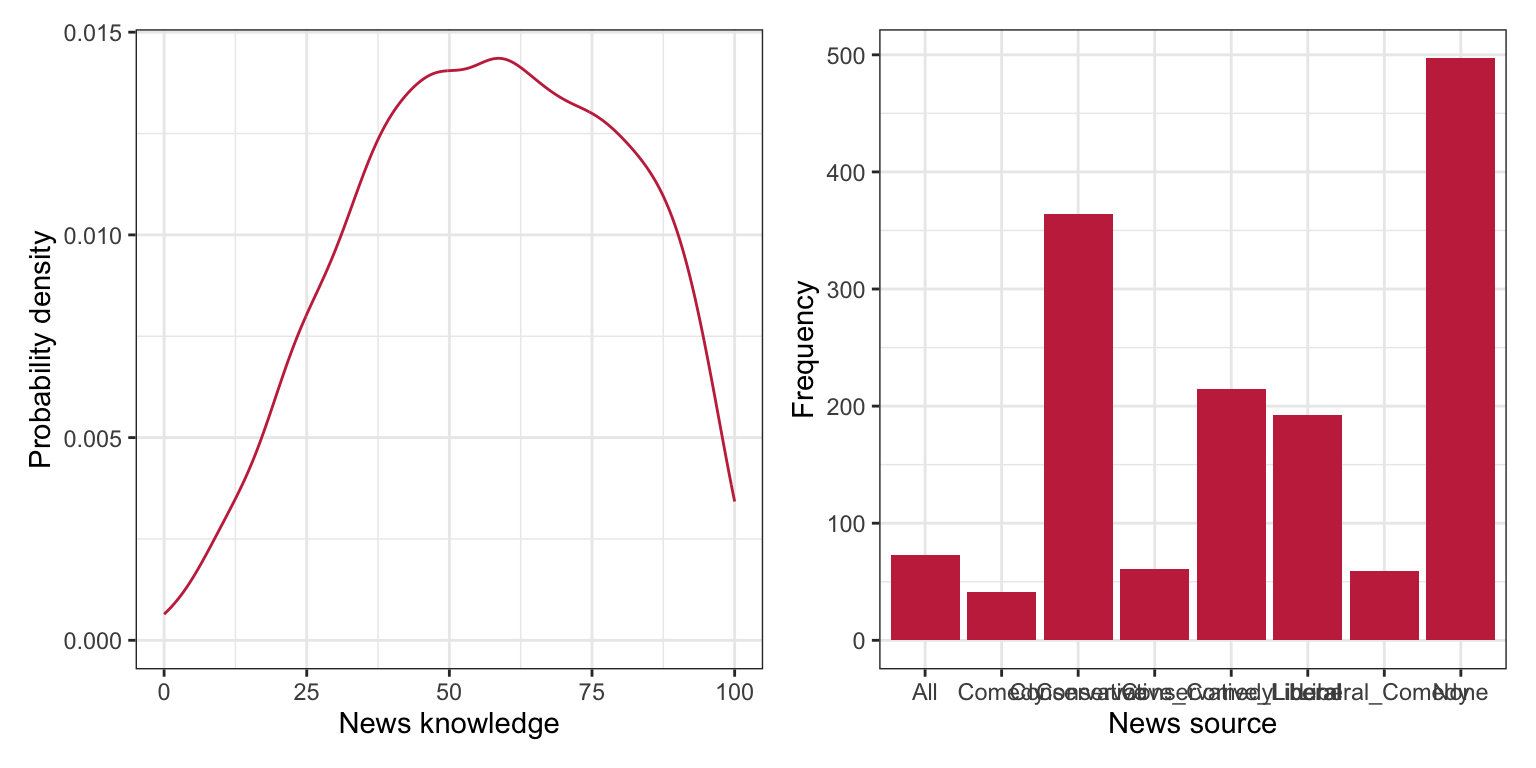
# Density plot of news knowledgep1 =ggplot(data = pew, aes(x = knowledge)) +stat_density(geom ="line", color ="#c62f4b") +#theme_bw() +xlab("News knowledge") +ylab("Probability density")# Bar plot of news sourcep2 =ggplot(data = pew, aes(x = news_source)) +geom_bar(fill ="#c62f4b") +#theme_bw() +xlab("News source") +ylab("Frequency")# Layout plotsp1 | p2
Figure 19.1: LEFT: Density plot of news knowledge. RIGHT: Bar plot of news source.
The distribution of new knowledge is slightly left-skewed with the majority of respondents scoring around 50-75. The distribution of news source indicates that the sample is quite unbalanced among the different news sources.1 The majority of the people in the sample do not watch/listen to any of the three news sources or get their news from a conservative source.
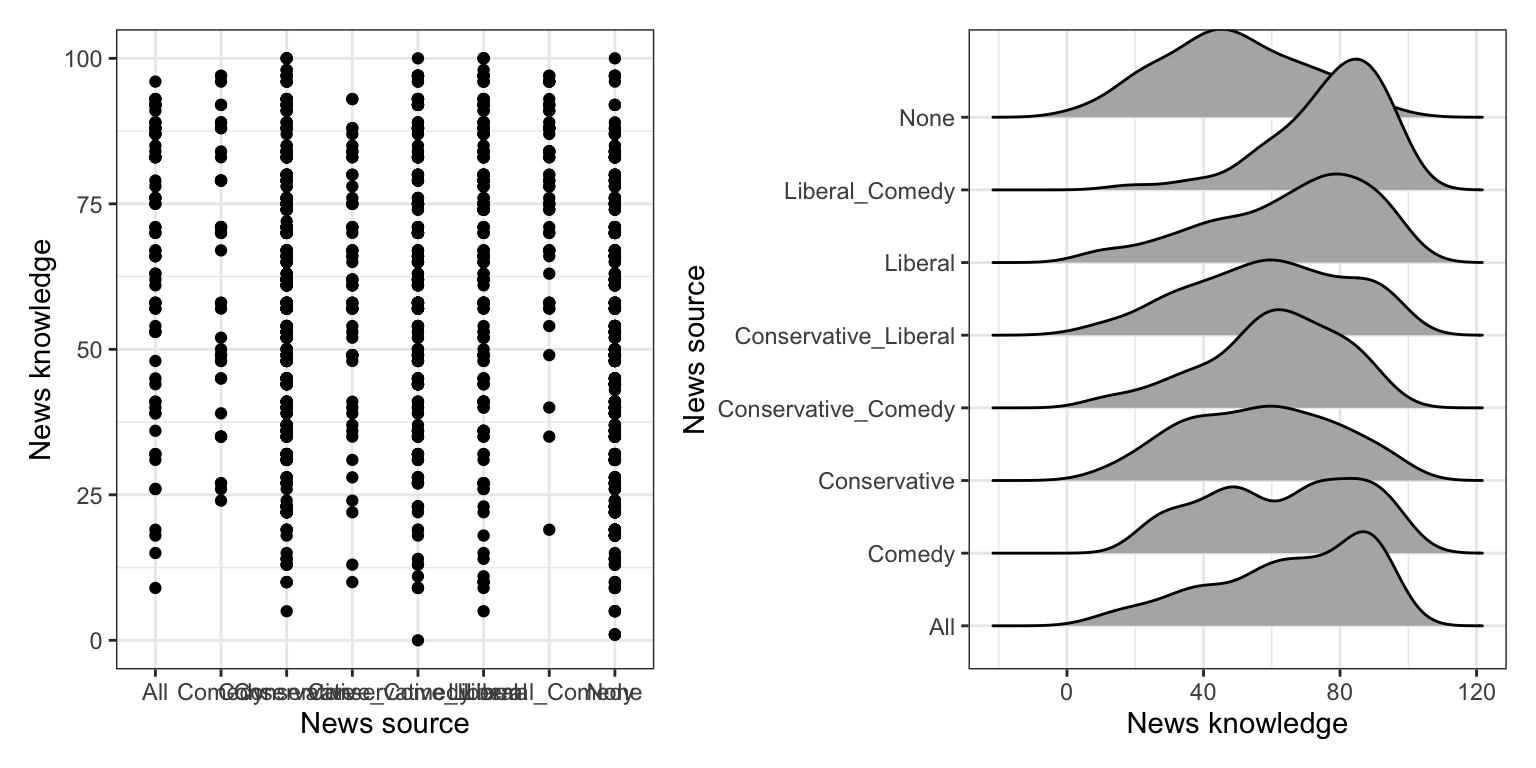
What does the distribution of news knowledge look like once we condition on news source? We will explore this by creating boxplots of the conditional distributions. To see the individual data, we will also overlay points on top of boxplots. (Using geom_jitter() rather than geom_point() adds random noise so that the points are not all on top of one another.) We will also overlay We will also compute the summary measures of news knowledge conditioned on news source.
# A tibble: 4 × 4
news_source M SD N
<chr> <dbl> <dbl> <int>
1 Liberal 65.6 23.1 192
2 Comedy 63.6 22.5 41
3 Conservative 56.5 22.1 364
4 None 48.7 21.0 497
Figure 19.2: LEFT: Boxplots of the news knowledge versus news source. The jittered points show the individual data values.
After conditioning on news source, the data suggest that there are differences in the Americans’ knowledge about current affairs based on their source of news. In the sample, those who get their news from liberal and comedy sources have the highest news knowledge scores, on average. Not surprisingly, those who do not get heir news from any of the sources have the lowest news knowledge scores, on average. Also, those who get their news from liberal or comedy sources tend to score higher (on average) than thos who get their news from conservative sources.
There is, however, a great deal of variation in all the distributions—the SDs in each distribution is around 22. This variation makes it difficult to be certain about the trends/differences we saw between the groups without carrying out any inferential analyses (e.g., CIs or hypothesis tests).
19.2 Does News Source Predict Variation in American’s News Knowledge?
To examine whether the sample differences we observed in news knowledge is more than we would expect because of chance, we can fit a regression model using news source to predict variation in news knowledge. Before fitting this model, however, we need to create a set of dummy variables; one for EACH category of the news_source variable. For our analysis, we will need to create FOUR dummy variables: The mapping for these four indicators are:
If you do not know the actual names of the categories (or you want to check capitalization, etc.) use the unique() function to obtain the unique category names.
# Get the categoriespew |>select(news_source) |>unique()
# A tibble: 4 × 1
news_source
<chr>
1 Conservative
2 None
3 Liberal
4 Comedy
It turns out that all four categories of the predictor are completely identified using any three of the four indicator variables. For example, consider the news source for the sample of six people below.
Table 19.1: News source and values on the four dummy-coded indicator variables for a sample of six people.
News Source
none
con
com
lib
Comedy
0
0
1
0
Conservative
0
1
0
0
None
1
0
0
0
Conservative
0
1
0
0
None
1
0
0
0
None
1
0
0
0
By using any three of the indicators, we can identify the news source for everyone in the sample. For example, in the data shown in Table 19.1, we used all of the indicators except for none. For Americans whose news source is “None”, they would have a 0 for all three of the indicators used. In other words, we don’t need the information in the none indicator to identify people whose news source is “None”, so long as we have the other three indicators.
To examine the effect of news source, we will fit the regression using any three of the four dummy-coded indicator variables you created. The indicator you leave out of the model will correspond to the reference category. For example, in the model fitted below, we include all the predictors except none as predictors in the model. As such, people whose news source is “None” is our reference group.
PROTIP
Ultimately we will need to fit several models, so I often name my regression objects using the reference group. For example, in the model where “None” is the reference group, I will name my regression object lm.none.
# News source = None is reference grouplm.none =lm(knowledge ~1+ con + com + lib, data = pew)# Model-level infoglance(lm.none) |>print(width =Inf)
At the model-level, differences in news source explain 8.07% of the variation in American’s news knowledge. This is statistically discernible from 0 (i.e., the empirical data are not consistent with the hypothesis that news source does not explain any variation in Americans’ news knowledge, \(F(3,1090)=31.90\), \(p < .001\).
In other words, the data suggest there is an effect of news source on news knowledge. Recall that an effect of a categorical predictor means that there are differences in the average value of the outcome between different levels of the predictor. In our example, there are differences in the average news knowledge based on news source. The key question in exploratory research is then: Which news sources show differences in the average news knowledge? In order to answer this, we need to look at the coefficient-level output.
Recall from the previous chapter, the intercept coefficient is the average Y-value for the reference group. Each partial slope is the difference in average Y-value between the reference group and the group represented by the dummy variable. In our example,
The average news knowledge score for Americans who have no news source is 48.7.
Americans who get their news from a conservative source have a news knowledge score that is 7.8 points higher, on average, than Americans who have no news source.
Americans who get their news from a comedy source have a news knowledge score that is 15 points higher, on average, than Americans who have no news source.
Americans who get their news from a liberal source have a news knowledge score that is 16.9 points higher, on average, than Americans who have no news source.
The statistical hypothesis associated with each of the parameters in the model are:
\(H_0:\beta_0 = 0\)
\(H_0:\beta_{\mathrm{Con}} = 0\)
\(H_0:\beta_{\mathrm{Com}} = 0\)
\(H_0:\beta_{\mathrm{Lib}} = 0\)
These relate to the following scientific hypotheses, respectively:
The average news knowledge score for Americans who have no news source (reference group) is 0.
The average news knowledge score for Americans who get their news from conservative sources is not different than the average news knowledge score for Americans who have no news source.
The average news knowledge score for Americans who get their news from comedy sources is not different than the average news knowledge score for Americans who have no news source.
The average news knowledge score for Americans who get their news from liberal sources is not different than the average news knowledge score for Americans who have no news source.
Because the scientific hypotheses for the partial slopes are really about comparisons of conditional means, the statistical hypotheses can also be written to reflect this as:
\(H_0:\mu_{\mathrm{None}} = 0\)
\(H_0:\mu_{\mathrm{Con}} = \mu_{\mathrm{None}}\) or equivalently \(H_0:\mu_{\mathrm{Con}} - \mu_{\mathrm{None}} = 0\)
\(H_0:\mu_{\mathrm{Com}} = \mu_{\mathrm{None}}\) or equivalently \(H_0:\mu_{\mathrm{Com}} - \mu_{\mathrm{None}} = 0\)
\(H_0:\mu_{\mathrm{Lib}} = \mu_{\mathrm{None}}\) or equivalently \(H_0:\mu_{\mathrm{Lib}} - \mu_{\mathrm{None}} = 0\)
where \(\mu_j\) represents the average news knowledge for Americans who get their news from source j (e.g., \(\mu_{\mathrm{Con}}\) indicates the average news knowledge score for Americans who get their news from conservative sources).
It is evaluation of the hypotheses associated with the partial slopes in the model that allow us to answer our question about which news sources show differences in the average news knowledge. The p-values associated with the partial slope coefficients indicate whether the observed differences in news scores (relative to the reference group) are simply due to sampling error, or whether there is a statistically discernible difference in the news knowledge between the groups. Based on the p-values, all seven groups have an average news knowledge score that is statistically discernible than the average news knowledge score for Americans who have no news source. Moreover, based on the positive coefficients, we can assume that those scores are higher than the average news knowledge score for Americans who have no news source.
19.2.1 Alternative Expression of the Model-Level Null Hypothesis
Recall that one expression of the null hypothesis associated with the model-level test in multiple regression is that all the partial slopes are zero. In general,
When we use multiple dummy-coded indicator variables to represent a categorical predictor, each partial slope represents the mean difference between two groups, and the effect of that categorical predictor is composed of ALL sets of differences between two groups (pairwise differences). In our example,there are 6 pairwise differences! (Think of all the ways we can compare two of the four different groups.)
Conservative sources vs. comedy sources
Conservative sources vs. liberal sources
Conservative sources vs. no sources
Comedy sources vs. liberal sources
Comedy sources vs. no sources
Liberal sources vs. no sources
The model-level null hypothesis, which indicates that all pairwise differences are zero, can be expressed as:
The test at the model-level is considering all possible pairwise differences simultaneously. If the model-level test is statistically discernible from 0, any one (or more than one) of the 6 differences may not be zero.
In our example, we found that the model-level test had a small p-value, so at least one of the 6 comparisons would have results that are statistically discernible from 0.
Note that in our coefficient-level output, we found that 3 of the potential comparisons (those that compare to the “None” group) yielded results that were statistically discernible from zero. That is, based on those results we believe:
Unfortunately, the coefficient-level output from the regression we fitted, does not give us any information about the other 3 comparisons. In order to get information about the other pairwise comparisons, we need to fit additional regression models using a different reference group.
When you have more than two levels in your categorical predictor in order to examine ALL potential coefficient-level differences, you will need to fit many regression models using different reference groups.
19.3 Pairwise Comparisons for Americans who get their News from Conservative Sources
Consider the pairwise comparisons between Americans who get their News from conservative sources and those who get their news from other sources. There are 3 such comparisons. We already evaluated one of those, namely the comparison between Americans who get their News from conservative sources and those who have no news source. To evaluate the other 2 differences, we need to fit a model in which con is the reference group. By doing this, the partial slopes will indicate the difference in average news knowledge between Americans who get their news each of the other sources and those who get their news from conservative sources. Below, we fit this model (using con as the reference group) to predict variation in news knowledge.
# Conservative news sources is reference grouplm.con =lm(knowledge ~1+ com + lib + none, data = pew)# Model-level infoglance(lm.con) |>print(width =Inf)
Note that the model-level output for this fitted model is exactly the same as that for the model in which none was the reference group. That is because at the model-level, this model is testing the exact same hypothesis as the previous model (to examine whether the 6 sets of pairwise differences explain variation in news knowledge). The results suggest that at least one of the pairwise differences is statistically discernible from 0; that is there are differences in the average amount of news knowledge between at least two of the groups.
The average news knowledge score for Americans who get their news from conservative sources is 56.5. The empirical evidence suggests that this is statistically discernible from 0; \(t(1090)=49.50\), \(p<.001\).
Americans who get their news from a comedy source have a news knowledge score that is 7.2 points higher, on average, than Americans who get their news from conservative sources. The empirical evidence suggests that this is statistically discernible from 0; \(t(1090)=2.00\), \(p=.046\).
Americans who get their news from a liberal source have a news knowledge score that is 9.2 points higher, on average, than Americans who get their news from conservative sources. The empirical evidence suggests that this is statistically discernible from 0; \(t(1090)=4.71\), \(p<.001\).
Americans who don’t get their news from any source have a news knowledge score that is 7.8 points lower, on average, than Americans who get their news from conservative sources. The empirical evidence suggests that this is statistically discernible from 0; \(t(1090)=-5.20\), \(p<.001\).
Note that the last comparison (with the none group) is the comparison we already evaluated in the previous model. The coefficient-level output for this gives redundant information that from the previous model—the only difference being that the signs are opposite on the coefficient and t-value since we changed the reference group. (The p-values are identical.)
19.4 Pairwise Comparisons for Americans who get their News from Comedy Sources
Here we fit one additional regression model, with comedy as the reference group, to get the remaining pairwise comparison. (You could also fit a model with liberal as the reference group; also shown.)
# Reference group = Comedy Newslm.com =lm(knowledge ~1+ con + lib + none, data = pew)# Reference group = Liberal News#lm.lib = lm(knowledge ~ 1 + con + com + none, data = pew)
Below we display the coefficient-level output for the model with comedy as the reference group and write out the fitted equation.
The average news knowledge score for Americans who get their news from comedy sources is 63.6. The empirical evidence suggests that this is statistically discernible from 0; \(t(1090)=18.70\), \(p<.001\).
Americans who get their news from a conservative source have a news knowledge score that is 7.2 points lower, on average, than Americans who get their news from comedy sources. The empirical evidence suggests that this is statistically discernible from 0; \(t(1090)=-2.00\), \(p=.046\).
Americans who get their news from a liberal source have a news knowledge score that is 2.0 points higher, on average, than Americans who get their news from comedy sources. The empirical evidence suggests that this is NOT statistically discernible from 0; \(t(1090)=0.53\), \(p=.598\).
Americans who don’t get their news from any source have a news knowledge score that is 15.0 points lower, on average, than Americans who get their news from comedy sources. The empirical evidence suggests that this is statistically discernible from 0; \(t(1090)=-4.23\), \(p<.001\).
19.5 Presenting Results of the Pairwise Comparison Tests
Now that we have statistical results from the 6 pairwise comparisons let’s consider how we might want to present these results to a reader. As always, we can do this by presenting the results in the text of the manuscript, in a table, or in a visualization. If the number of pairwise comparisons is small (say three or fewer), presenting them in the text is reasonable as doing so would take less space than using a table or plot. When you have a larger number of comparisons to present, doing so in text is likely not a good choice due to the cognitive burden this would place on the reader.
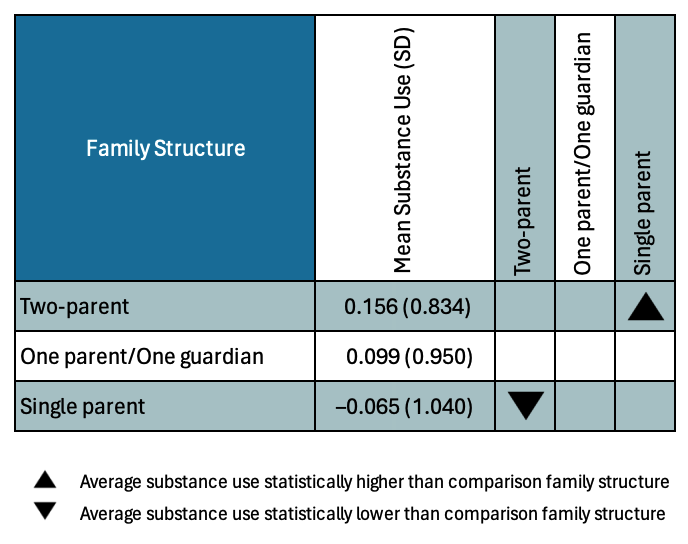
A table is a good choice for a small to moderate number of comparisons (e.g., \(\leq10\) comparisons). For example, Table 19.2 presents the results for three pairwise comparisons carried out as part of a research study examining the effects of family structure on teen substance use.
Table 19.2: Pairwise comparisons of adolescent substance use between three family structures.
Comparison
Mean
Difference
p
Two-parent vs. Parent/guardian
0.164
0.079
Two-parent vs. Single-parent
0.221
0.005
Parent/guardian vs. Single-parent
0.057
0.609
Once you have more than 10 comparisons, presenting this information in a table can be overwhelming. (If you really need to do this, consider putting the table in an appendix or in online resources rather than in the manuscript itself.) There are several options for such a visualization. One that I like, which shows the same pairwise comparisons presented in tbl-mean-diffs, is the following:
Figure 19.3: Pairwise comparisons of average teen substance use for different family structures.
Instructions: Read across the row for a family structure to compare substance use with the family structures listed along the top of the chart. The symbols indicate whether the average substance use of the family structure in the row is significantly lower than that of the comparison family structure, significantly higher than that of the comparison family structure, or if there is no statistically discernible difference between the average substance use of the two countries.
The column of mean substance use is handy for readers to see the sample differences. (Including the SD here is not necessary, especially if those are included in a different place in the manuscript.) Note, I listed the family structures from largest mean to smallest mean in the figure (in both the rows and columns). This will put all of the down-pointing triangles in the upper right and the up-pointing triangles in the lower left of the figure. This makes it easier to quickly determine which comparison groups a particular group is hgher or lower than. If you have many, many groups listing them alphabetically makes it easier for readers to find the group they are interested in making comparisons for.
Table-like graphics, such as the pairwise comparison visualizations are often easier to create in Excel (or some other spreadsheet program) than in R. I created these in Excel and then, after turning off the grid lines, took a screenshot and inserted that into this chapter.
In our case, presenting the results from 6 comparisons would probably be fine in a table.
Table 19.3: Pairwise contrasts between the average news knowledge for different news sources.
Contrast
Mean
Difference
p
Comedy - Conservative
7.1
0.046
Comedy - Liberal
-2.0
0.598
Comedy - None
15.0
<.001
Conservative - Liberal
-9.1
<.001
Conservative - None
7.8
<.001
Liberal - None
16.9
<.001
FYI
The formal vocabulary for a statistical comparison is a contrast, which is technically a difference.
19.5.1 Link to the Analysis of Variance Methodology for Testing Mean Differences
In your statistics journey, you may have encountered the one-factor analysis of variance (ANOVA). This method is often introduced as a way of testing mean differences when you have more than two groups. The null hypothesis for this method (referred to as the omnibus null hypothesis) is that all group means are equal.
Recall that the model-level hypothesis could be written such that the difference in each pair of group means is 0, namely:
Note that the only way for each of these differences to be 0 is if all the means for every news source are equal. This implies that we could also write the model-level null hypothesis as:
This is the same null hypothesis that is associated with the one-factor analysis of variance.
Fitting a regression model with dummy-coded indicator variables gives the exact same results as carrying out a one-factor ANOVA. The difference is that the output from the multiple regression gives \(\beta\)-terms associated with mean differences (to the reference group), and ANOVA is concerned more directly with the group means. But the model-level regression results are identical to those from the ANOVA. Asking whether the model explains variation in the outcome (\(H_0:\rho^2=0\)) is the same as asking whether there are mean differences; these are just different ways of writing the model-level null hypothesis!
19.6 Does News Source Predict Variation in News Knowledge After Accounting for Other Covariates?
One question we may have is whether the differences we saw in Americans’ average news knowledge persist after we account for other covariates that also explain differences in news knowledge (e.g., age, education, amount of news consumed, and political engagement). To evaluate this, we will fit a regression model that includes these covariates, along with three of the four dummy-coded news source predictors to explain variability in news knowledge.
# News source = None is reference grouplm.none.2=lm(knowledge ~1+ age + education + news + engagement + com + con + lib, data = pew)# Model-level infoglance(lm.none.2) |>print(width =Inf)
At the model-level, differences in news source, age, education level, amount of news consumption, and political engagement explain 34.4% of the variation in American’s news knowledge. This is statistically discernible from 0 (i.e., the empirical data are not consistent with the hypothesis that this set of predictors does not explain any variation in Americans’ news knowledge), \(F(7,~1086)=81.40\), \(p<.001\).
The interpretations are provided below. While we offer them for the four covariates, we note that the only interpretations that we care about are those for our focal predictors of news source.
Intercept and Covariates
The average news knowledge score for Americans who have no news source, are 0 years old, have 0 years of education, have no news exposure, and are not politically engaged is -27.80 (extrapolation).
Each one-year difference in age is associated with a 0.19-point difference in news knowledge score, on average, after controlling for the other predictors in the model.
Each one-year difference in education is associated with a 3.24-point difference in news knowledge score, on average, after controlling for the other predictors in the model.
Each one-unit difference in news consumption is associated with a 0.23-point difference in news knowledge score, on average, after controlling for the other predictors in the model.
Each one-unit difference in political engagement is associated with a 0.23-point difference in news knowledge score, on average, after controlling for the other predictors in the model.
Focal Predictors
Americans who get their news from comedy sources have a news knowledge score that is 7.87 points higher than Americans who have no news source, on average, after controlling for the other predictors in the model.
Americans who get their news from conservative sources have a news knowledge score that is 0.08 points higher than Americans who have no news source, on average, after controlling for the other predictors in the model.
Americans who get their news from liberal sources have a news knowledge score that is 5.96 points higher than Americans who have no news source, on average, after controlling for the other predictors in the model.
FYI
Another methodology you may have encountered in your statistics journey is analysis of covariance (ANCOVA). This method is often introduced as a way of testing mean differences while controlling for other covariates. Again, this is exactly what we are evaluating in the regression model when we included the covariates of age, education level, amount of news consumption, and political engagement. Just as you can carry out ANOVA using regression, you can also carry out an ANCOVA using regression.
19.6.1 Adjusted Mean Differences and Adjusted Means
The mean differences we obtained from the regression model that included our covariates are referred to as controlled mean differences. In the language of ANCOVA, the controlled mean differences are referred to as Adjusted Mean Differences. To separate this from the mean differences we obtained from the model with no covariates, we refer to those differences as Unadjusted Mean Differences.
For example, in the model that did not include any covariates (lm.none), the difference between the news knowledge scores for Americans who get their news from conservative sources and those that have no news source is 7.80 points. This is the unadjusted mean difference between these two groups of Americans. Once we account for differences explained by age, education level, amount of news consumption, and political engagement, the difference in news knowledge is 0.08 points. This is the controlled (or adjusted) mean difference between these two groups of Americans.
The unadjusted mean differences are based on the difference between the unadjusted means. That is we computed the means for the two groups and then computed the difference between them. Earlier we found that the mean news knowledge score for Americans who get their news from conservative sources was 56.5 and that for Americans that have no news source was 48.7. The difference (unadjusted mean difference) is \(56.5-48.7=7.8\). This is exactly the difference that the unadjusted regression model (i.e., the model with no covariates) produces.
Similarly, the adjusted mean differences are based on the difference between the adjusted means. So how do we compute the adjusted means? Remember that the predicted values from regression models are means. The predicted values from the unadjusted regression model produces unadjusted means, and the predicted values from the adjusted regression model (i.e., the model with covariates) produces adjusted means. So we need to substitute values into our fitted equation to produce the predicted news knowledge values for each of the different news sources.
For the news source predictors we will substitute 0 or 1 into each of the predictors based on the news source we are computing the adjusted mean for. For the covariates, we can use any value we want, but it is typical to substitute the mean values of the covariates when computing adjusted means. Below we compute the adjusted means for each news source.
##################################### Mean age = 50.81# Mean education = 13.92# Mean news consumption = 41.91# Mean political engagement = 73.18##################################### Compute adjusted mean for comedy source-27.8+0.186*50.81+3.24*13.92+0.230*41.91+0.233*73.18+0.0825*1+7.87*0+5.96*0
[1] 53.5242
# Compute adjusted mean for conservative source-27.8+0.186*50.81+3.24*13.92+0.230*41.91+0.233*73.18+0.0825*0+7.87*1+5.96*0
[1] 61.3117
# Compute adjusted mean for liberal source-27.8+0.186*50.81+3.24*13.92+0.230*41.91+0.233*73.18+0.0825*0+7.87*0+5.96*1
[1] 59.4017
# Compute adjusted mean for none source-27.8+0.186*50.81+3.24*13.92+0.230*41.91+0.233*73.18+0.0825*0+7.87*0+5.96*0
[1] 53.4417
The adjusted mean values for each news source are:
Comedy: 61.32
Conservative: 53.52
Liberal: 59.40
None: 53.44
Using these, we can compute the adjusted mean differences. For example the adjusted mean difference between Americans who get their news from conservative sources and Americans who have no news source is \(53.52-53.44=0.08\). This is, again, exactly the value that the adjusted regression model (i.e., the model with covariates) produces as a coefficient.
19.7 Obtaining the Other Adjusted Pairwise Comparisons
Here we will fit several other models (using the same set of covariates) to obtain the remaining adjusted pairwise comparisons and their p-values. We will use these results to build another table presenting the adjusted mean values and the adjusted comparisons.
# News source = Comedy is reference grouplm.com.2=lm(knowledge ~1+ age + education + news + engagement + con + lib + none, data = pew)# Coefficient-level outputtidy(lm.com.2)
Table 19.4: Pairwise contrasts between the average news knowledge for different news sources after controlling for differences in age, education, news consumption, and political engagement.
Contrast
Mean
Difference
p
Comedy - Conservative
7.79
.011
Comedy - Liberal
1.91
.548
Comedy - None
7.87
.010
Conservative - Liberal
-5.87
.001
Conservative - None
.083
.955
Liberal - None
5.96
<.001
Comparing the adjusted and unadjusted means, along with the p-values for the adjusted and unadjusted pairwise comparisons, we observe several things:
The level of news knowledge (i.e., the mean) for the groups changed once we adjusted for our set of covariates.
Based on the adjusted means, the order of the groups (when we rank them from largest to smallest amount of news knowledge) also changed.
Using the unadjusted means, we observed statistically discernible differences in 5 of the 6 paired comparisons. But, after controlling for our set of covariates, we now only observe statistically discernible differences in 4 of the 6 paired comparisons. (This suggests that the reason we were observing differences in news knowledge between Americans who get their nes from conservative sources and those that get their news from no sources was because those groups differed in age, education level, amount of news consumption, or political engagement.)
19.8 Optional: Another Visualization—Confidence Intervals for Adjusted Means
One common method for visually presenting the results from group comparisons is to produce confidence intervals for the adjusted means and then plot those for each group. To do this we are going to create a data frame that we can use (along with a fitted model) to produce adjusted means and standard errors for those means. We will use the fitted model lm.none.2 to produce the adjusted means and standard errors. As a reminder, the syntax for producing lm.none.2 was:
# News source = None is reference grouplm.none.2=lm(knowledge ~1+ age + education + news + engagement + com + con + lib, data = pew)
The data frame we will create needs to have the values that we will be substituting into the fitted equation to get the adjusted mean values. Each row in the data frame will correspond to a person from a particular group (American who gets their news from a particular news source). Because we have 4 news sources, there will be 4 rows in the data frame. Each column will correspond to a different predictor from the fitted lm(). In our case, since we will be using lm.none.2 to produce the adjusted means, we would need 11 columns. Here is the syntax to create our data frame.
And, here are some tips for creating the data frame:
Remember that the data.frame() function defines columns in the data frame.
The column names in the data frame have to match the predictor names in the lm() exactly.
The column names should be given in the same order as the predictors in the lm(). (While this isn’t strictly necessary it will help to keep things organized.)
Each column will include 4 values (one value for each row).
The columns names that are covariates will be set equal to a single value, namely the mean of that covariate. You could also give this a vector and repeat the same value 8 times, but R will do this automatically.
The column names corresponding to each of the groups (i.e., our focal dummy variables) will be given a vector of four values (one for each group we have).
These four values will all be 0s except for one value which will be 1.
The key is that each value from the vector will be put in a different row, and each row needs to correspond to the dummy coding associated with one of the groups.
Each row in d represents an American who gets there news from each of the four news sources. Notice that the dummy coding in each row corresponds to a particular group. For example, the dummy coding in Row 1 corresponds to the ‘None’ group, while that in Row 2 corresponds to the ‘Comedy News’ group.
FYI
When you are creating your data frame, the vector values are filling a column, not a row. But, you need the dummy coding to correspond to rows. It can be helpful to sketch out the data frame on a piece of paper first, and then write the code to create that data frame. Always look at the resulting data you create to be sure it has the correct structure!
Once we have the data, we can use the predict() function to get predicted values (i.e., adjusted means) and standard errors. To do this, we give the function the name of the regression object we are using (lm.none.2). We also include the newdata= argument, which takes the name of the data frame we want to use for the predictions. Finally, we include se = TRUE to output the standard errors.
# Obtain adjusted means and standard errors for each row in dpredict(lm.none.2, newdata = d, se =TRUE)
The adjusted mean values are provided in the $fit part of the output. There should be 4 values, one for each row in d. So the first fitted value (55.51970) is the adjusted mean for the first row in d, which corresponds to the ‘None’ group.2 Similarly there are 4 standard errors (in the $se.fit part of the output), each corresponding to a row in d. So the SE for the ‘None’ group is 1.0169867.
We are going to create a second data frame that includes the 4 group names (based on the order in d), the adjusted mean values, and the SEs. This will be the data that we use to create our plot of the CIs.
source m se
1 None 55.51970 1.0169867
2 Comedy 63.38794 2.8982189
3 Conservative 55.60224 0.9788414
4 Liberal 61.47512 1.3693665
Now, we need to create the lower and upper limits of the CI as new columns in the data frame. To do this, recall that the formula for creating a CI is:
where the estimate in our example is the adjusted mean, SE is the standard error, and \(t^*\) is a multiplier value based on the residual degrees of freedom for the regression model.3 To determine \(t^*\), we are going to use the qt() function. This function takes two arguments:
The first argument is a value between 0 and 1 that corresponds to the confidence level you want. For a 95% CI this value will be 0.975.4
The second argument, df=, provides the residual degrees-of-freedom for the regression model. (Note this is also given in the predict() output.)
# Compute t-starqt(.975, df =1086)
[1] 1.962151
Now we can mutate() on the lower and upper limits of the CI for each adjusted mean.
# Compute CI limitsplot_data = plot_data |>mutate(lower = m -1.962151*se,upper = m +1.962151*se )# View dataplot_data
source m se lower upper
1 None 55.51970 1.0169867 53.52422 57.51518
2 Comedy 63.38794 2.8982189 57.70120 69.07468
3 Conservative 55.60224 0.9788414 53.68161 57.52287
4 Liberal 61.47512 1.3693665 58.78822 64.16202
Lastly, we can create our visualization of the CIs.
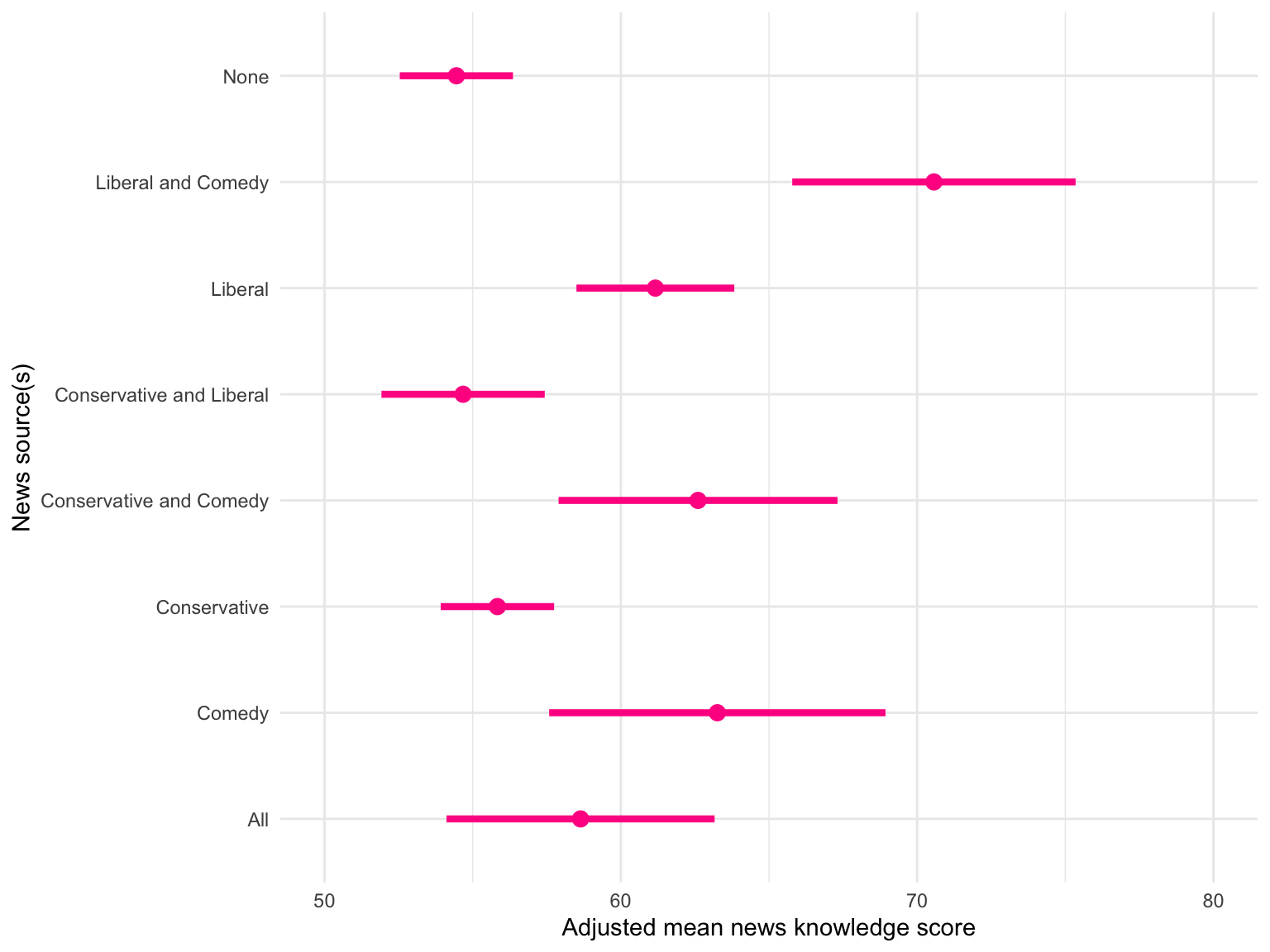
Figure 19.4: 95% confidence intervals for the adjusted mean news knowledge scores for Americans who get their news from eight different sources. The means are adjusted for differences in age, education level, amount of news consumed, and political engagement.
Intervals that overlap indicate that those groups are not different in their adjusted mean scores. For example, the ‘None’ group and the ‘Conservative and Liberal’ intervals overlap each other. This suggests that their adjusted mean news knowledge scores might be the same (no statistical difference is discernible).
In a balanced sample, the sample size would be equal across categories. This typically happens only when participants are randomly assigned to levels of the categorical predictor. Almost all observational data is unbalanced.↩︎
Note that these values are what we obtained for the adjusted means within rounding.↩︎
We often use \(t^*=2\) when we want a rough estimate.↩︎
We can compute this as \(1 - \bigg(\frac{1 -\mathrm{Conf.~Level}}{2}\bigg)\). IN our exampe, for a 95% CI, \(1 - \bigg(\frac{1 -0.95}{2}\bigg) = 0.975\).↩︎