4 Visualizing and Describing Quantitative Attributes
This chapter will focus on the visualization and description of quantitative attributes. To illustrate how we can summarize and visualize quantitative attributes using R, we will use the mn-colleges.csv data. This data includes admissions related data for the 33 institutions of higher learning in Minnesota.
In these data each case is an institution of higher education in the state of Minnesota. There are 33 institutions in our sample. There are several quantitative attributes in the data, including: the number of applicants, the number of applicants who were admitted, and the acceptance rate. We will focus on the acceptance rate attribute in this chapter.
4.1 Dot Plot
The first visualization we will examine is a dot plot. A dot plot is a simple visualization of a quantitative attribute that uses a dot to represent the attribute value for each case. The plot of all the dots (which is plotted over a number line) allows us to easily see the frequency of cases at each value.
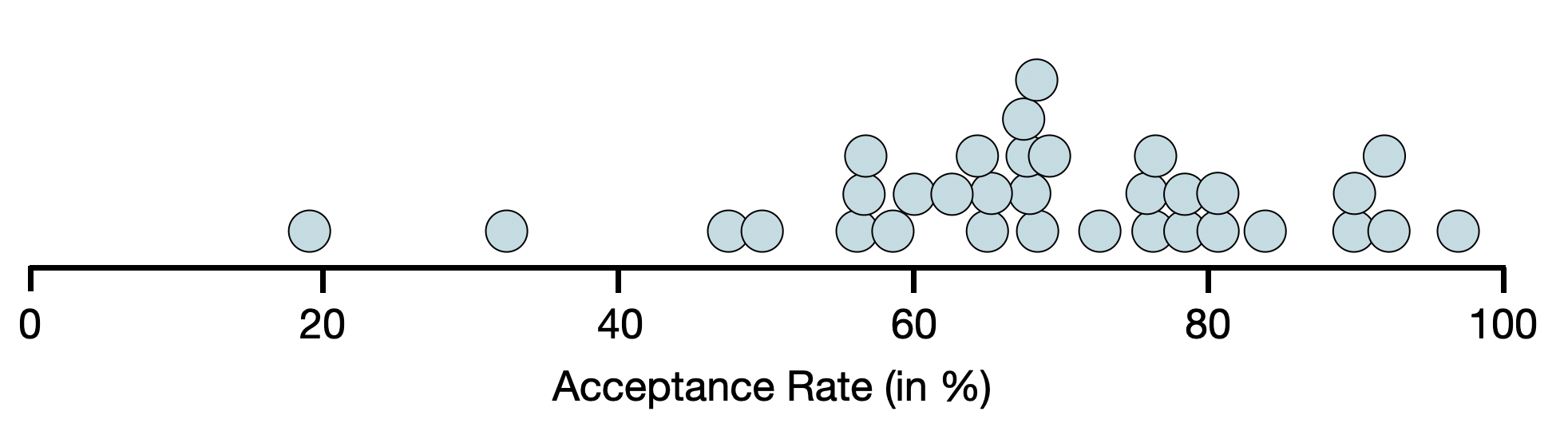
Each dot is a different institution of higher education. For example, the dot on the far left of the plot is Carleton College (which has an acceptance rate of 19.1%). Looking at this plot, we can see that:
- The acceptance rate for these schools is quite variable with the lowest acceptance rate of around 20% (Carleton College) and the highest acceptance rate is near 100% (Dunwoody College of Technology).
- There are several colleges have an acceptance rate around 65%. (This is the highest stack/clump of dots.)
While the dot plot does allow us to see each individual case, it is not often used in visualization. This is because when there are many cases in your data set, the dot plot becomes overwhelming. Even with only 33 cases you see that the dots are crowded.
4.2 Histograms
A more common visualization used for quantitative attributes is the histogram. The histogram essentially puts the cases from the dot plot into a bin.
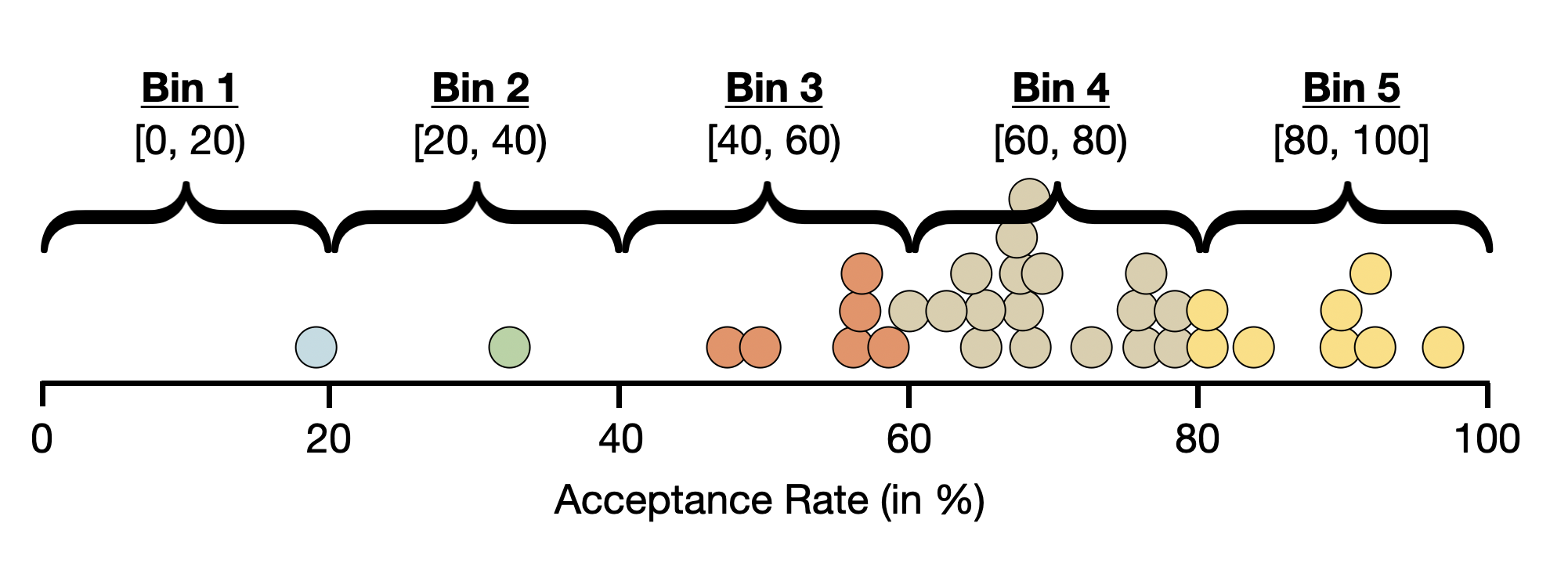
Then a bar is drawn for each bin. The height of this bar indicates the number (count) of cases in that bin.
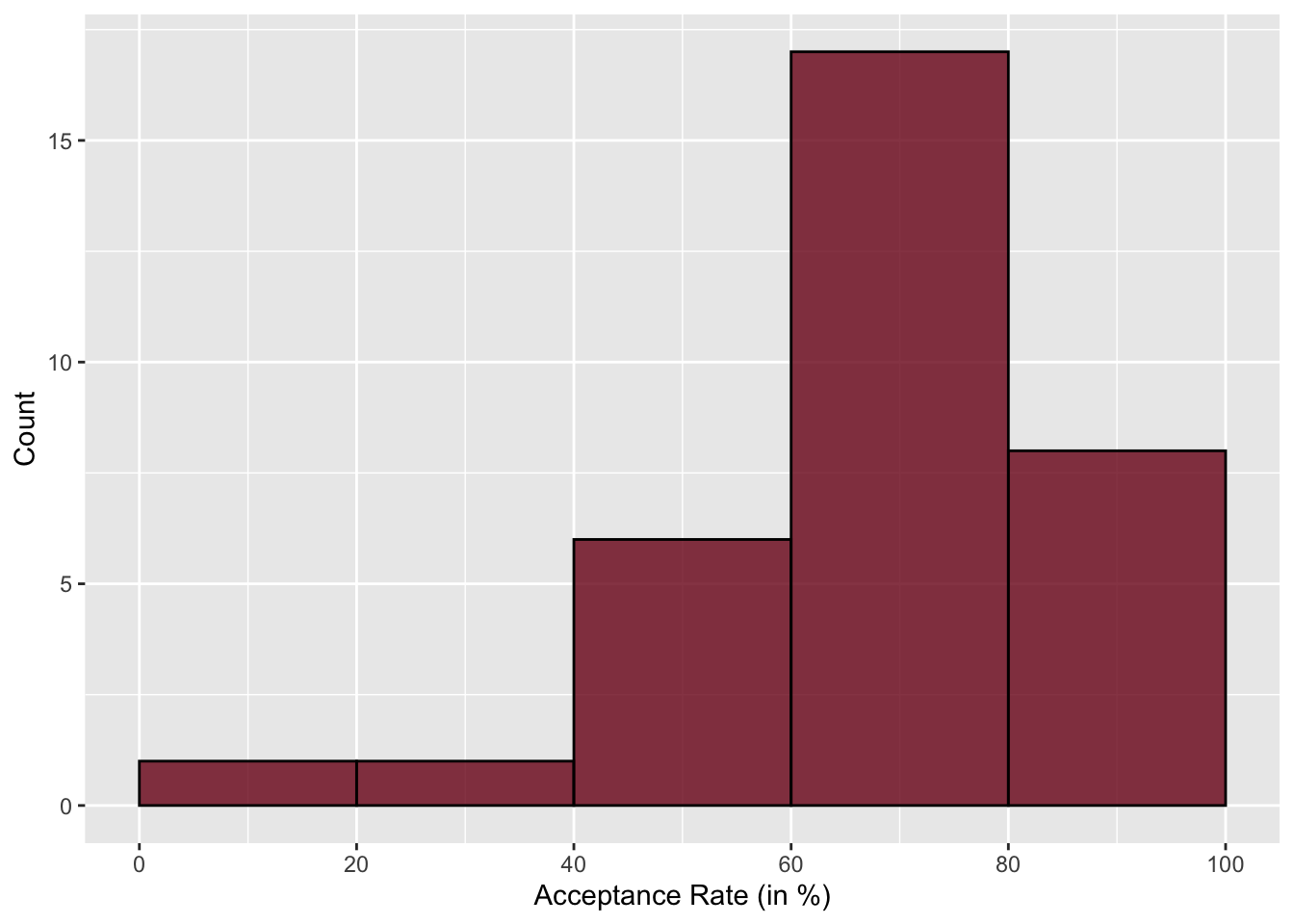
Notice that although the histogram is less cluttered than the dot plot, we do lose some nuance. For example, it is now difficult to determine what the lowest (or highest) acceptance rate is since we no longer see the individual cases. We only know that the lowest acceptance rate is somewhere between 0 and 20.
We can fix this by changing the bin width. Rather than a bin width of 20, we could try a bin width of 10 or 5.
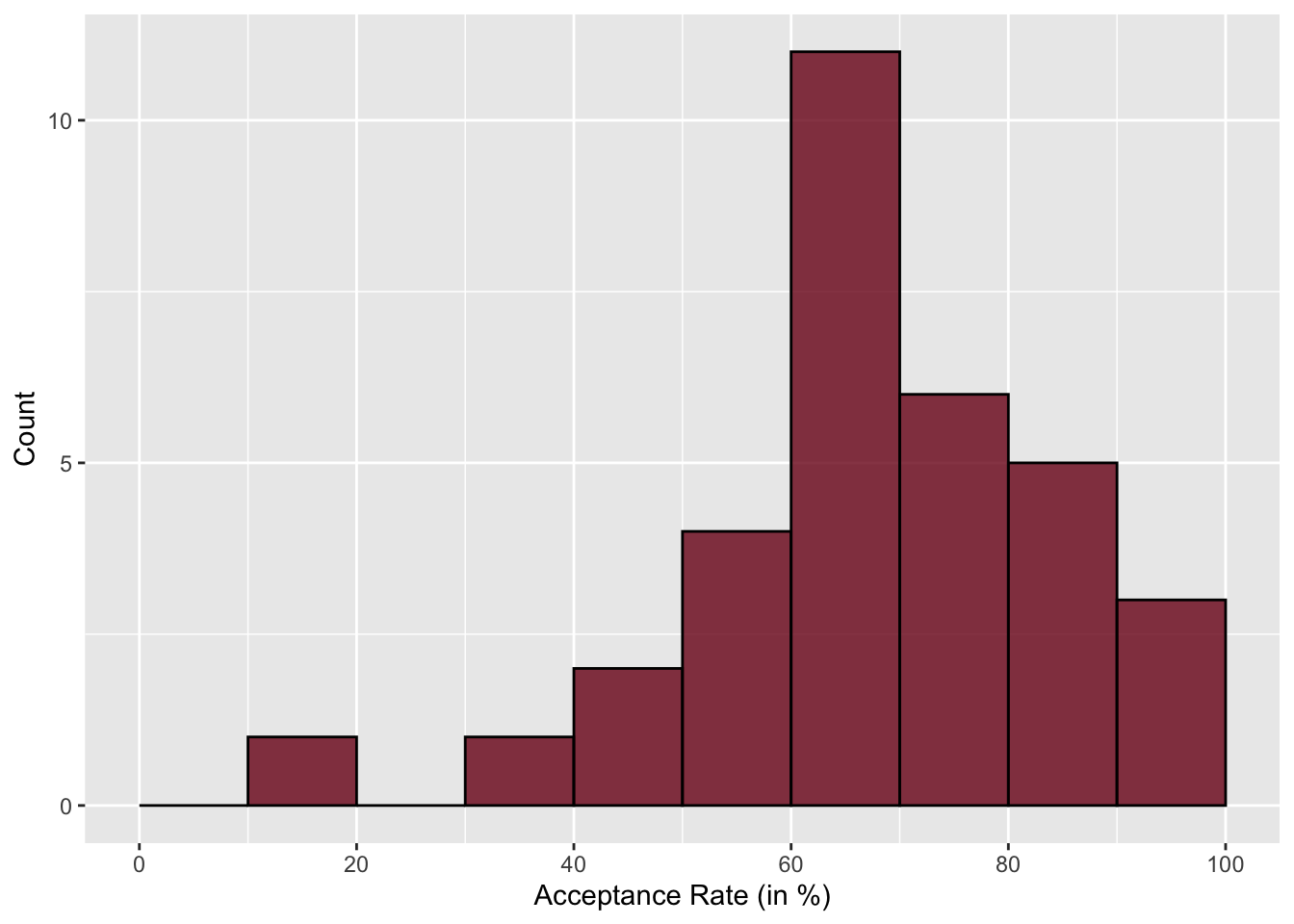
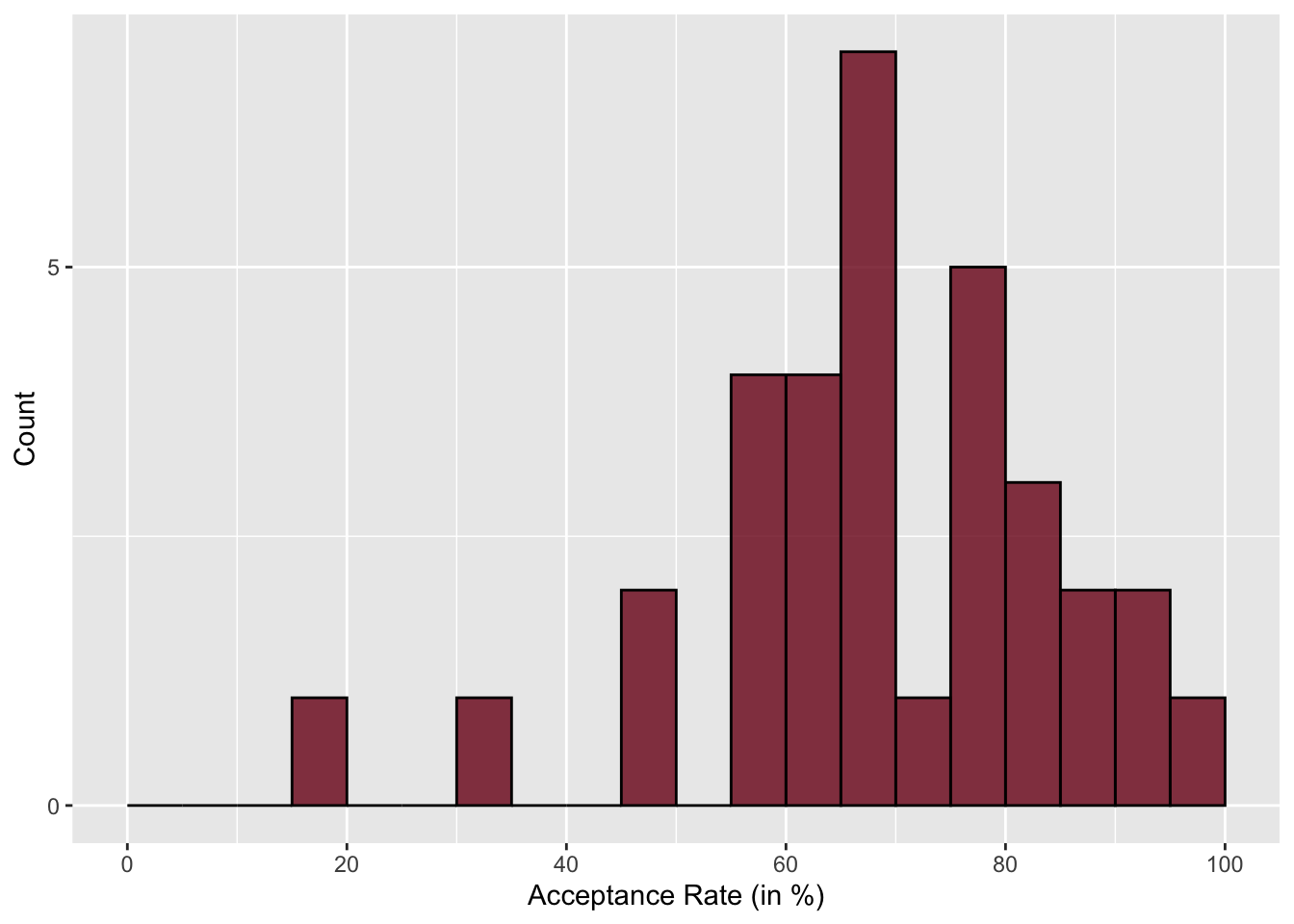
The histogram with a bin width of 5 gives enough nuance to hone in on the lowest and highest values pretty well. In this histograms, we also see that the highest bar is around 65%—similar to what we saw in the dot plot. You also see that the higher bars tend to be on the right-side of the plot, indicating that there are more institutions with higher acceptance rates than there are with lower acceptance rates.
4.3 Density Plot
An alternative to the histogram is a density plot. To create a density plot, imagine throwing a sheet over the top of a histogram. The resulting plot is a density plot.
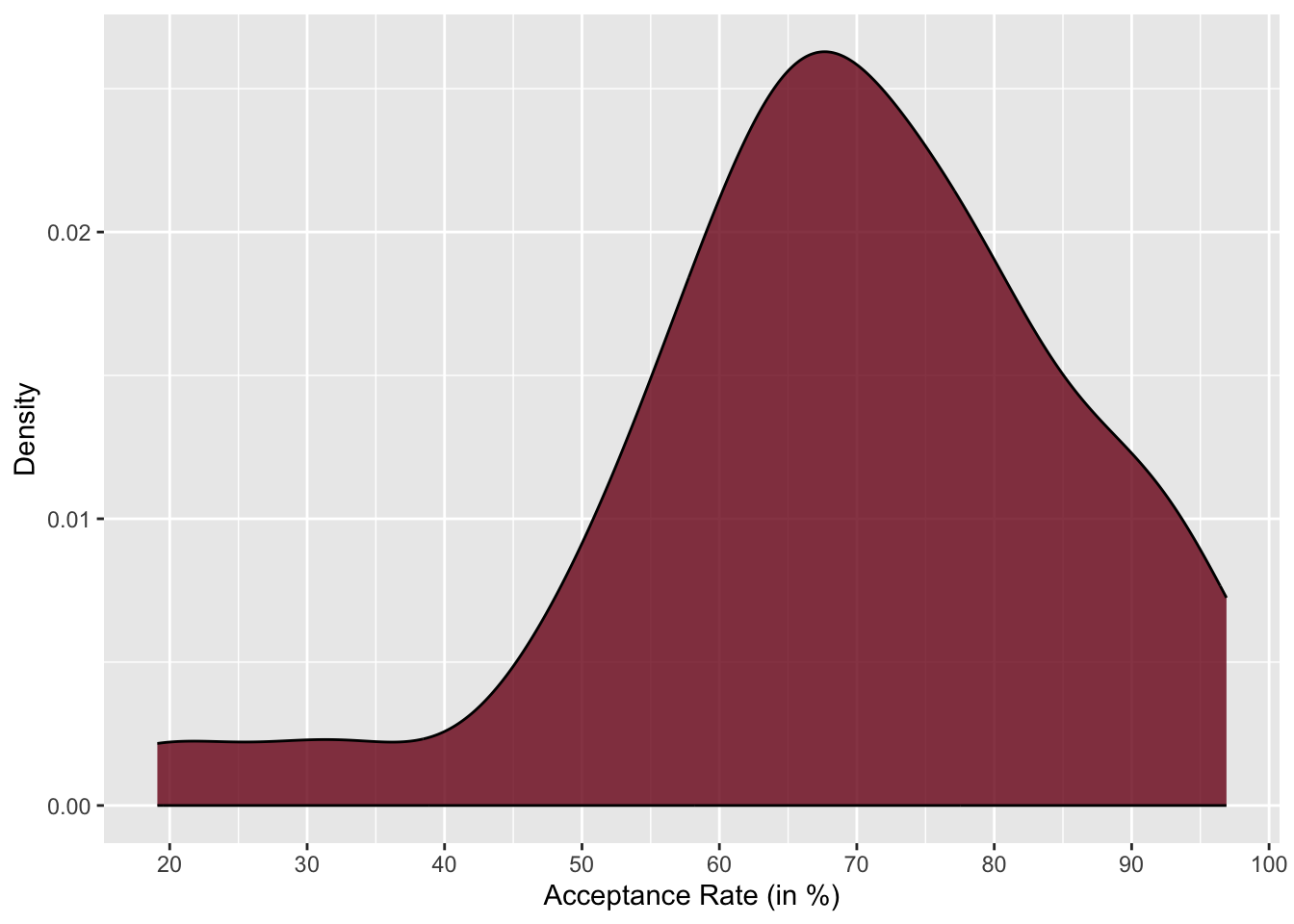
In a density plot, we are no longer plotting counts on the y-axis, but instead are plotting something called “density”. While density is pretty technical, you can think about it like probability. So looking at this density plot, it is more probable that institutions have an acceptance rate of around 50% than an acceptance rate around 30% because the density is higher at the acceptance rate of 50% than it is at 30%. The highest density occurs around 65%, which is the most probable acceptance rate.
Similar to the dot plot, the density plot also allows us to easily see the lowest and highest acceptance rates—around 20% and 95%, respectively. Like the histogram, we also see that in the density plot, the density values on the right-hand side of the plot are higher than those on the left-hand side of the plot. This tells us that it is more likely for these institutions to have a higher acceptance rate than for them to have a lower acceptance rate.
4.4 Describing the Distribution
Data scientists have a specific vocabulary for describing the distribution of quantitative attributes. They would say that the distribution of acceptance rates is left-skewed. A left skewed distribution has the majority of cases on the right side of the distribution (i.e., at higher values of the attribute). In contrast, a distribution that has the majority of cases on the left side of the distribution (i.e., at lower values of the attribute) is called right-skewed. Figure 4.6 shows examples of both a left-skewed and right-skewed distribution.
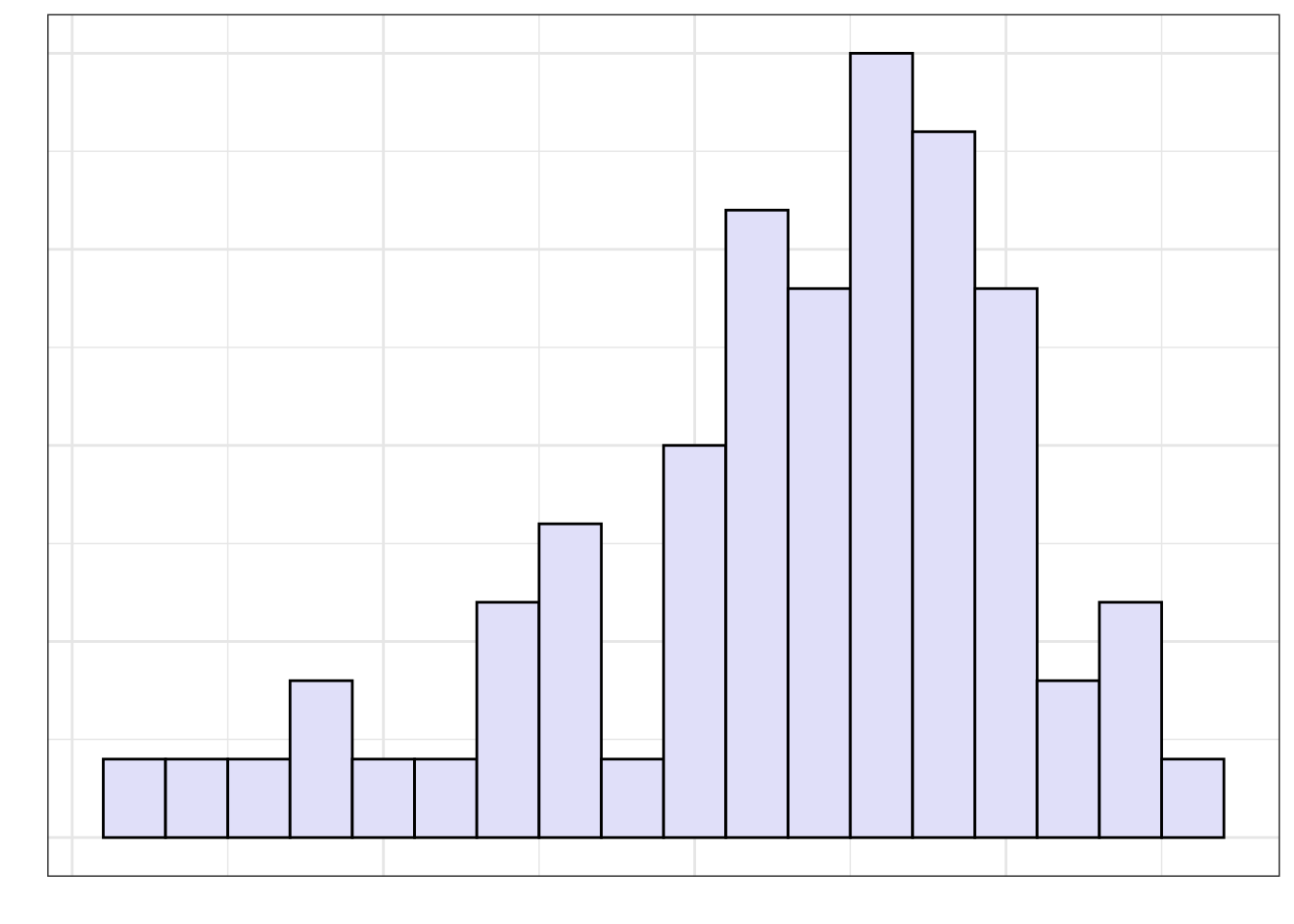
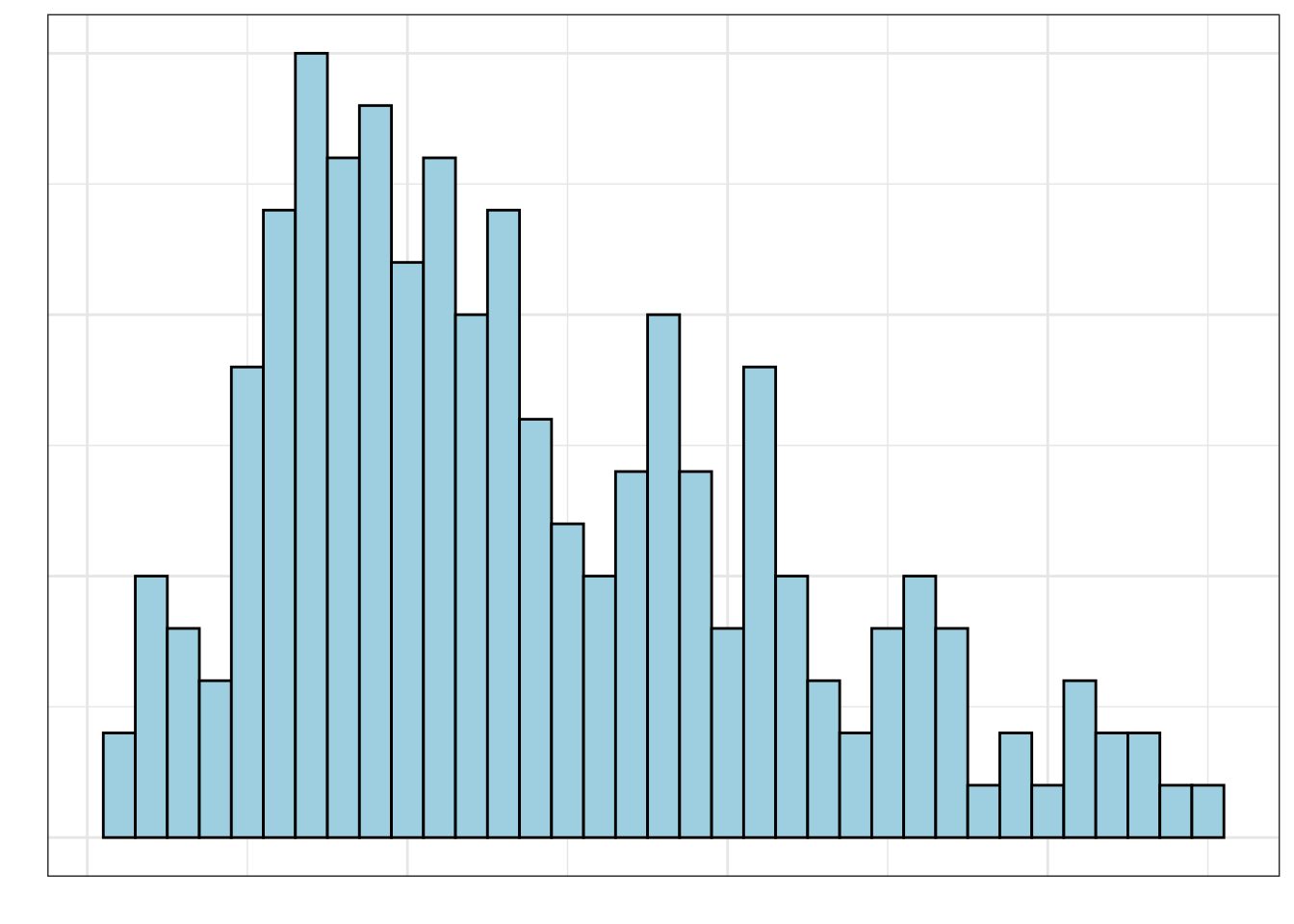
The skewness of a distribution describes a characteristic that we refer to as the shape of the distribution. Some distributions are not skewed, these distributions have a symmetric shape. Figure 4.7 shows an example of a symmetric distribution.
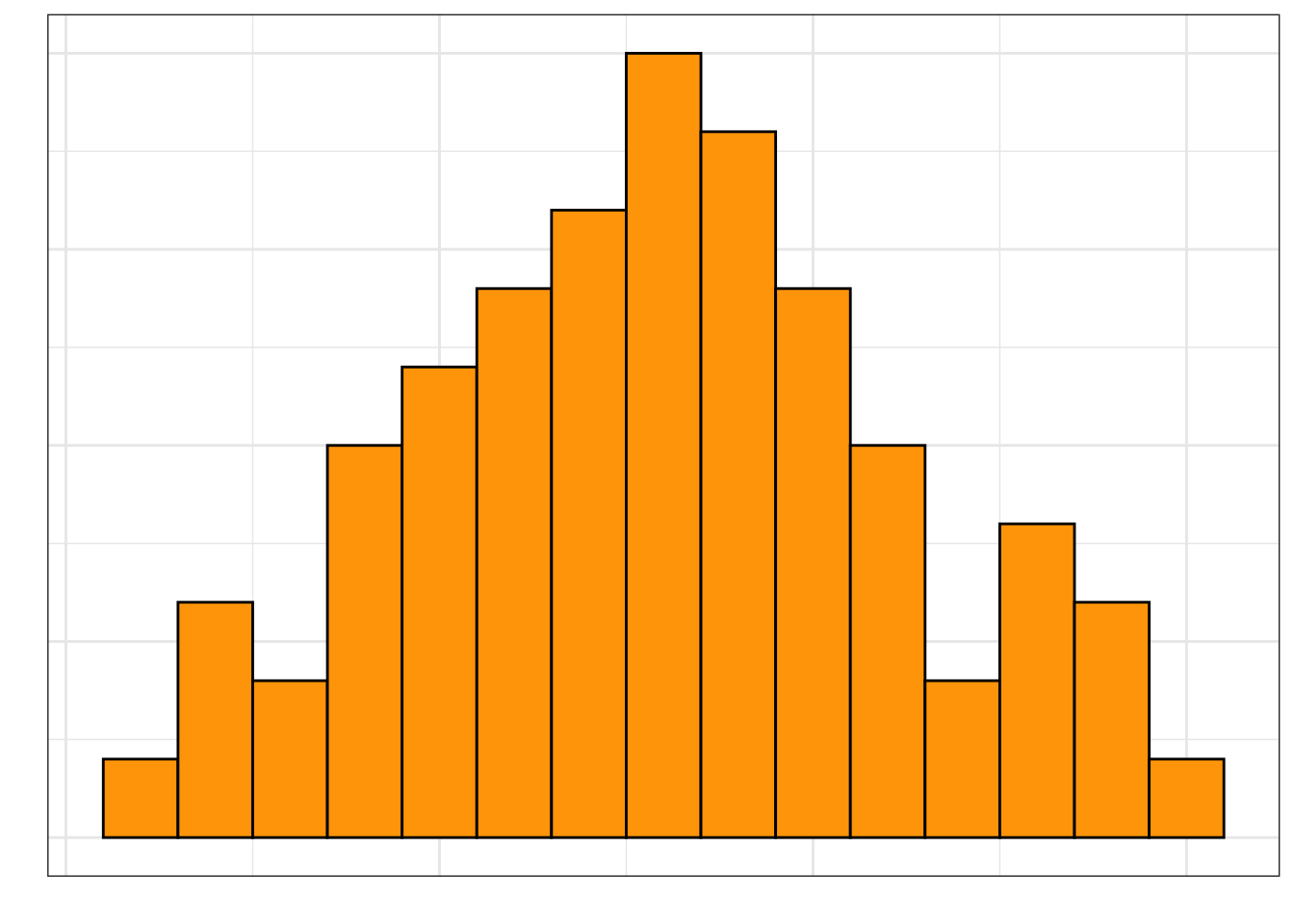
In addition to the overall shape of the distribution, another aspect of shape that we should describe is the number of modes in the distribution. The distributions we have looked as so far have been unimodal, that is, they have a single mode or “hump” in the distribution.
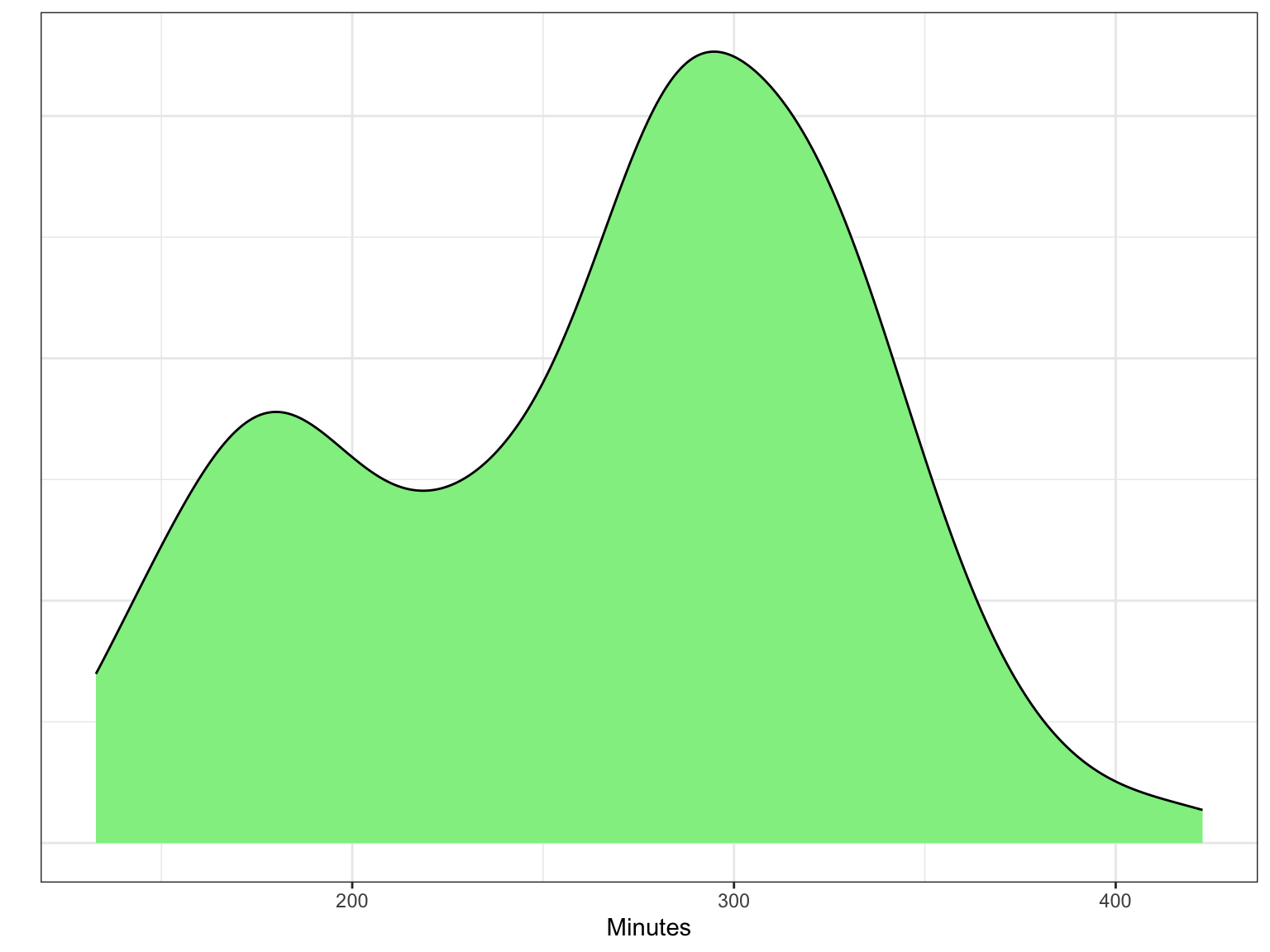
Other distributions have multiple modes. For example, the distribution in Figure 4.8 is bimodal (it has two modes). If a distribution has more than one mode, it often indicates that there are different groups that have been mixed into the data. For example, in Figure 4.8 we see one mode around 180 minutes (3 hours) and another taller mode around 300 minutes (5 hours). This might indicate that there are two different groups of runners that competed in the Legacy Marathon—one smaller group that was faster (e.g., elite runners) and one larger group that was slower.
4.4.1 Center and Variation: Two Additional Characteristics to Describe
In addition to the describing the shape of the distribution, there are two other characteristics of a quantitative distribution that we should describe: the center and the variation.
The “center” of a distribution is misleading in that it doesn’t literally mean the center of the distribution. What it really means is “typical value”. In the distribution of acceptance rates (e.g., Figure 4.5), a typical acceptance rate might be around 65%. This value is at the mode in the distribution.
We also need to describe the variation in the distribution. When estimating the variation from a density plot we typically describe the overall range of values, as well as, the range of values within which most of the data falls. In the distribution of acceptance rates presented earlier, there are acceptance rates between 20% and 96%, but most of the institutions of higher learning have an acceptance rate between 55% and 75%. This could also be given as a range of values around the typical value—\(65\% \pm 10\%\)
In a multi-modal distribution, the identification of center and variation is more difficult, since there are multiple typical values. For example, in the distribution of marathon times presented in Figure 4.8, there are two typical values, one around 180 minutes and another around 300 minutes. Similarly, in describing the variation we often describe a range of values around each typical value that depicts where most of the data fall. From Figure 4.8, most of the faster runners finished the Legacy Marathon between 160 and 190 minutes, whereas most of the slower runners finished with a time between 200 and 400 minutes.
INTERPRETATION
A full description of a quantitative distribution includes shape, number of modes, center, and variation. It also needs to incorporate the context of the data.
Here is how we might describe the distribution of acceptance rates:
The distribution of acceptance rates for Minnesota’s 33 institutions of higher eduction is left-skewed. Most institutions admit a high proportion of applicants. A typical institution in the distribution admits around 65% of its applicants (\(\pm\) 10%). There are, however, a few institutions that are quite selective, admitting fewer than 30% of the students who apply. Similarly there are some institutions that accept almost all of their applicants.
4.5 Using R to Create Histograms
To create a histogram or a density plot, we will use functions from the {ggfomula} library. As a reminder, in the first code chunk of your QMD document, load the {tidyverse} and {ggformula} libraries. Also use the read_csv() function to import the mn-colleges.csv data and assign the data into an object called mn. You also might want to view the data to ensure that it imported into the QMD correctly. (Don’t forget to add code comments as well!)
# Load libraries
library(ggformula)
library(tidyverse)
# Import data
mn <- read_csv("data/mn-colleges.csv")
# View data
mnTo create a histogram of the acceptance rates using the gf_histogram() function, we will first create a new code chunk in your QMD document where you want the histogram to appear. Inside the code chunk we will add the following syntax:
gf_histogram(~accept_rate, data = mn)- The first argument is a formula using the tilde operator (
~) that identifies the attribute to be plotted. In our example, the name of the attribute isaccept_rate. (Make sure you use the exact name of the attribute, including correct case and spelling!) - The second argument,
data =, specifies the data object that was assigned on data import. Earlier in the QMD file you should have imported the mn-colleges.csv file and assigned it into an object. In our example, we assigned it into an object calledmn.
This should result in the following histogram:
`stat_bin()` using `bins = 30`. Pick better value `binwidth`.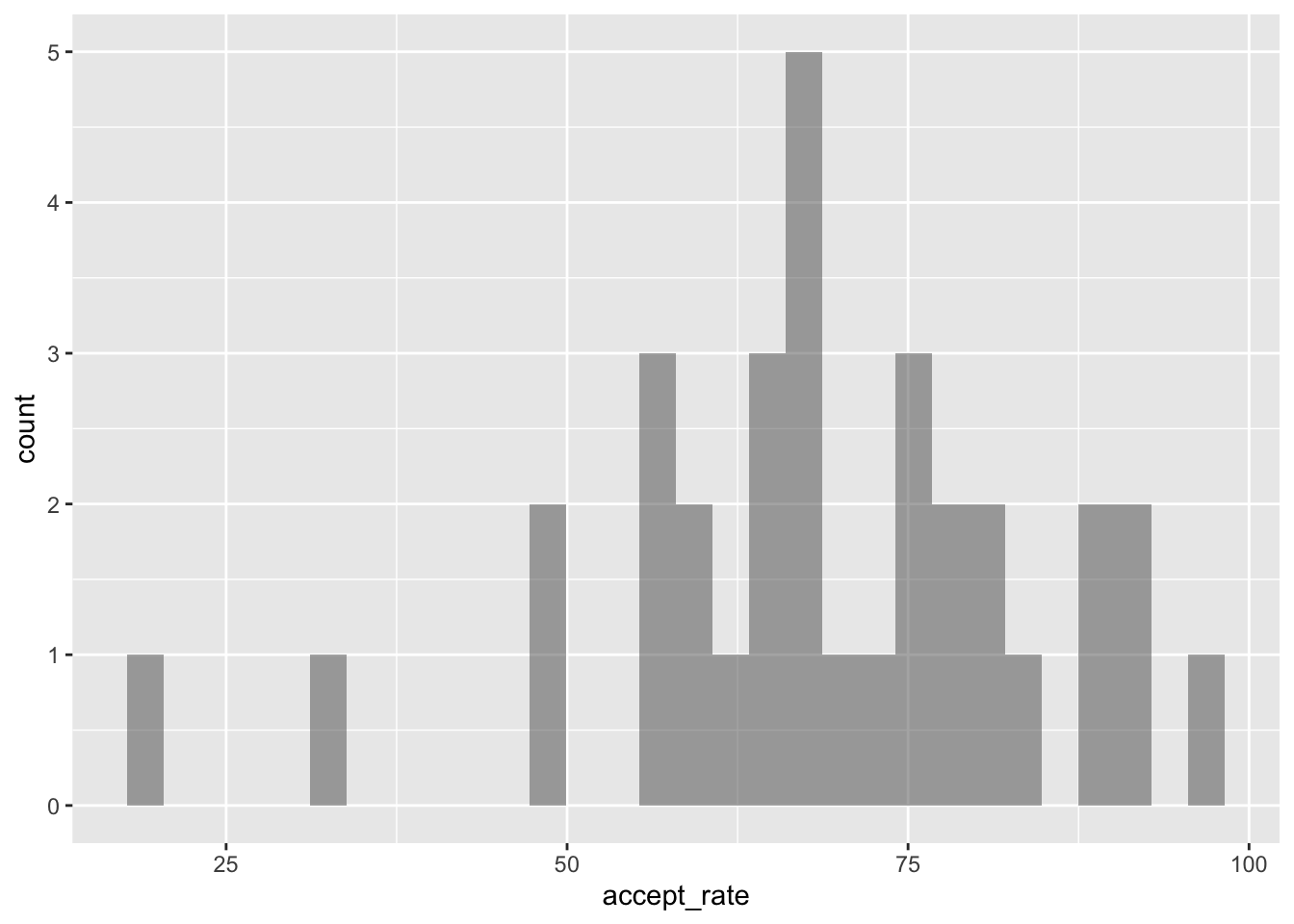
A couple things to note.
- While the bars in the histogram are there, because we haven’t made their border visible, some bars look wider than others.
- You will likely have a message saying “
stat_bin()usingbins = 30. Pick better valuebinwidth”. This is because R by default chooses to create the bin width so that there are 30 bins in the histogram. Sometimes this is fine, other times we want more control over the bins.
4.5.1 Adding Border and Bar Color
To show the histogram bins more clearly, we can color the bin lines (the bar borders) to highlight the different bins. To do this we include an additional argument, color=, in the gf_histogram() function. We can also set the color for the bars themselves using the fill= argument. Here we color the bin lines black and set the bar color to yellow. Recall that since “black” and “yellow” are strings, we enclose them in quotation marks in the function.
`stat_bin()` using `bins = 30`. Pick better value `binwidth`.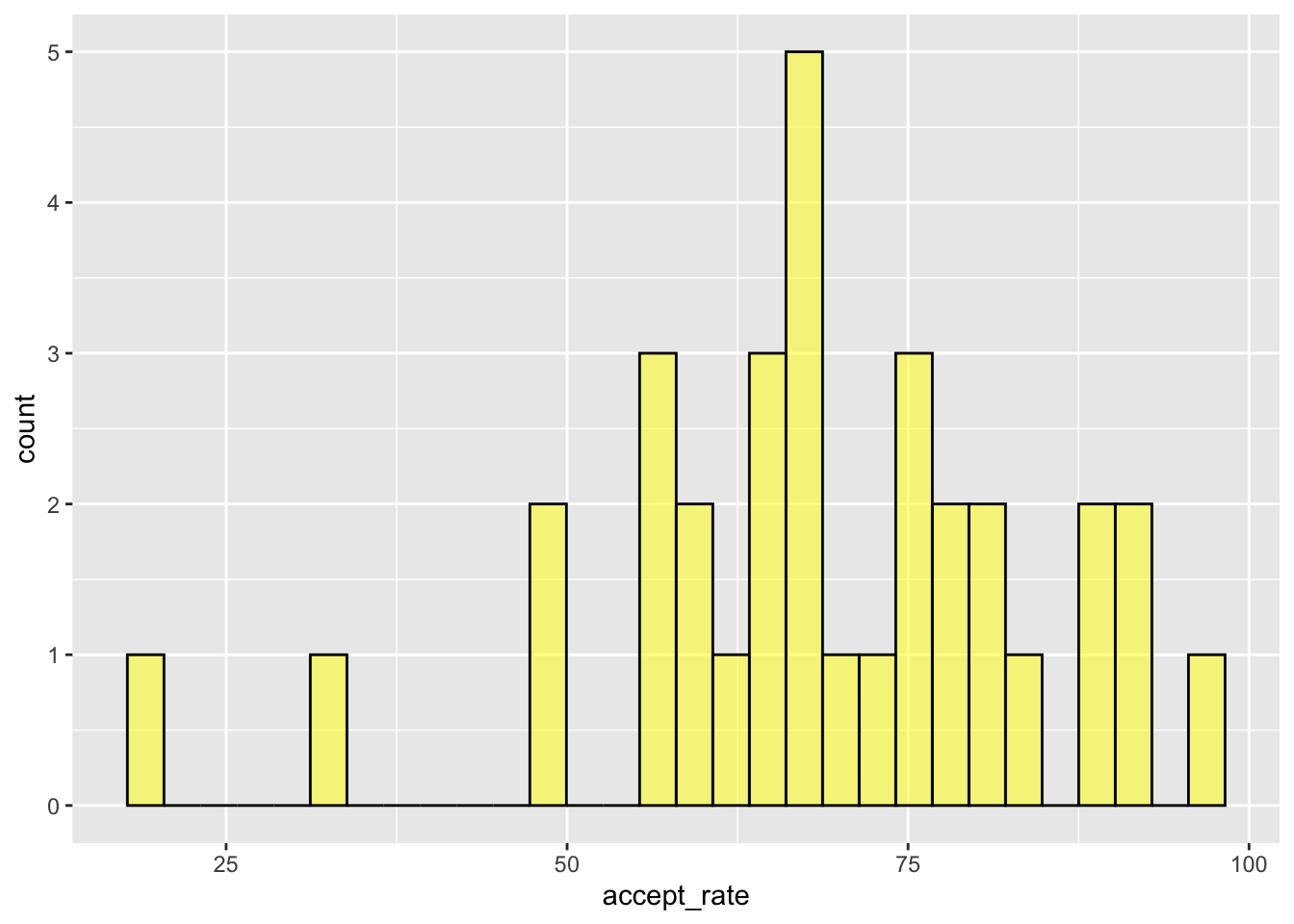
There are 657 different color names that R knows. These are depicted in Figure 4.11.

4.5.2 Changing the Bin Width
To change the number of bins, we add the argument bins= to the gf_histogram() function. For example, if we wanted there to be 10 bins rather than the 30 default bins, we would use the following syntax:
gf_histogram(~accept_rate, data = mn, color = "black", fill = "yellow", bins = 10)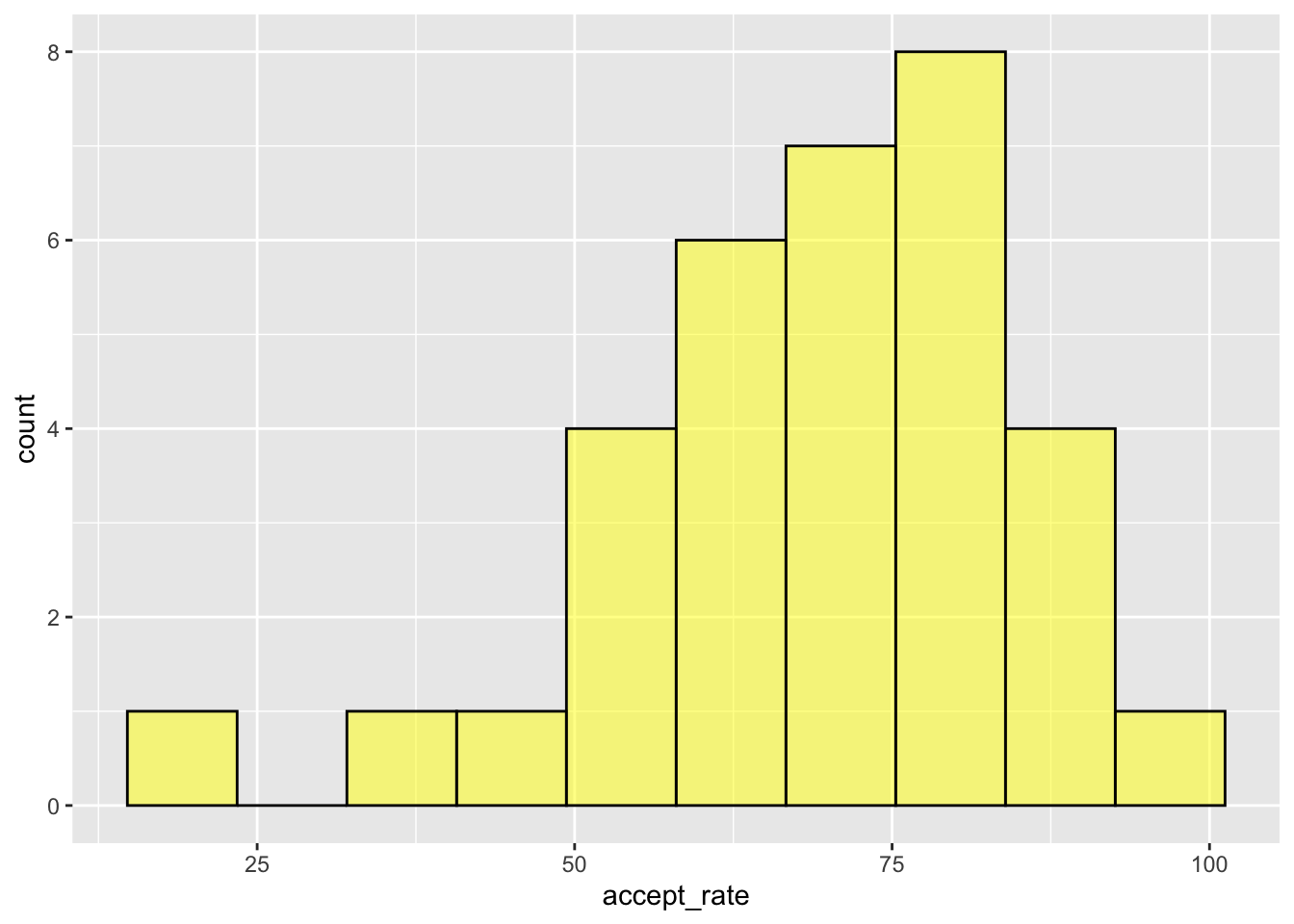
By changing the number of bins we are changing how wide each bin actually is. The way R computes the bin width is to take the maximum value in the data and subtract the minimum value in the data, and then divide it by the number of bins. In our example, the maximum acceptance rate in the data is 96.90 and the minimum acceptance rate is 19.10. So for the default of 30 bins:
\[ \mathrm{Bin~Width} = \frac{96.90 - 19.10}{30} \approx 2.59 \] So the first bin would include values between 19.10 and 21.69. The second bin would include values from 21.69 and 24.28. Etc.
When we used 10 bins the bin width was:
\[ \mathrm{Bin~Width} = \frac{96.90 - 19.10}{10} \approx 7.78 \] In this histogram the first bin would include values between 19.10 and 26.88. The second bin would include values from 26.88 and 34.66. Etc.
Rather than choosing the number of bins, you can instead choose the desired bin width by including the argument binwidth= in the gf_histogram() function. For example, to choose a bin width of 1, we could use the following:
gf_histogram(~accept_rate, data = mn, color = "black", fill = "yellow", binwidth = 1)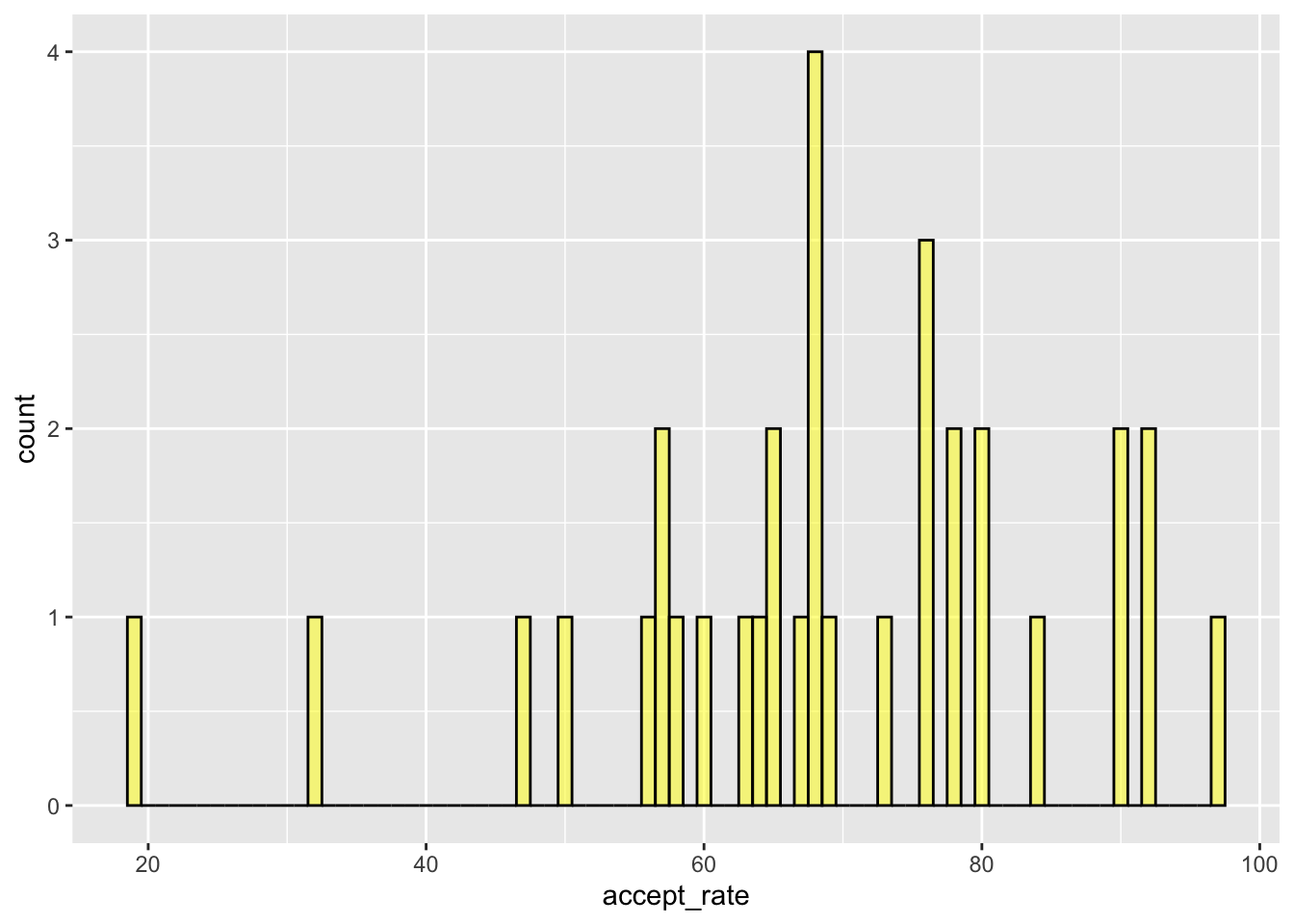
PROTIP
In the gf_histogram() function you cannot include both bins= and binwidth=. Use one or the other. If you include both, R will use whichever one appears first in the function and will ignore the other argument.
As the storyteller of the data, it is up to you to determine an appropriate bin width or number of bins for the quantitative attribute you are visualizing. There is no one correct bin width or number of bins. Usually the main concept being communicated with a histogram is its shape. So the key is to choose the bin width/number of bins so that we can get a good sense of the shape of the distribution.
To do that, you generally want to find the middle ground between each data value being its own bar in the graph (binwidth=1) and the data being grouped so there is only a single bar (binwidth= the range of the data). It is common to try different bin widths/number of bars and see how the histogram changes. You will notice when you are close to an appropriate bin width that making the bin a little wider or narrower really does not change the overall appearance of the graph.
4.6 Using R to Create Density Plots
The syntax for creating a density plot, is quite similar to that for creating a histogram, except we use the gf_density() rather than the gf_histogram() function. Start by creating a new code chunk to hold the syntax for your density plot. Then, in the code chunk, add the following syntax.
gf_density(~accept_rate, data = mn)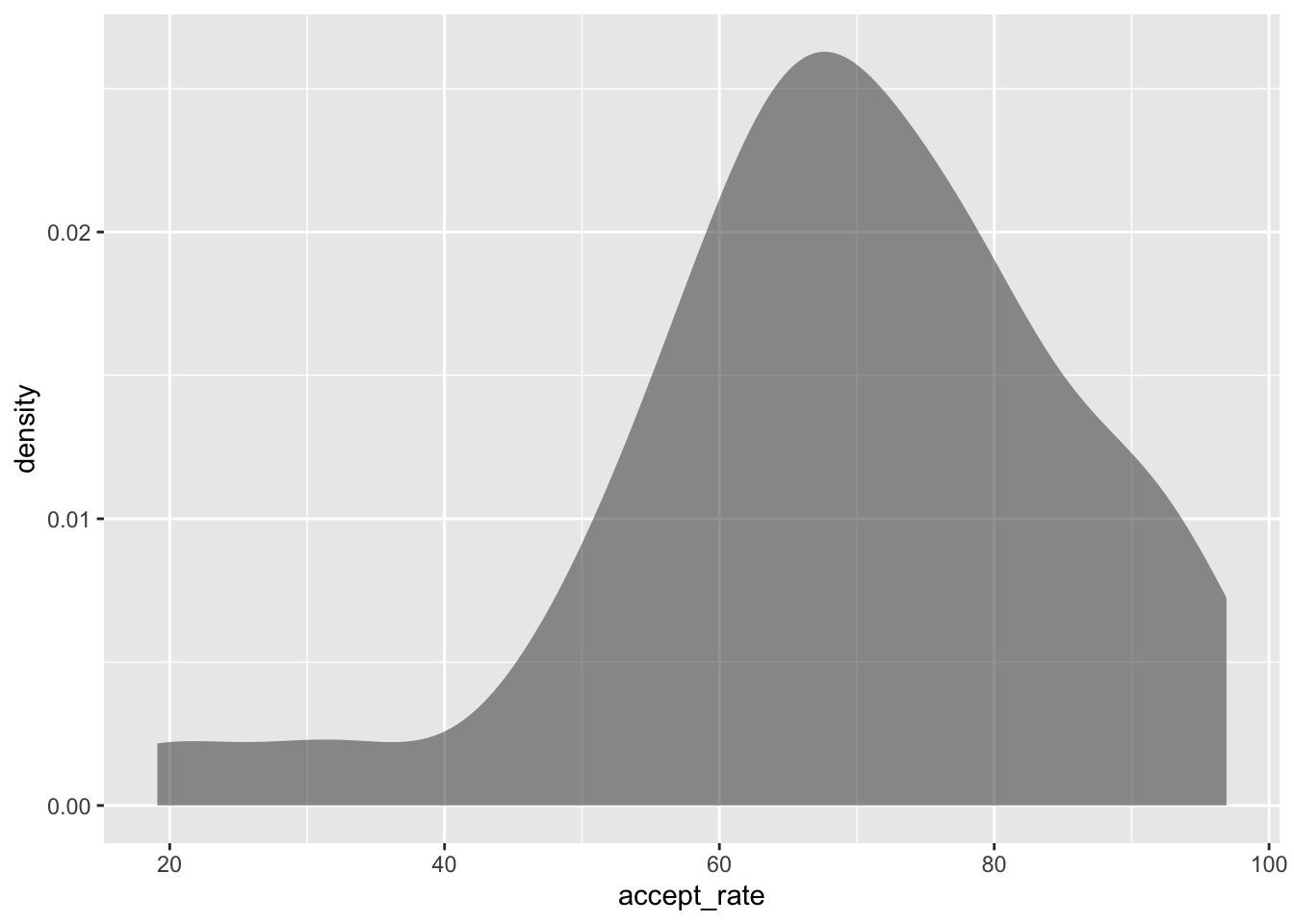
The main two arguments for this function are identical to those in gf_histogram(). Namely,
- The first argument is a formula using the tilde operator (
~) that identifies the attribute to be plotted. - The second argument,
data =, specifies the data object that was assigned on data import.
Similar to the histogram, we can also specify the color= and fill= arguments in the gf_density() function. The color= argument specifies the border color of the density plot and fill= specifies the interior color of the density plot.
gf_density(~accept_rate, data = mn, color = "black", fill = "yellow")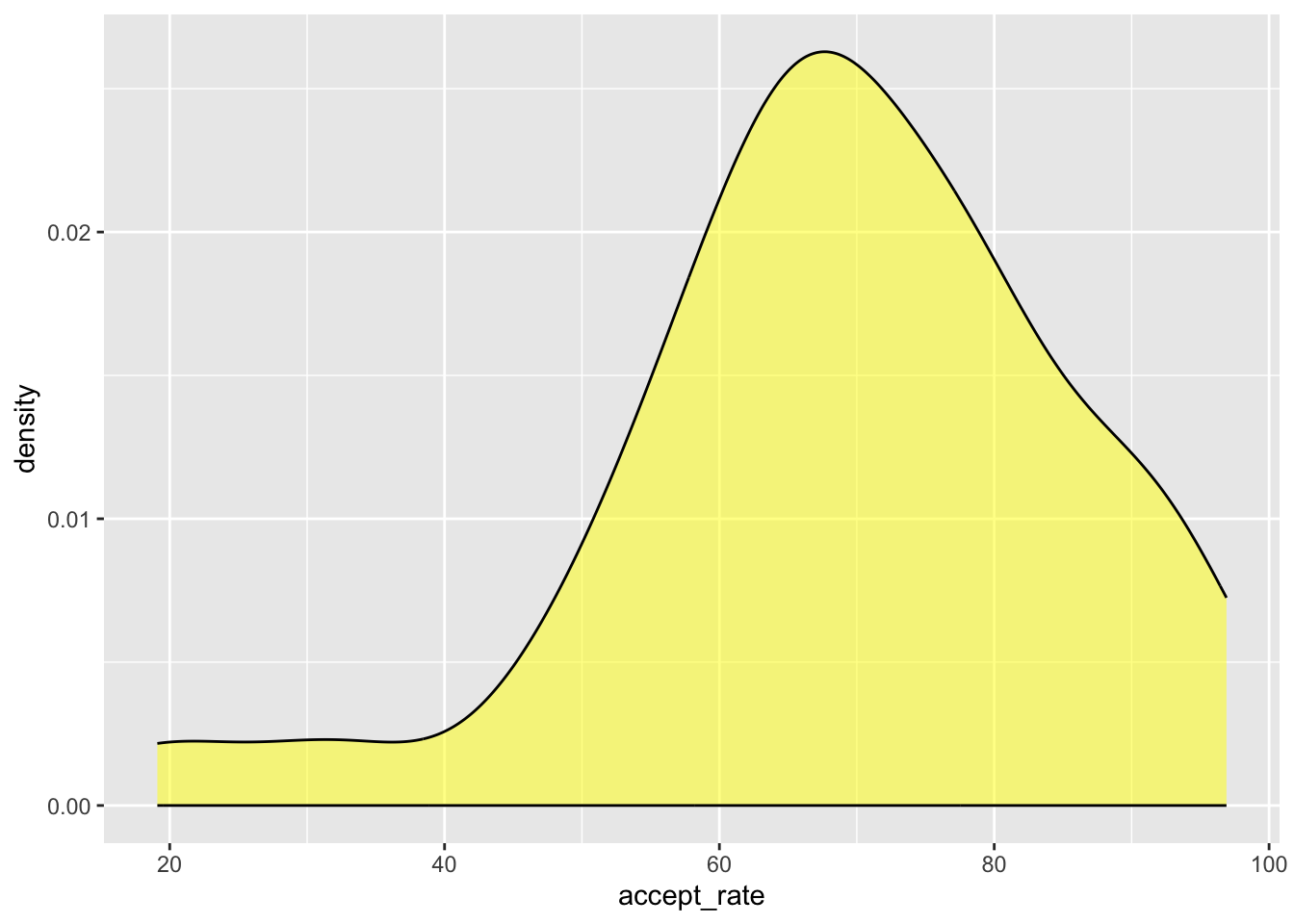
Deciding between using a histogram or density plot to visualize a quantitative attribute is really the data scientist’s choice. One advantage of the density plot over the histogram is that we don’t have to worry about changing the bin width. A disadvantage is that the idea of density is quite technical and will likely be more difficult for people to understand than counts. However, there is no right or wrong as they both allow people to understand the attribute by visualizing the shape, center, and variation of the distribution.
Exercises: Your Turn
- Create a histogram of the number of applicants (
applicants) for the 33 institutions of higher learning in Minnesota. Color the bin lines of the histogram maroon and color the bars gold.
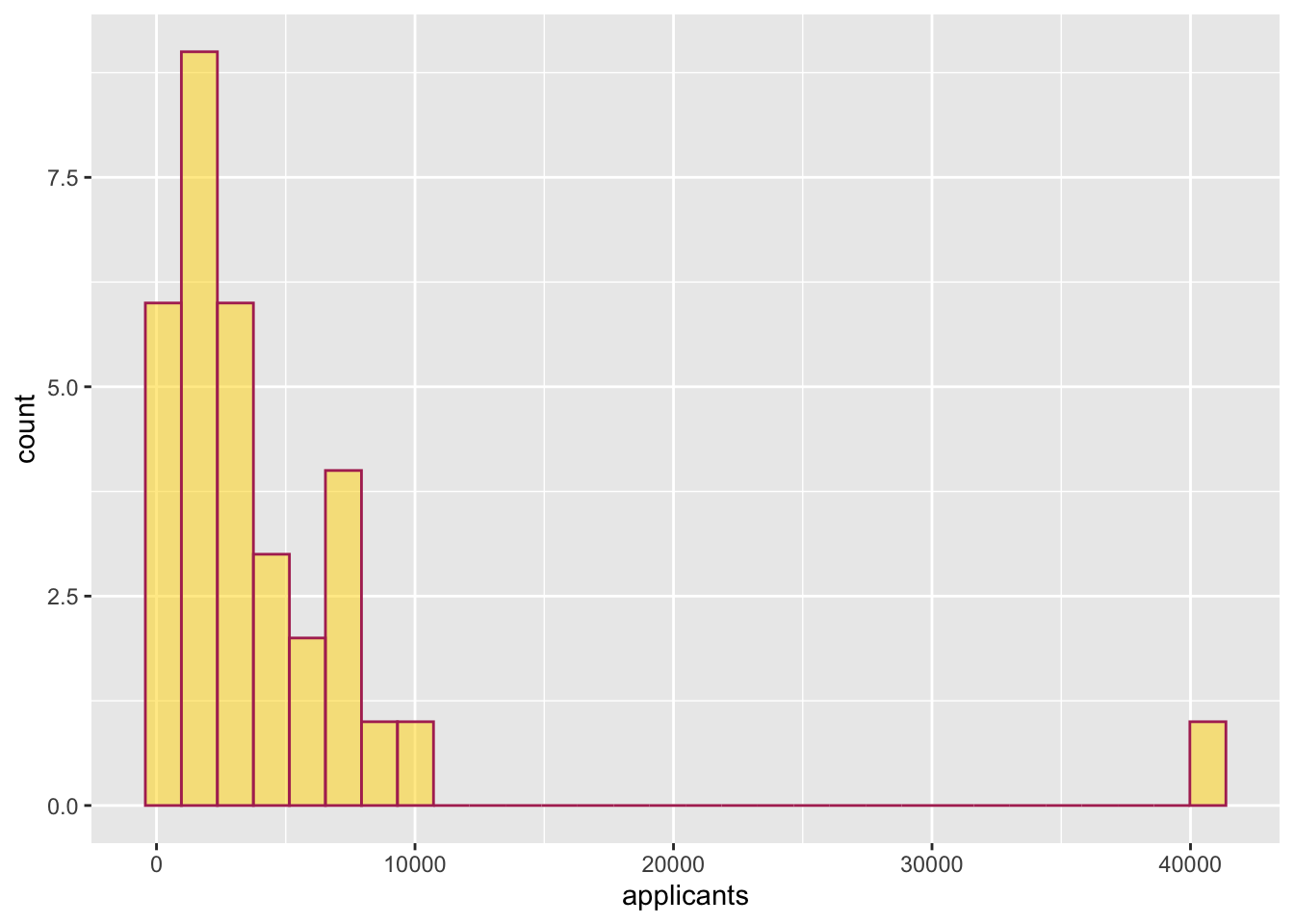
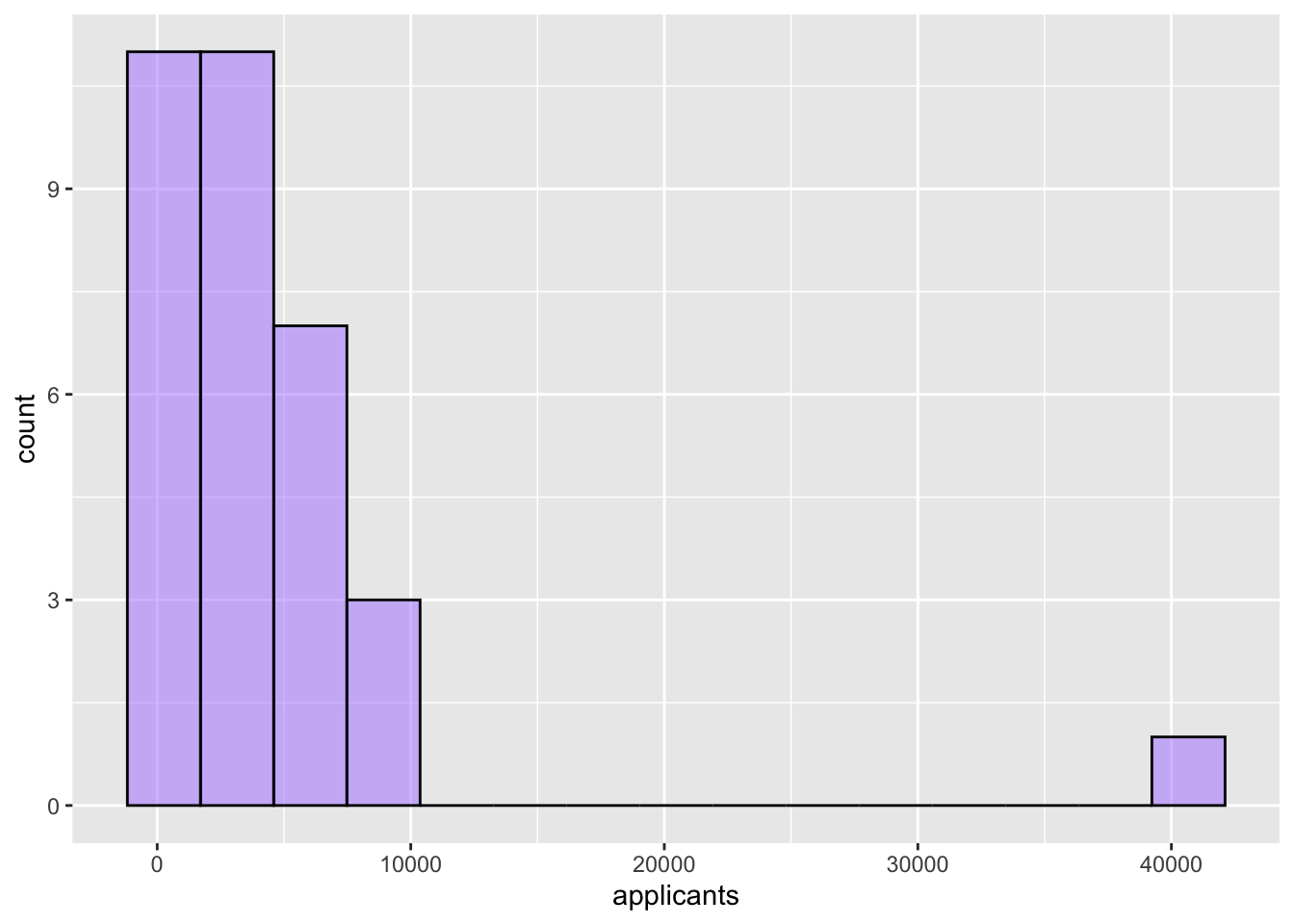
- Create another histogram of the number of applicants (
applicants) for the 33 institutions of higher learning in Minnesota. But this time use only 15 bins. Color the bin lines of the histogram black and pick a fun color to fill the bars.
- The following histogram displays the number of applicants for the 33 institutions of higher learning in Minnesota. The first bar has a height of 13. Interpret what that means using the context of the problem.
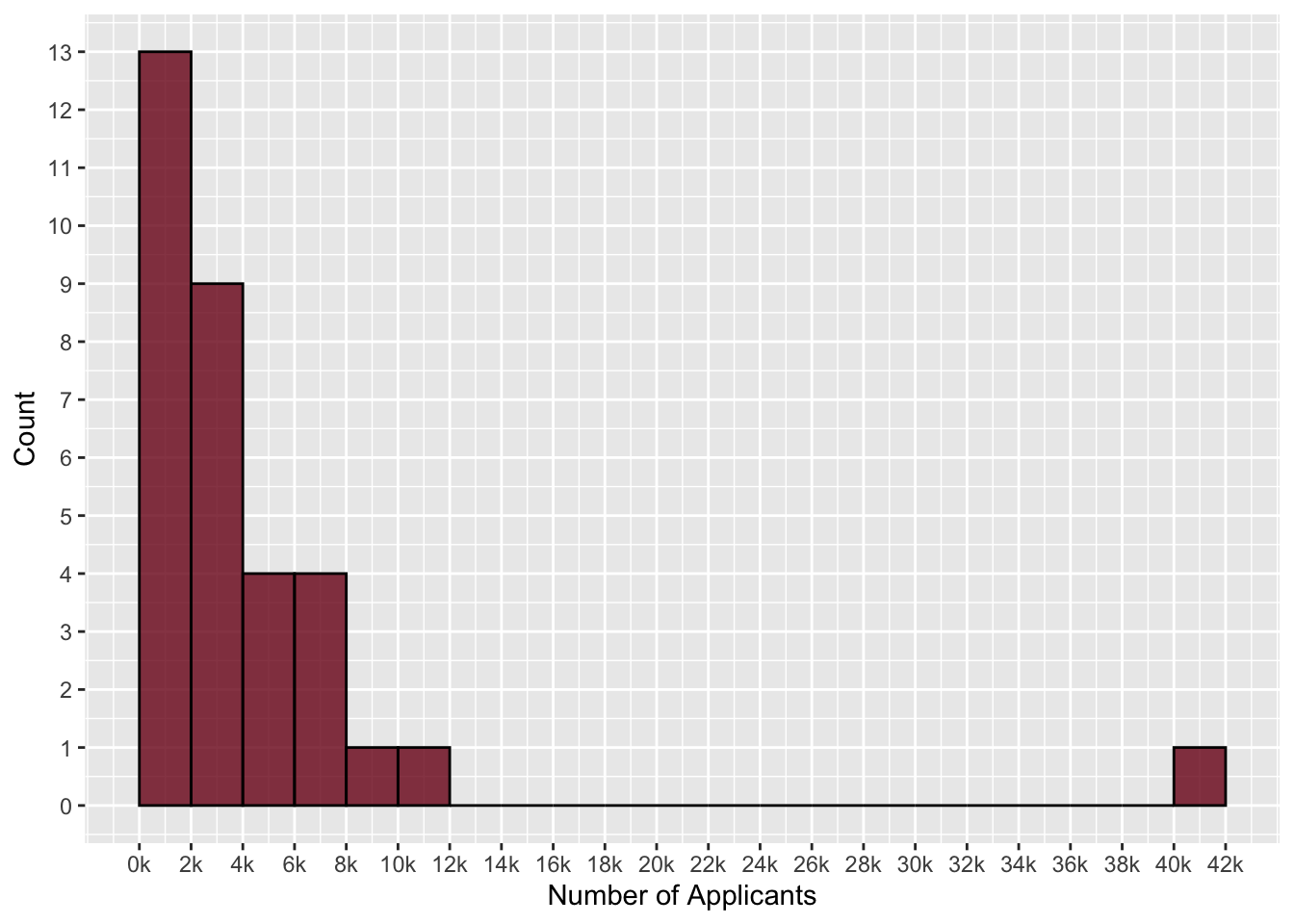
- Create a density plot of the number of applicants for the 33 institutions of higher learning in Minnesota. Fill the density plot with a color of your choice. Also color the border with a color of your choice.
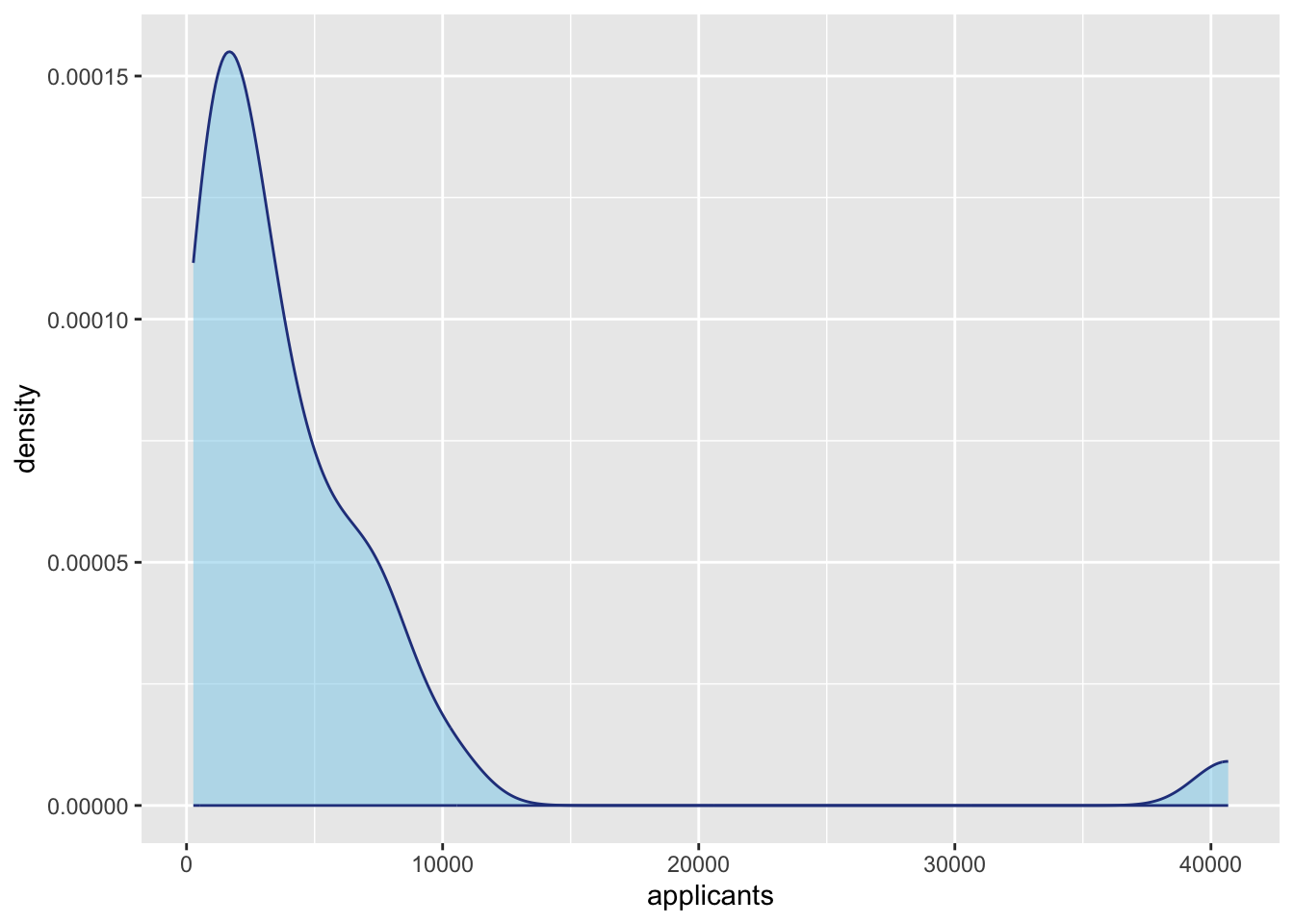
- Use the density plot to describe the distribution of the number of applicants for the 33 institutions of higher learning in Minnesota. Be sure to describe the shape, center, and variation of this distribution. Also be sure to incorporate the context into your description.