
5 Visualizing and Describing Categorical Attributes
This chapter will focus on the visualization and description of categorical attributes.
5.1 Hypothetical Example: Pet Ownership
Imagine you have surveyed 10 pet owners about the type of pet they own.1 The data you collected is shown in Figure 5.1.
Our goal in exploratory analysis is to describe the data. One way of describing the data is to list all of the values. For example here we could say the sample included a turtle, a fish, a cat, a dog, another dog, another fish, another cat, another cat, another cat, and another dog. While this is an accurate description, it isn’t very generalizable. (Imagine trying to describe the data from 1000 pet owners or 10,000 pet owners!)
5.2 Describing Categorical Attributes
A more natural way to describe these data is to summarize them by providing counts of each pet type. For example, describing our sample data using counts:
- 1 of the pet owners sampled owned a turtle,
- 2 of the pet pet owners sampled owned a fish,
- 3 of the pet pet owners sampled owned a dog, and
- 4 of the pet pet owners sampled owned a cat.
Summarizing each type of pet owned by reporting counts of them is a much more natural way of describing the data. (This is also useful when the sample size is much larger.) We also use this summary to viualize the data.
5.3 Visualizing Categorical Attributes
To visualize categorical attributes we typically use a bar chart. A bar chart (also known as a bar graph or a bar plot) shows a bar for each category of the categorical attribute. The height of the bar indicates the count (or proportion or percentage) of each category. Figure 5.2 shows a bar chart of the pet data.
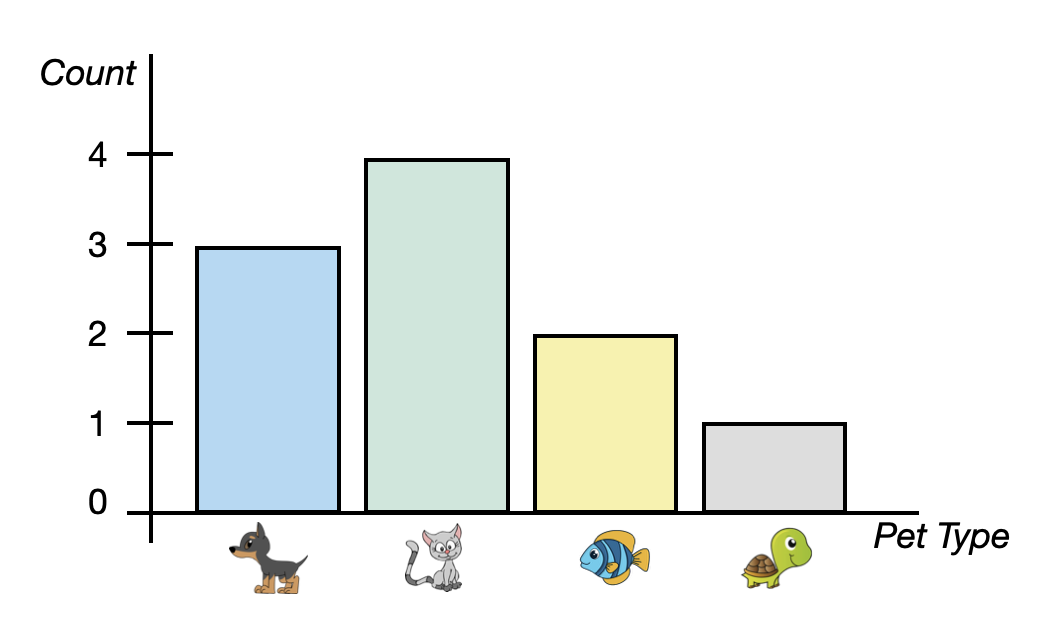
The bar chart in Figure 5.2, includes four bars, one for each pet type. This bar chart is summarizing counts which is depicted on the y-axis. Each bar indicates the count of pet owners who own that type of pet. For example, the bar for cats has a height of four on the y-axis since four pet owners own a cat.
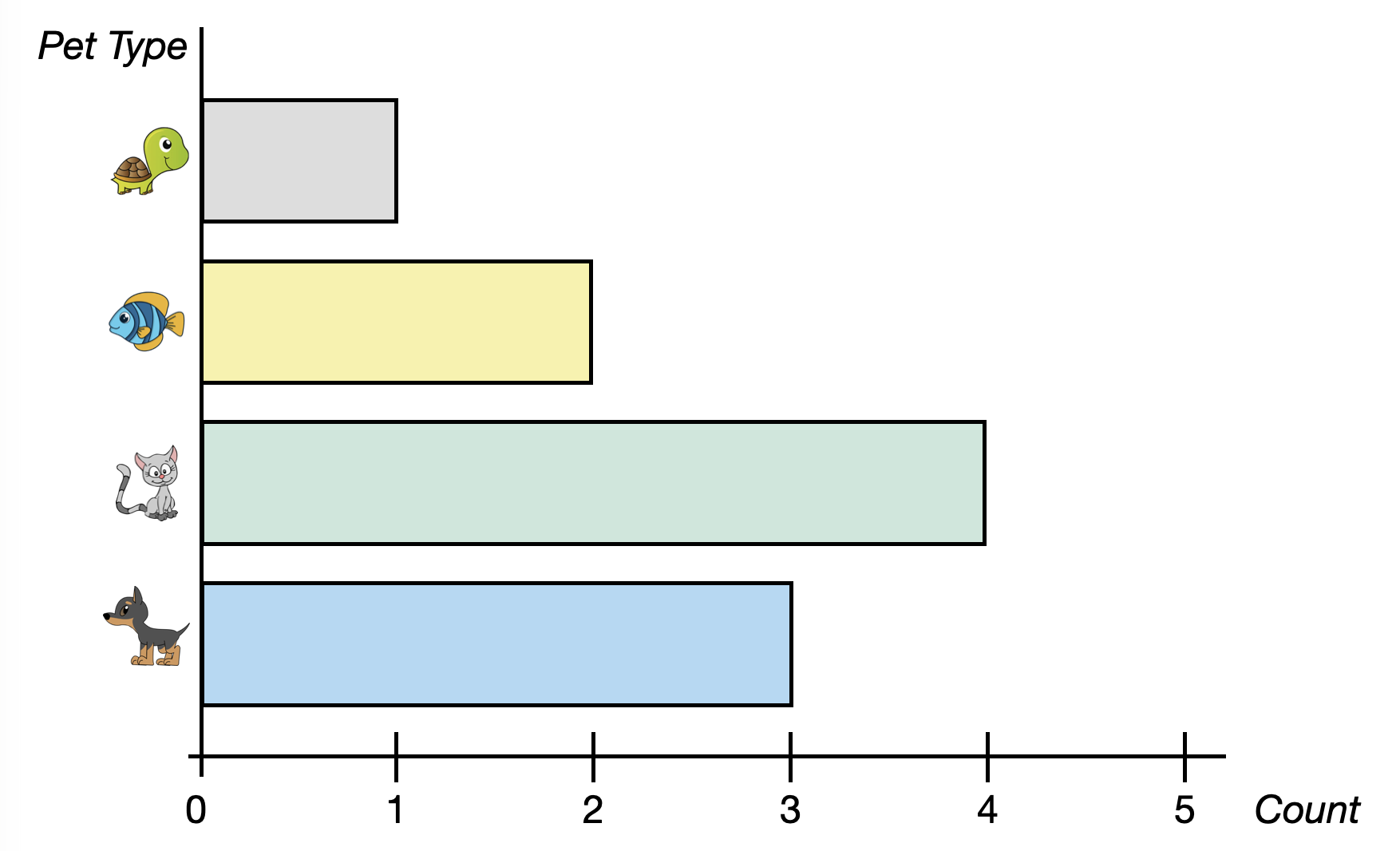
Sometimes the axes in the bar chart are transposed; categories are placed on the y-axis and counts on the x axis. This is referred to as a horizontal bar chart. Figure 5.3 shows a horizontal bar chart indicating the number (count) of each pet type.
5.4 Two Alternative Methods to Summarize Categorical Attributes
Two other ways in which we summarize and visualize categorical attributes are to use proportions or percentages rather than counts.
5.4.1 Proportions
To compute the proportion of each pet type owned, we take the count of each type of pet owned, and divide it by the total sample size.
\[ \mathrm{Proportion} = \frac{\mathrm{Count~of~Pet~Type}}{\mathrm{Total~Sample~Size}} \]
For example, to compute the proportion of pet owners in our sample that owned a dog, we use:
\[ \mathrm{Proportion~of~Dogs} = \frac{3}{10} = 0.30 \]
FYI
Proportions will always be between 0 and 1. If you add all of the proportions of each category together you will get 1, so long as values can only belong to one category.
Describing our sample data using proportions:
- 0.10 of the pet owners sampled owned a turtle,
- 0.20 of the pet pet owners sampled owned a fish,
- 0.30 of the pet pet owners sampled owned a dog, and
- 0.40 of the pet pet owners sampled owned a cat.
Table 5.1 indicates the counts and proportions of values in our hypothetical pet example.
| Pet | Count | Proportion |
|---|---|---|




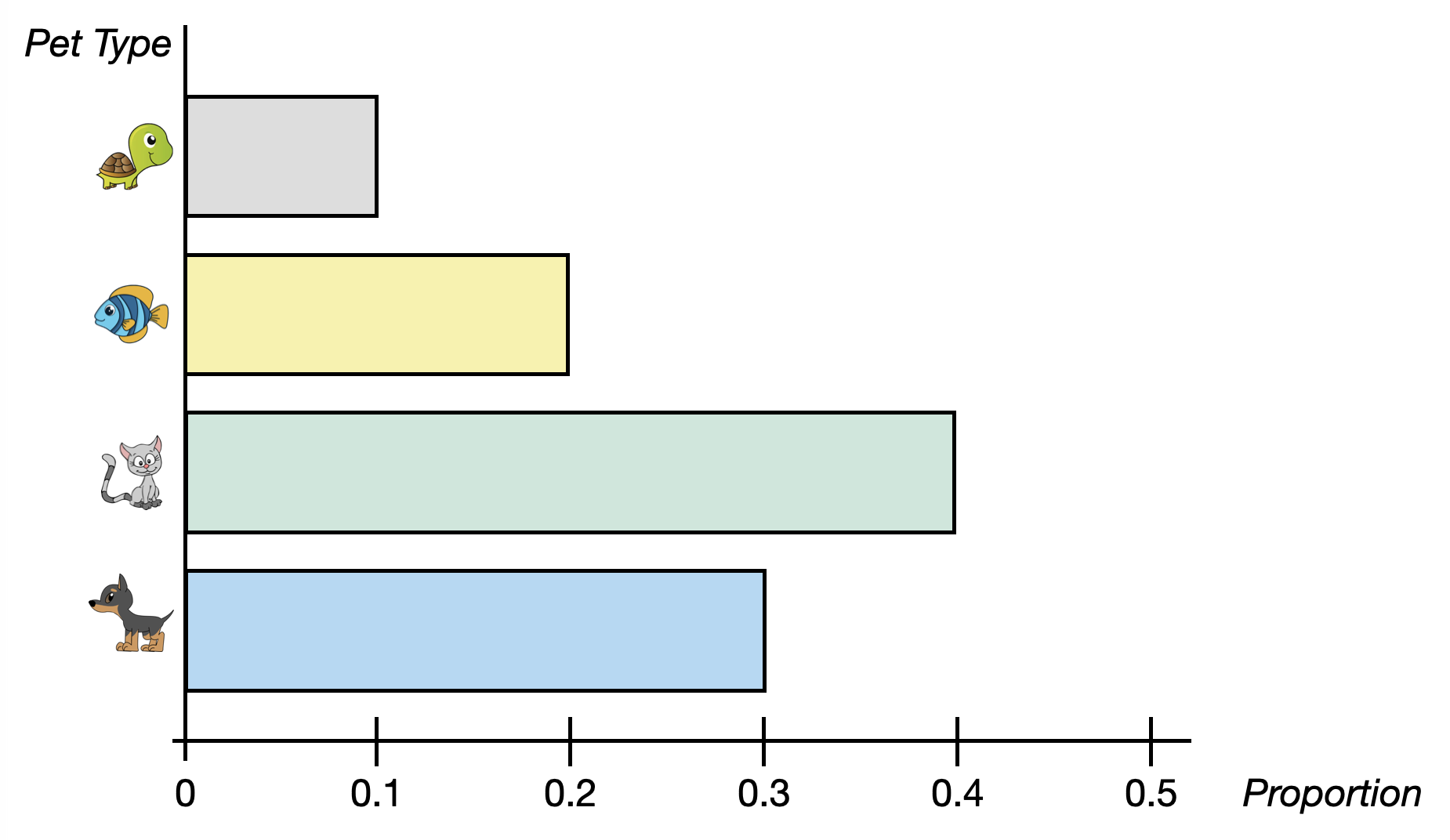
We can also create a bar chart that visualizes the proportions rather than the counts. Similar to the bar charts of counts a bar chart of the proportions can be vertical or horizontal. Figure 5.4 shows a horizontal bar chart of the proportion of each pet type owned.
5.4.2 Percentages
We know from research on people’s reasoning that proportions are difficult for people to reason about. Because of this, we often summarize categorical attributes using percentages rather than proportions. To compute the percentage of each pet type owned, we take the count of each type of pet owned, and divide it by the total sample size and then multiply this by 100.
\[ \mathrm{Percentage} = \frac{\mathrm{Count~of~Pet~Type}}{\mathrm{Total~Sample~Size}} \times 100 \]
For example, to compute the percentage of pet owners in our sample that owned a dog, we use:
\[ \mathrm{Percentage~of~Dogs} = \frac{3}{10} \times 100 = 30\% \]
| Pet | Count | Proportion | Percentage |
|---|---|---|---|
FYI
Percentages will always be between 0 and 100. If you add all of the percentages of each category you will get 100, so long as values can only belong to one category.
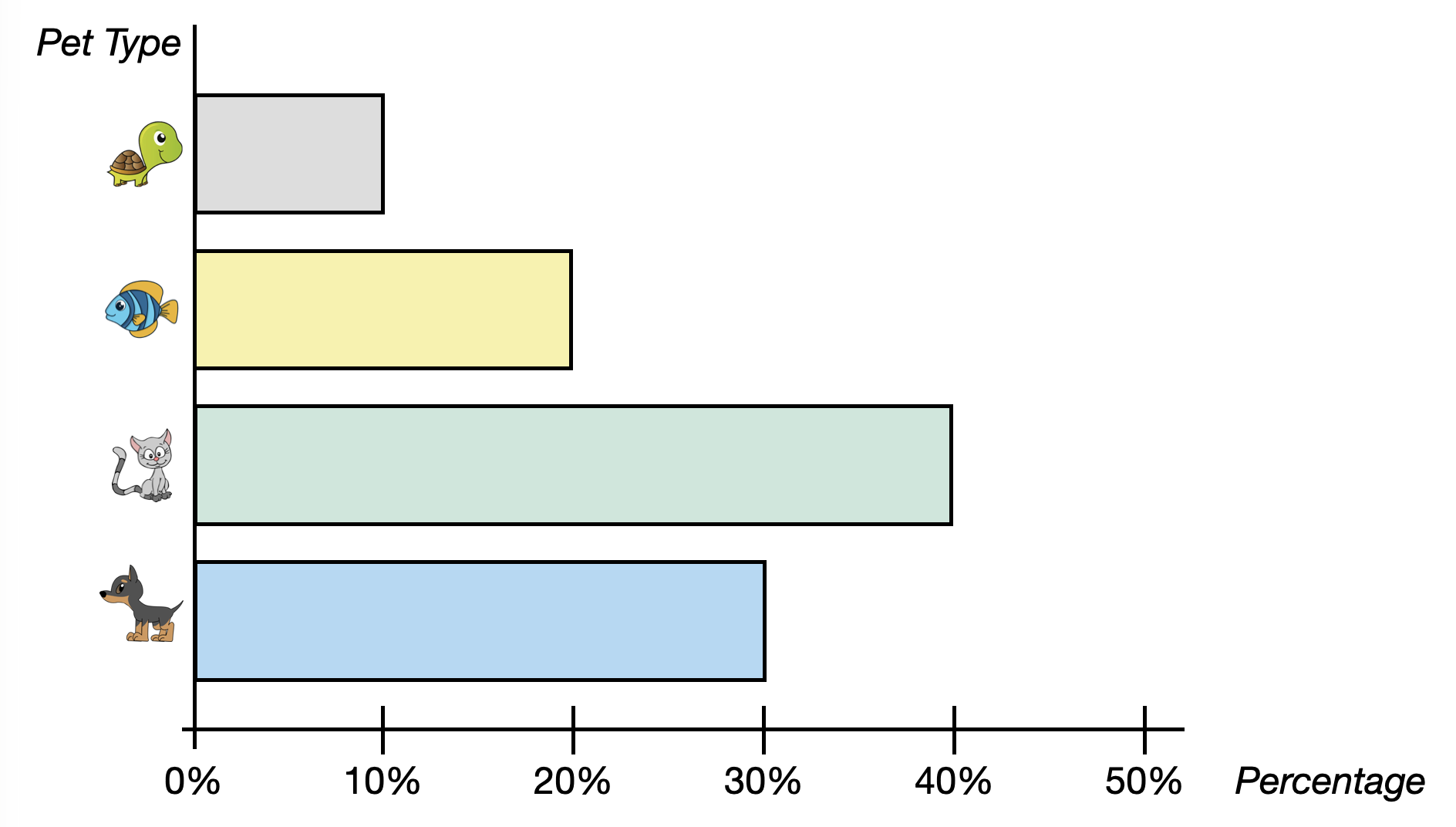
We can also create a bar chart using percentages. Figure 5.5 shows a horizontal bar chart of the percentage of each pet type owned.
5.4.3 Counts, Proportions, or Percentages: Deciding How to Summarize the Data
How you summarize a categorical attribute—using counts, proportions, or percentages—is up to you. Each has advantages and pitfalls. Using proportions or percentages are useful since they provide a standard scale for measuring size. This can be especially useful if you are comparing two different groups that have different sizes. However, counts are often better for communication or when dealing with very small samples where a percentage might misrepresent the scale of the data. This is a choice that you need to make based on what makes the most sense given the context of the data and the question you are trying to answer with your data.
Looking at the bar chart for each summarization, the overall distribution looks the same. The bars are the same relative lengths regardless of whether you use counts, proportions of percentages. This implies that our description of the distribution will essentially be the same regardless of the summary measure we choose.
5.5 Describing the Distribution
With quantitative attributes we described the distribution using shape, center (typical value), and variation. With categorical variables we are more restricted in how we can describe the distribution. To begin with, we cannot describe the shape of a categorical attribute. This is because the order of bars is arbitrary. To illustrate consider the initial bar chart of pets we considered and the variation of this below.
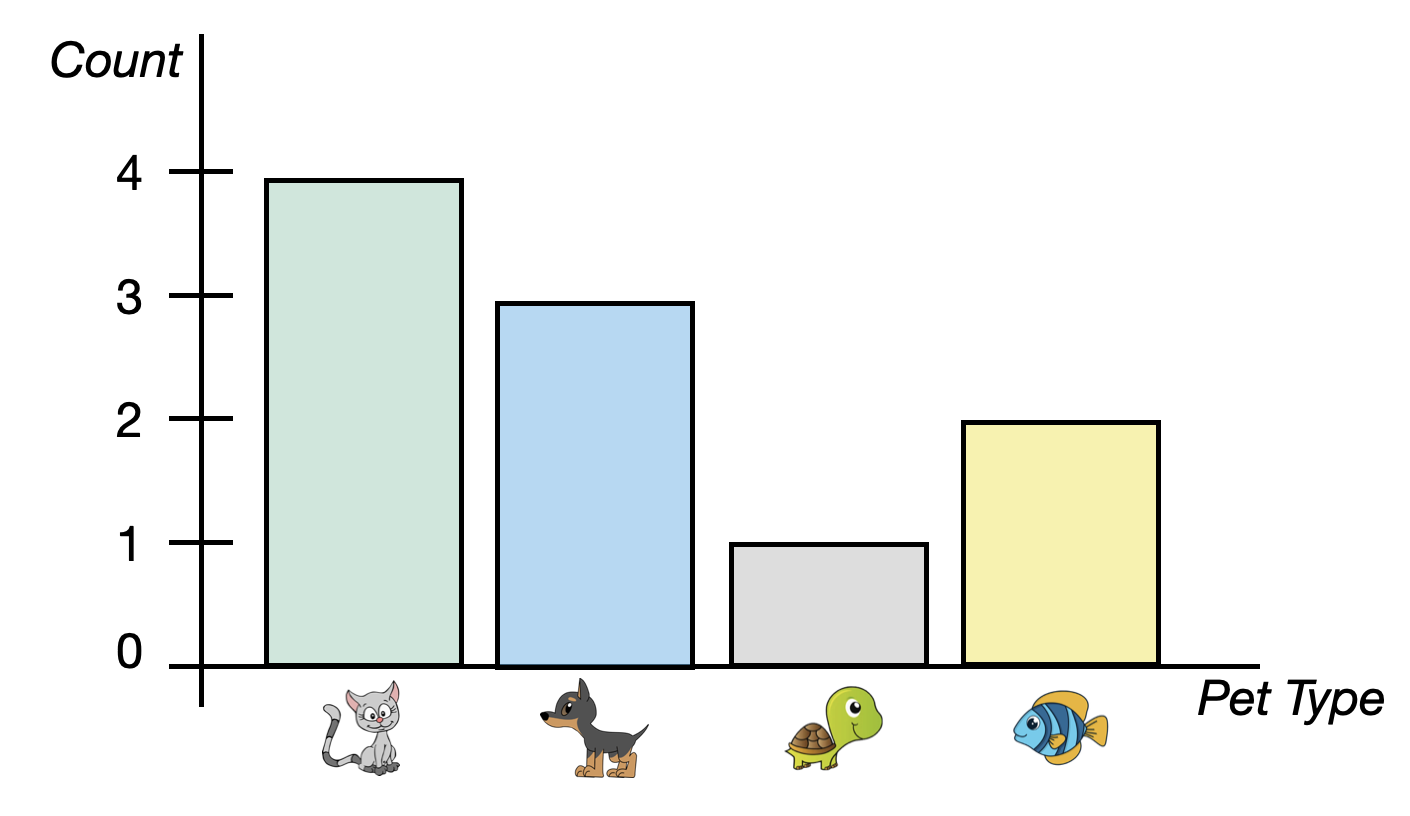
Because the attribute being plotted on the x-axis is categorical, the order we put it in is irrelevant. Cats could be the first bar. dogs could be the first bar. Or fish or turtles. (This is quite different from a histogram of a quantitative attribute in which the values being plotted (numbers) have a distinct order.) Depending on which order we put the pets in the plot, the shape would change. That is why we cannot describe the shape of a categorical attribute.
Despite not being able to describe the shape, we can describe the center of a distribution of a categorical attribute. The typical value (center) that we describe with a categorical attribute is the mode. In our pet example cats are the pet that is owned most often.
The way we described variation for a quantitative attribute—describing the overall range and the range for most cases—does not work as well for categorical attributes. Instead, we need to think about how similar or dissimilar the counts/proportions for the different categories compare. For example, consider the following two plots of pet ownership.
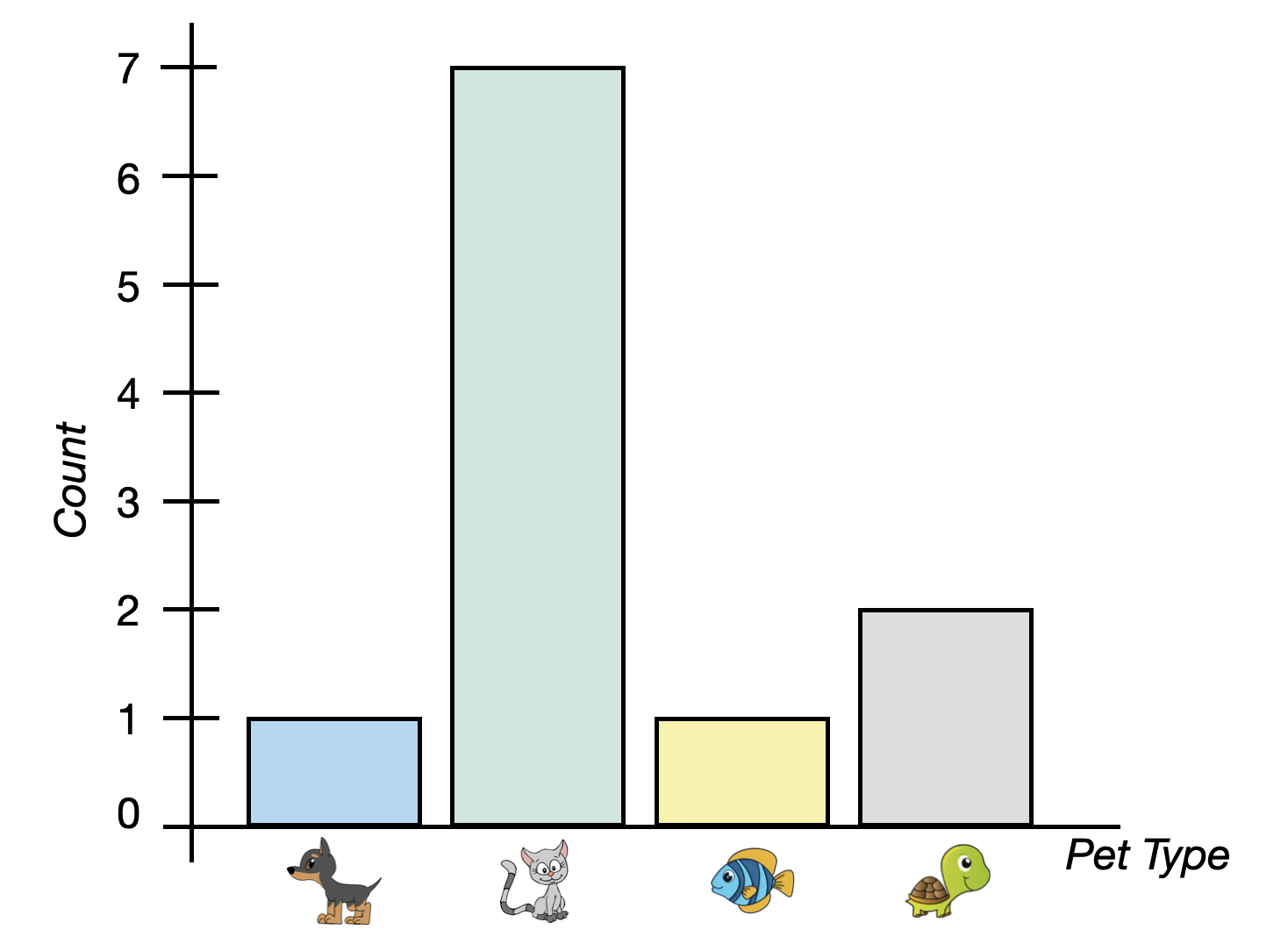
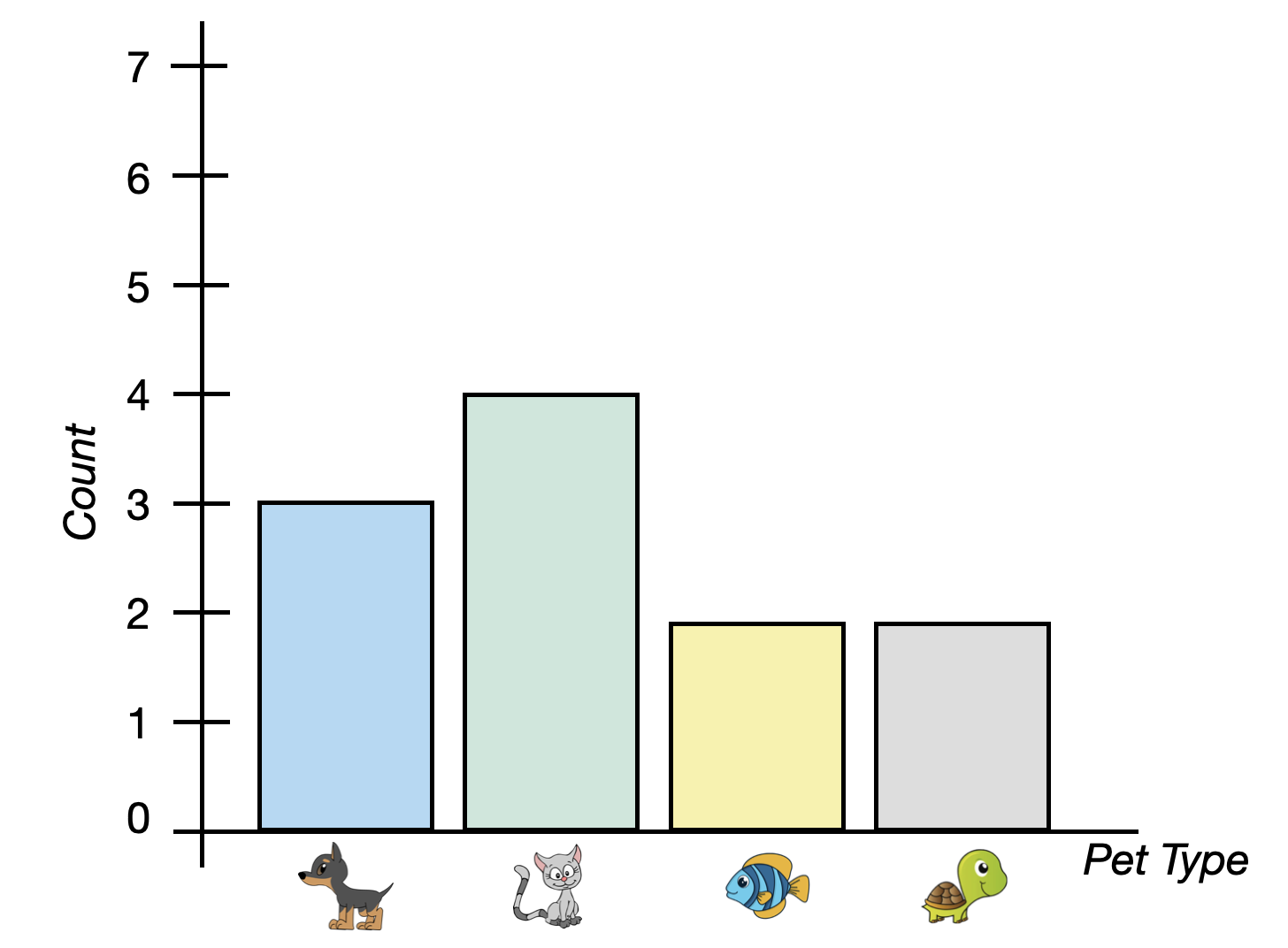
In both plots, there are 11 total pet owners and cats are the typical (modal) pet owned. The best way to think about variation in a categorical attribute is to think of it like “diversity”. In our example, we would ask “how diverse are the types of pets that people own?”
The left bar chart shows a distribution that has a low amount of variability. That is, there is not a lot of diversity in the types of pets these 11 people own—almost all of the pets owned are cats. When you see a bar chart with one very tall bar and the rest are relatively short, that indicates a lack of diversity across the categories and low variability. In contrast, the bars in the bar chart on the right are all of similar heights. This plot indicates there is a lot of diversity in the types of pets these people own. Some own cats, some own dogs, some fish, and others turtles. We would say that there is a high amount of variability in this distribution.
5.6 Using R to Create a Bar Chart of Counts
To illustrate how we use R to create a bar chart, we are going to explore a data set (umn-buildings.csv) that includes data on all the buildings owned by the University of Minnesota. As a reminder, in the first code chunk of your QMD document, load the {tidyverse} and {ggformula} libraries. Also use the read_csv() function to import the umn-buildings.csv data and assign the data into an object called umn. You also might want to view the data to ensure that it imported into the QMD correctly. (Don’t forget to add code comments as well!)
# Load libraries
library(ggformula)
library(tidyverse)
# Import data
umn <- read_csv("data/umn-buildings.csv")
# View data
umn# A tibble: 393 × 33
bldg_num name legal_name abbr campus address type TRI_BLDG_T TRI_TRITEN
<chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr>
1 332 Cattle … Cattle Fe… CFS1 St. P… 1894 B… Acad… Agricultu… Owned
2 333 Cattle … Cattle Fe… CFS2 St. P… 1896 B… Acad… Agricultu… Owned
3 302 Beef Ca… Beef Catt… BCB St. P… 1920 B… Acad… Agricultu… Owned
4 343 Botany … Botany Fi… BFH St. P… 2033 F… Acad… Agricultu… Owned
5 345 Agronom… Agronomy … AGRSH St. P… 1472 G… Acad… Agricultu… Owned
6 346 Bee Lab… Bee Lab S… BLAB… St. P… 1634 G… Acad… Agricultu… Owned
7 347 Bee Res… Bee Resea… BRF St. P… 1634 G… Acad… Agricultu… Owned
8 351 Hog Bar… Hog Barn … HOGB3 St. P… 1845 B… Acad… Agricultu… Owned
9 355 Farm Cr… Farm Crop… FCFH St. P… 1922 H… Acad… Agricultu… Owned
10 392 Sheep R… Sheep Res… SHEE… St. P… 1794 D… Acad… Agricultu… Owned
# ℹ 383 more rows
# ℹ 24 more variables: TRI_YEAR_O <dbl>, TRI_DATE_O <chr>, TRI_YEAR_L <dbl>,
# mortenson_dates <dbl>, ada <chr>, nrhp_status <chr>, gross_sqft <dbl>,
# assignable_sqft <dbl>, net_sqft <dbl>, structural_sqft <dbl>,
# usable_sqft <dbl>, BLDG_DETAI <chr>, BLDG_PHOTO <chr>,
# women_restrooms <dbl>, men_restrooms <dbl>, undesignated_restrooms <dbl>,
# classrooms <dbl>, laboratories <dbl>, offices_spaces <dbl>, …These data include information on 393 different buildings owned by the University of Minnesota. While there are several attributes included in the data for these buildings, we are most interested in the type attribute. This attribute includes information about the primary use of the building as classified by the university (e.g., parking, residential).
To create a bar chart of the number (count) of each of the building types, we will use the gf_counts() function from the {ggfomula} library. Similar to the other plots we have created we need to identify the name of the categorical attribute we want to plot using the tilde (~) operator and also the data set object using the data= argument.
Create a new code chunk in your QMD document where you want the bar chart to appear. Inside the code chunk we will add the following syntax:
gf_counts(~type, data = umn)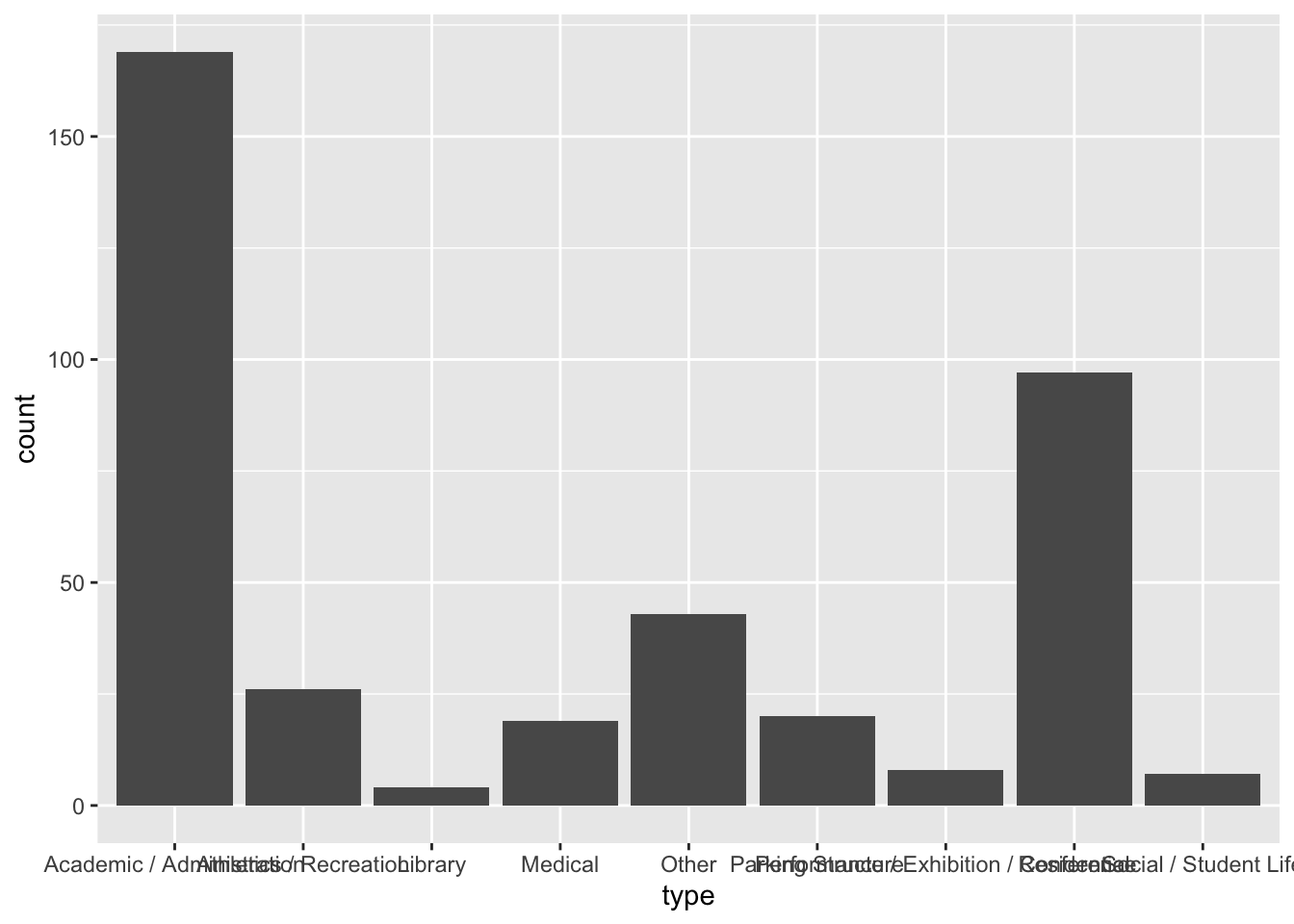
We can also add border and fill color to our bar chart similar to how we did for histograms/density plots. For example, to add a black border and a maroon fill to the bars in our plot, we can use the following syntax.
gf_counts(~type, data = umn, color = "black", fill = "maroon")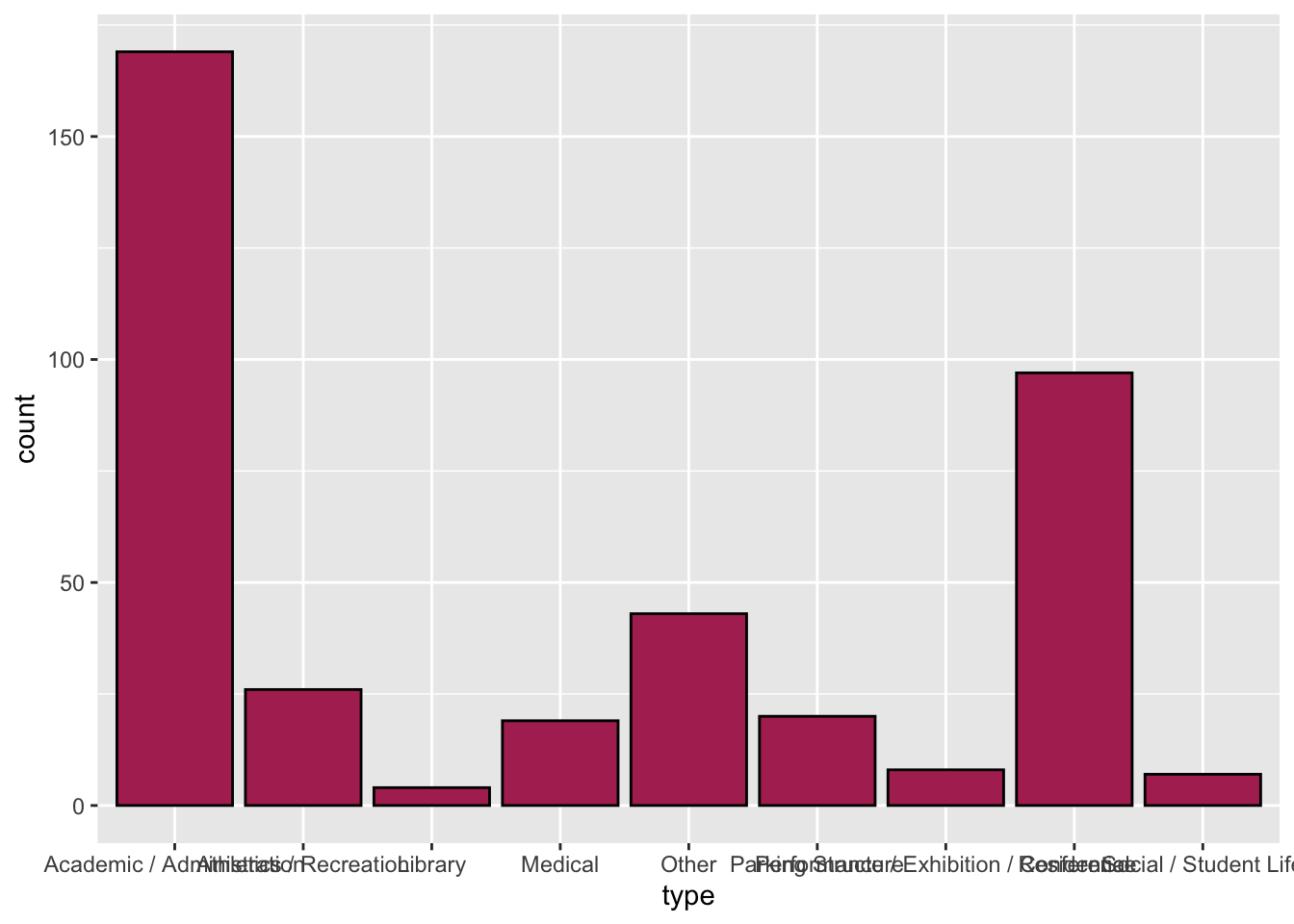
One issue in our plot is that some of the data labels overlap each other. This makes the labels difficult to read (and some of them might be impossible to read). There are a few ways we can fix this:
- First, we could try to make the figure wider. By making it wide enough, we could get the labels so that they do not overlap. However, by stretching the figure to be wider, we change the aspect ratio of the figure, which may distort other things.
- Second, we could go back and change the labels in the original CSV file to make them shorter. For example we could change the label of “Performance / Exhibition / Conference” to “Perf/Exb/Conf”. Sometimes this is a reasonable thing to do, but other times changing the label is not appropriate. (Would you know the “Perf/Exb/Conf” meant that the building type is designated as performance, exhibition, or conference space without additional text?)
- The third option is to flip plot so that the bars are horizontal rather than vertical. This would mean that the data labels would each be on a separate line of text and therefore would not overlap.
5.7 Using R to Create a Horizontal Bar Chart
To create a horizontal bar chart, we move the attribute name (type) to the left-hand side of the tilde operator in gf_counts(). Because R requires us to always have something on the right-hand side of the tilde operator, we will add a dot (.) to the right-hand side of the tilde operator. The syntax to create a horizontal bar chart of the building type data is shown below.
gf_counts(type ~ ., data = umn, color = "black", fill = "maroon")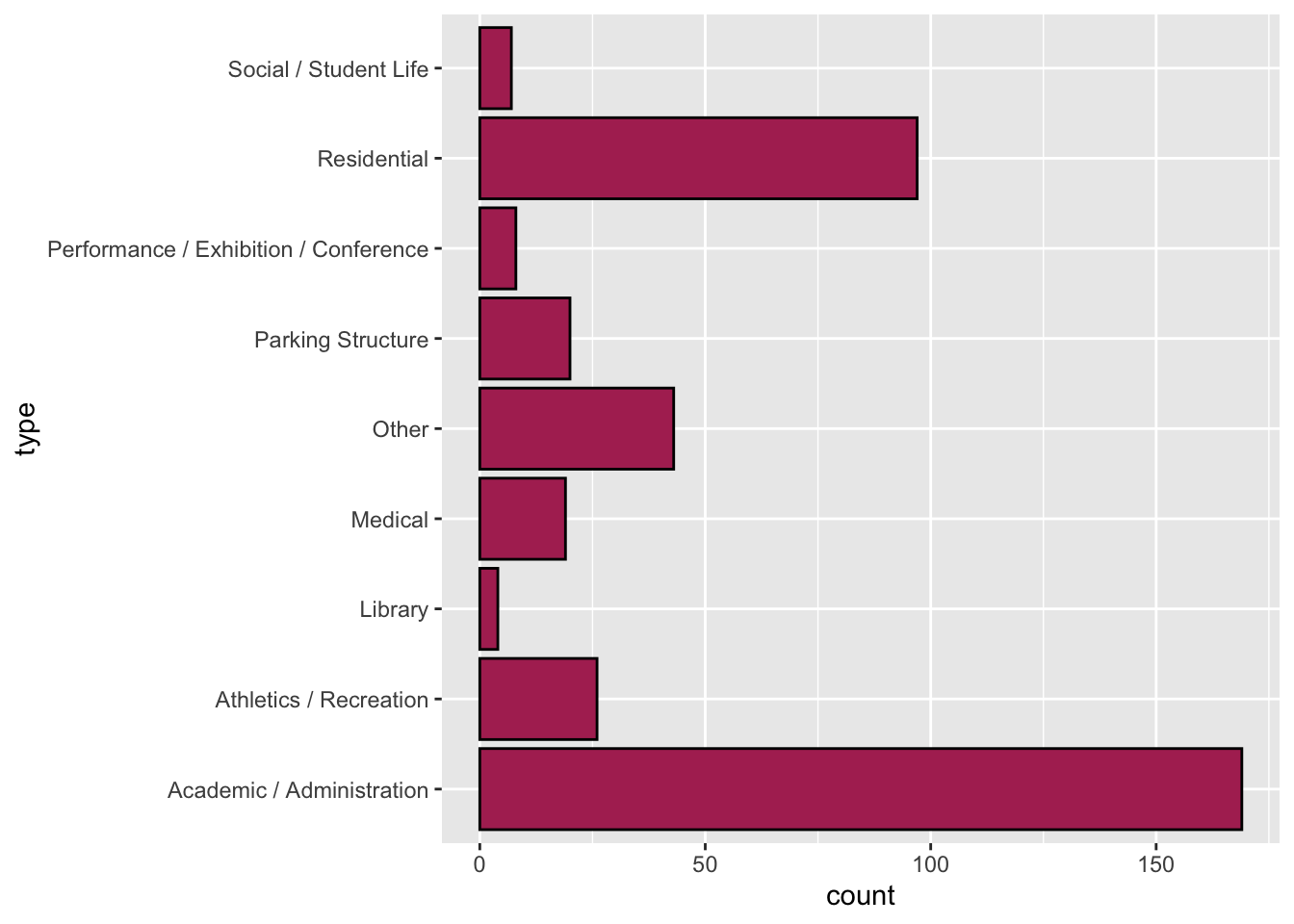
Notice that by putting the data labels on the y-axis, we avoid having the labels overlapping each other! This makes our plot easier for others to understand by removing the cognitive load associated with overlapping labels.
5.8 Using R to Create a Bar Chart of Proportions
To create a bar chart that summarizes the proportion of each category (rather than counts) we can use the gf_props() function. The syntax for this function is identical to that of gf_counts(). The syntax to create a bar chart summarizing the proportion of each building type is shown below. We also modify this plot by flipping the coordinates to create a horizontal bar chart so the data labels do not overlap.
gf_props(~type, data = umn, color = "black", fill = "maroon")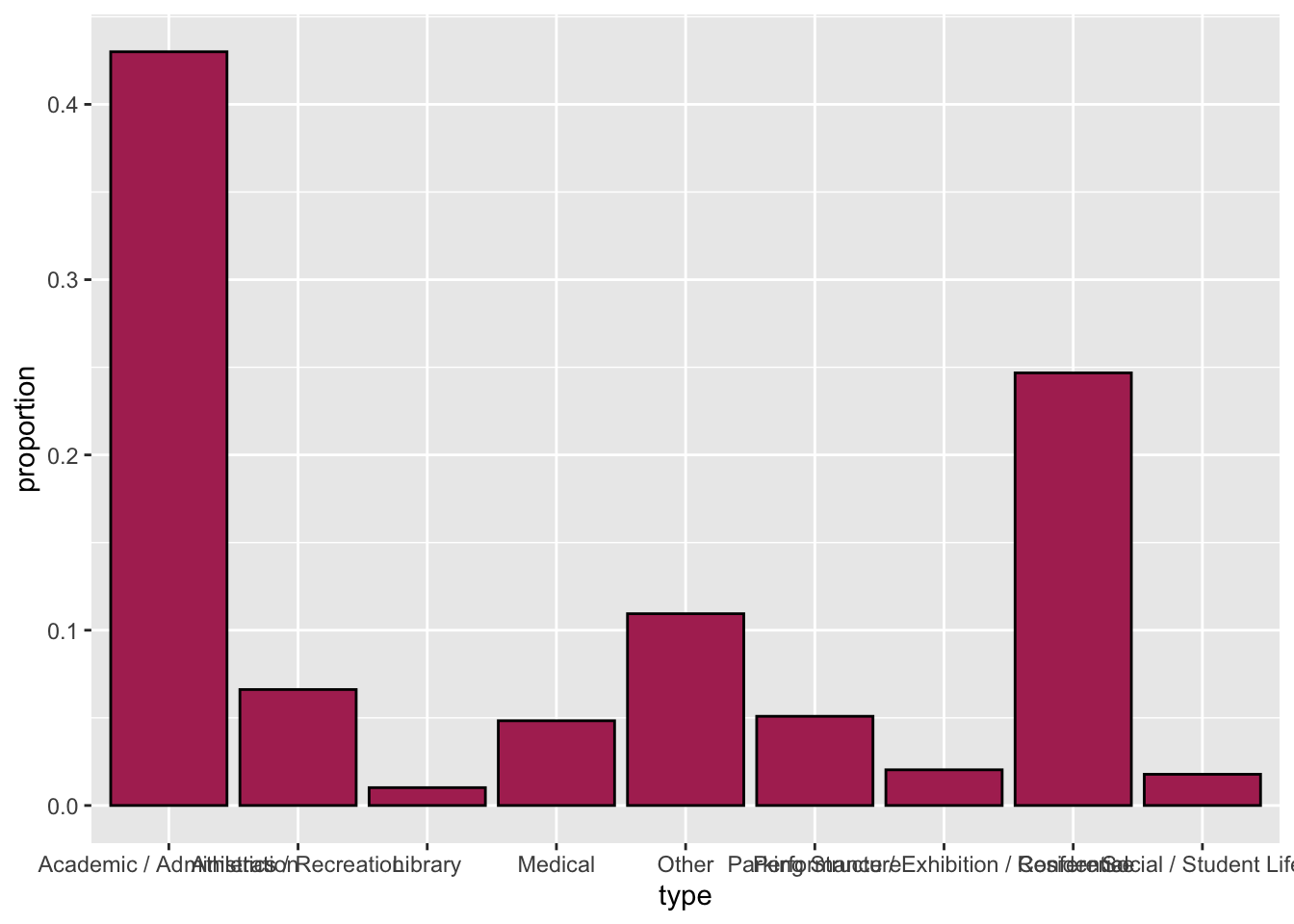
The function gf_props() can’t be used in the horizontal orientation currently.
5.9 Using R to Create a Bar Chart of Percentages
To create a bar chart summarizing the percentage of each building type, we use the gf_percents() function.
gf_percents(type ~ ., data = umn, color = "black", fill = "maroon")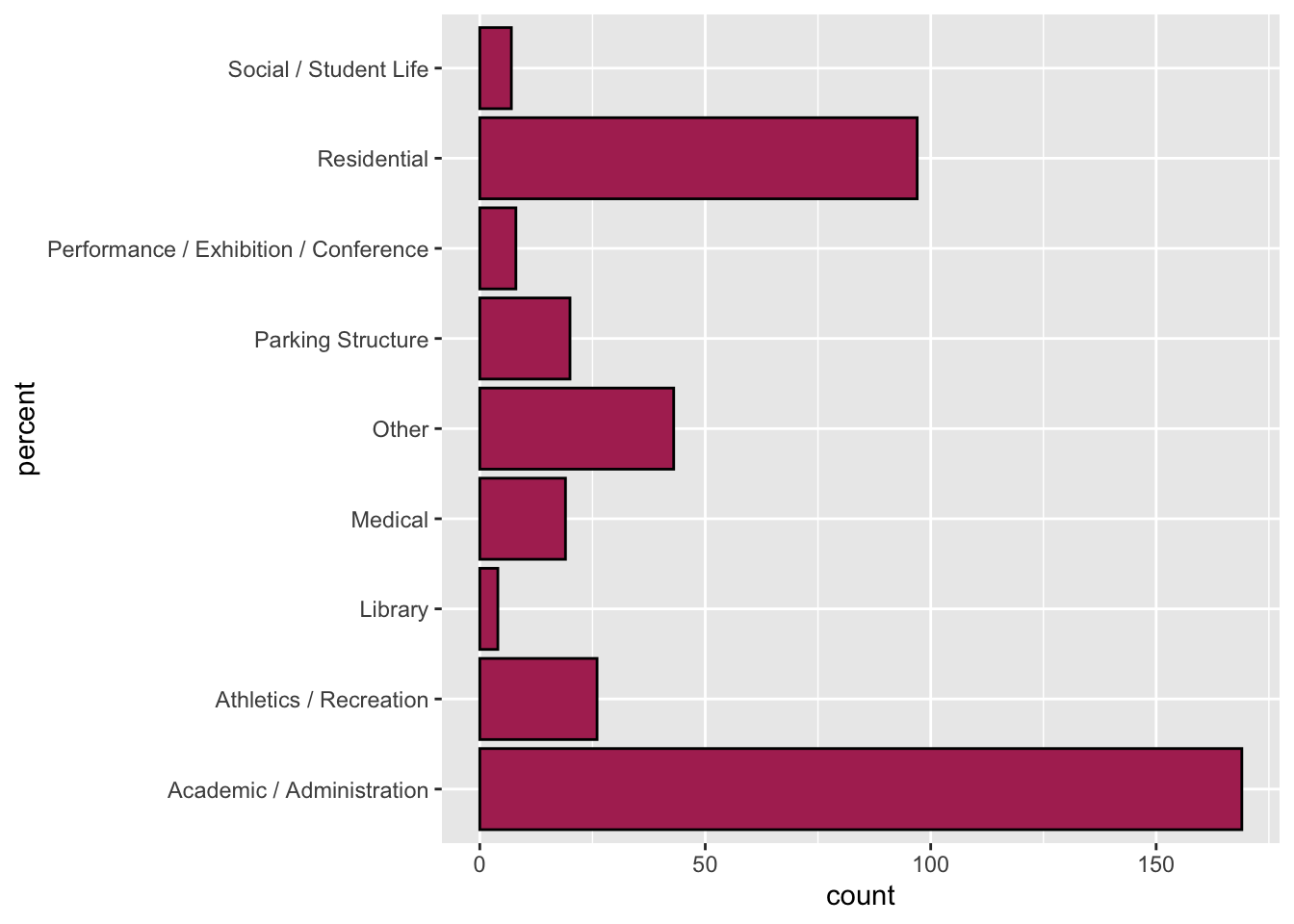
5.10 Using R to Create a Bar Chart with Summaries of Data
Sometimes you are provided with summaries of data rather than the actual data itself. For example in our pet ownership example the data would look like this:

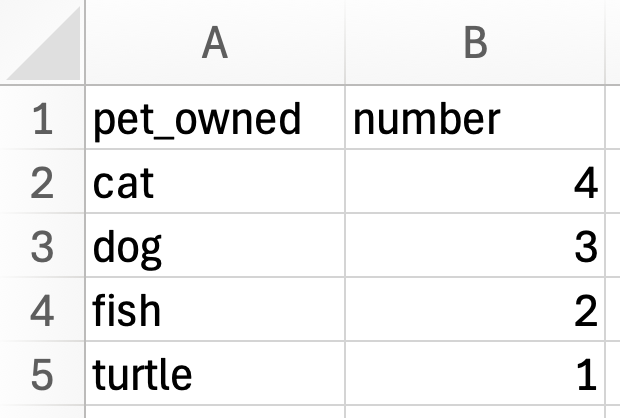
Notice that in the raw data, a case is an individual person and the pet_owned attribute indicates the pet that is owned by each of the 10 people in the data. The summary data summarizes the raw data by indicating how many people own each type of pet. In the summary data a case is the type of pet that is owned. This is also designated in the pet_owned attribute. The summary data also indicates the number of people that own each type of pet in the number attribute. A bar chart is essentially a plot of the summarized data—each bar indicates the type of pet owned, and the height of the bar indicates the count or number of people who own that type of pet.
So far, we have used raw data to create our bar charts, but is we have summary data instead of raw data we can also create a bar chart using R. To illustrate this, create a new code chunk in your QMD document and import the pet-count.csv data into an object called pets using the following code:
# Import data
pets <- read_csv("data/pet-counts.csv")
# View data
DT::datatable(pets)To create a bar chart of these data we are going to again use the gfcounts() function to plot the categorical attribute (pets_owned) from the summary data object.
gf_counts(~pet_owned, data = pets)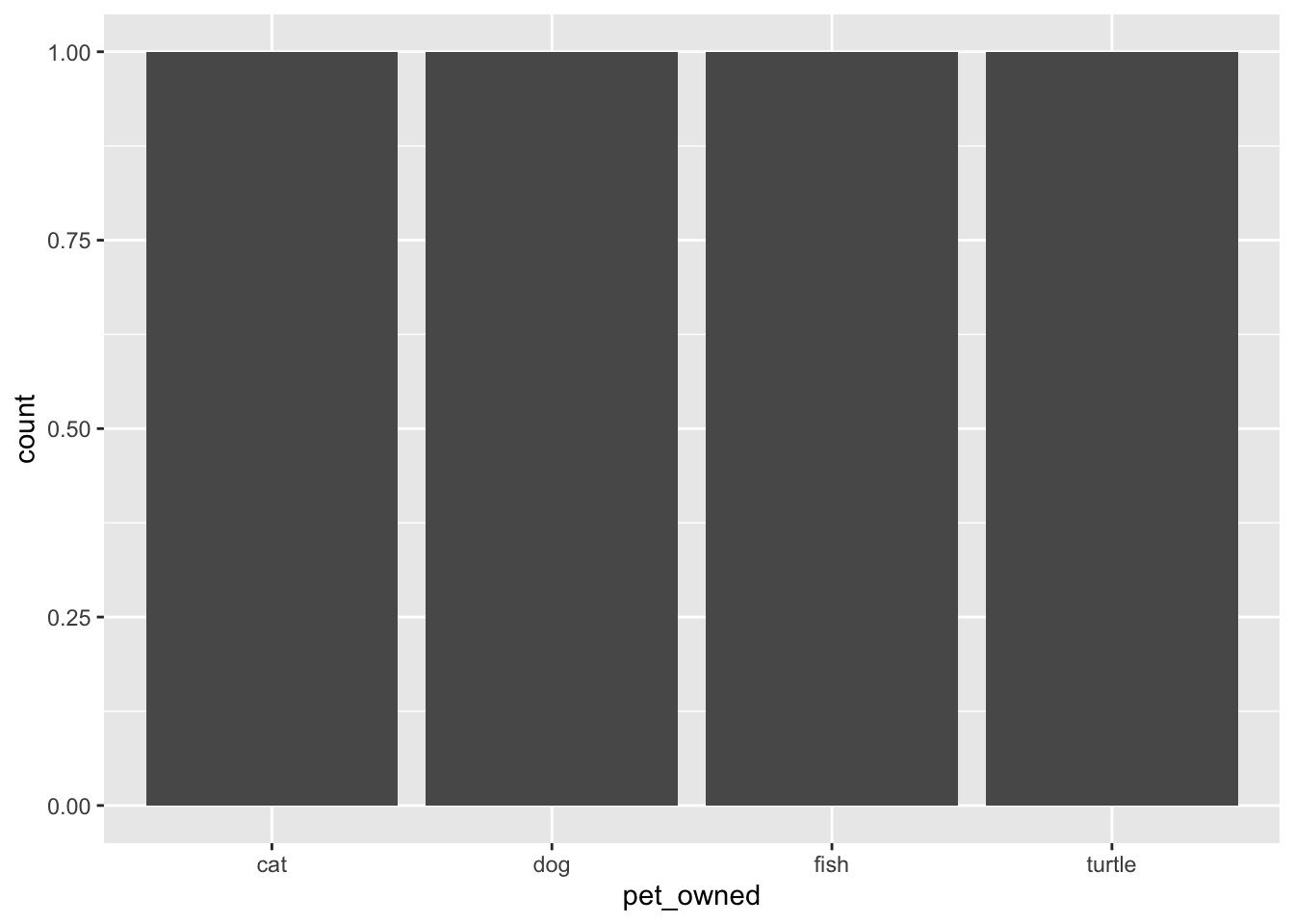
pets_owned attribute from the summary data.
This creates a bar chart of the pets owned attribute. In this data there is literally one word that says “cat”, one that says “dog”, one that says “fish”, and one that says “turtle”. So the resulting bar chart creates a bar for each of these and all of them have a count (bar height) of 1.
IMPORTANT
The functions for creating plots in R always assume you have raw data and will plot accordingly!
To inform R that we have summary data, we need to include two additional arguments in the gf_counts() function.
- The first thing we need to do is also include a
y=argument. This argument will name another attribute in the data that R will query to know how high to draw the bars. In our data, thenumberattribute indicates how high the bars should be drawn so the argument we include will be:y = ~number. Remember, any time we are using an attribute name in these functions we need to put a tilde (~) in fron of the attribute name! - The second argument we need to include in the function is
stat = "identity". Because thegf_count()function (and others likegf_percent()) assume that we have raw data, the function will try to summarize the data (count it) in order to know the bar height. The argumentstat = "identity"tells the function to not summarize, but instead use the information in they=argument to know how high the bars should be.
To create the bar chart of the summarized data, we can use the following code:
gf_counts(~pet_owned, data = pets, y = ~number, stat = "identity")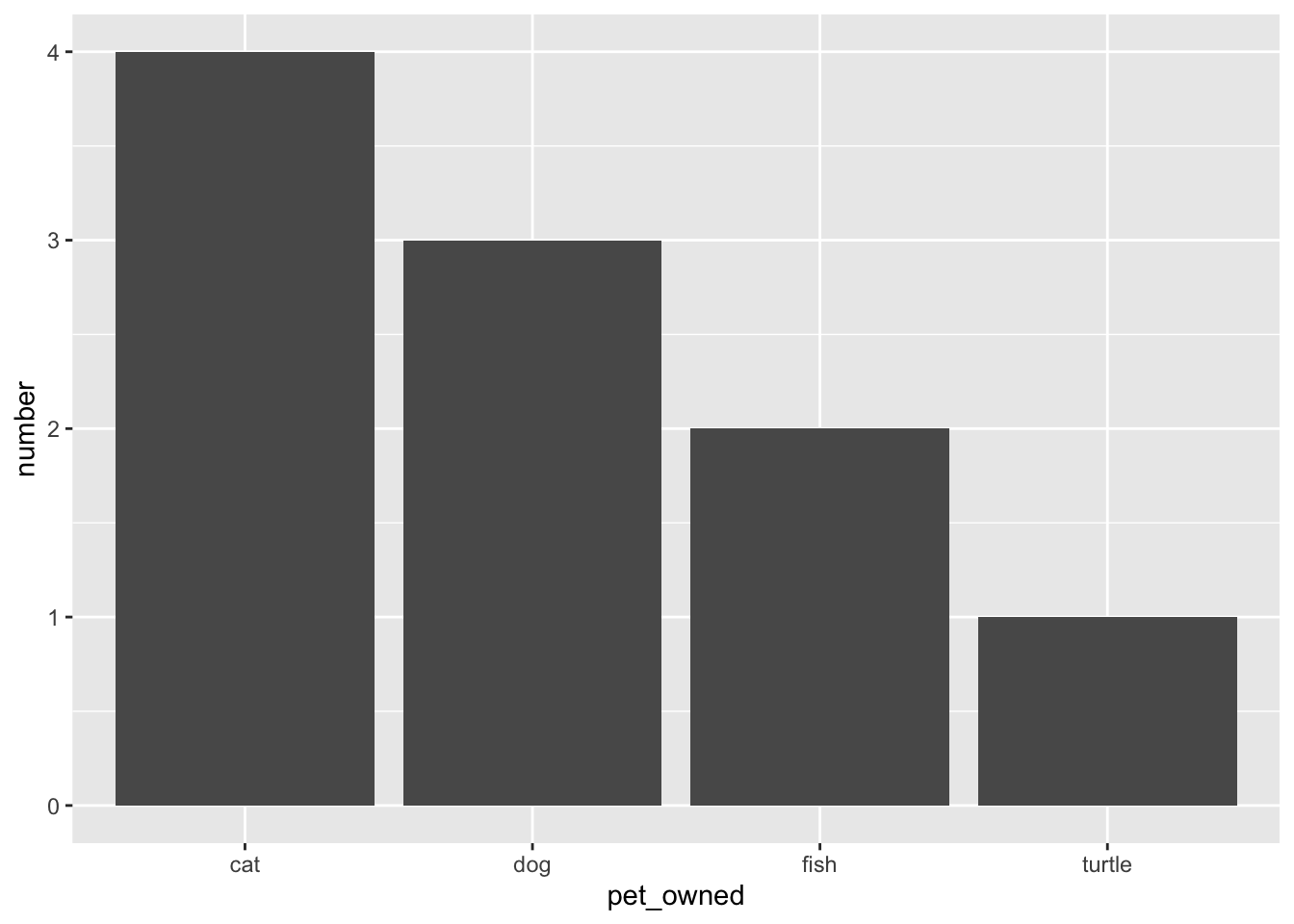
pets_owned attribute from the summary data. The counts from the number column are being used to indicate the bar height.
As with other bar charts, we can also add border color, bar fill, and make it a horizontal bar chart. (Note that in this case the count will be on the x-axis instead of the y-axis, so we need to assign the number attribute to x= rather than y=.)
gf_counts(pet_owned ~ ., data = pets, x = ~number, stat = "identity", color = "black", fill = "maroon")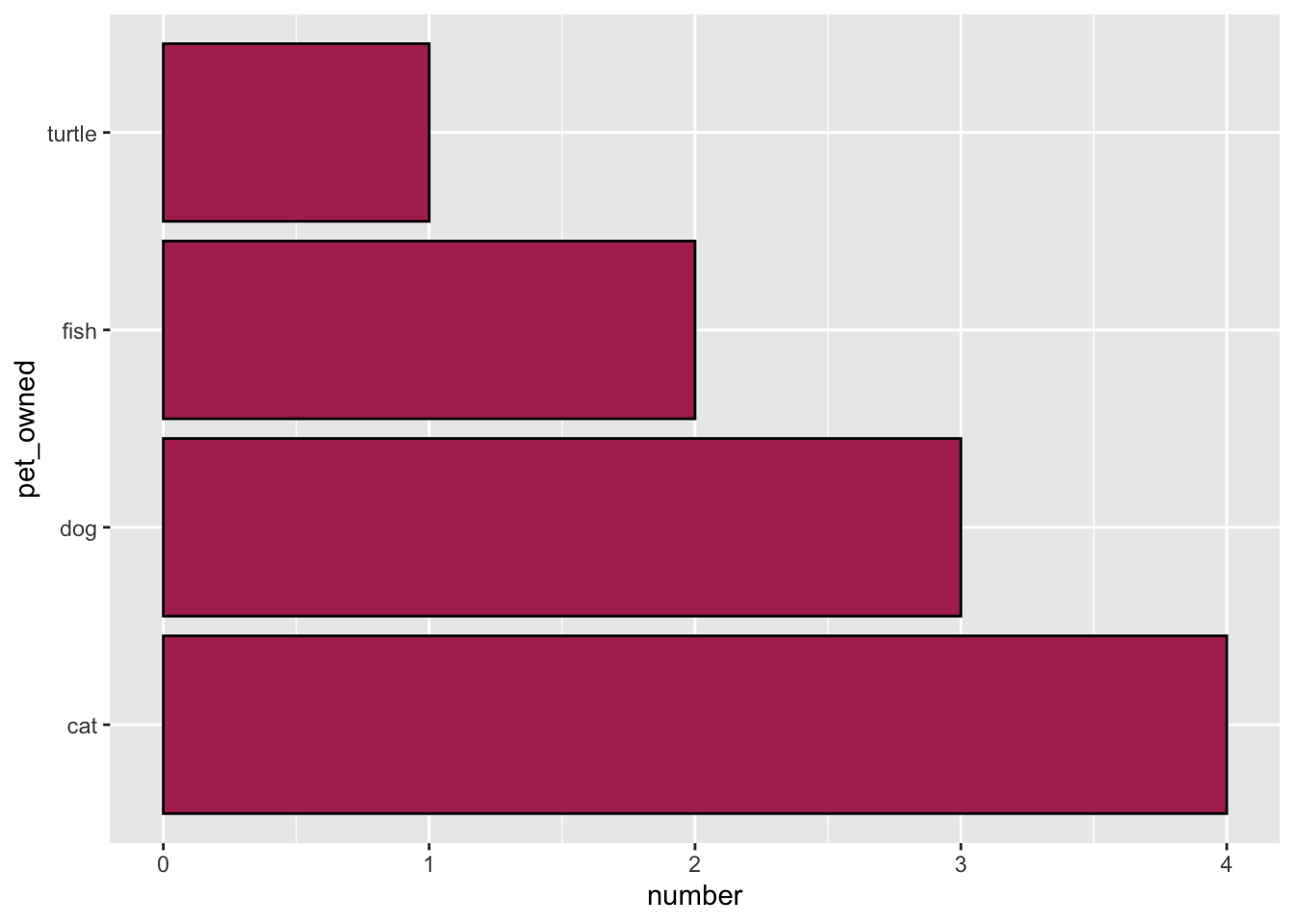
pets_owned attribute from the summary data. The counts from the number column are being used to indicate the bar length.
5.11 Pro Tip: Breaking Up Long Code
One pro coding tip is to pay attention to how long the lines of code are that you are writing. We know from research that humans are worse at cognitively parsing longer lines of code than they are at parsing shorter lines of code. The previous code in the gf_counts() function is starting to get long—it includes a lot of arguments. When you use functions that contain a lot of arguments, consider breaking this code up into multiple lines. For example, the same code as above could be broken up in the following way:
gf_counts(pet_owned ~ ., data = pets,
y = ~number, stat = "identity",
color = "black", fill = "maroon"
)- The first line includes the basic code to create a bar chart.
- The second line includes the two arguments necessary for plotting the summarized data correctly.
- The third line includes the arguments that change the color; both border and bar fill color.
Another way to break up the code that data scientists often use is to place one argument on it’s own line. For example:
gf_counts(
pet_owned ~ .,
data = pets,
y = ~number,
stat = "identity",
color = "black",
fill = "maroon"
)Both manners of breaking up the code are legitimate and make the code easier to read and understand for humans. It is a coding choice that you get to make. The important thing is that you make your code easier for humans to read!
Exercises: Your Turn
Consider the following data from the umn-bike-amenities.csv file.
# Import data
bike_amenities <- read_csv("data/umn-bike-amenities.csv")
# View data
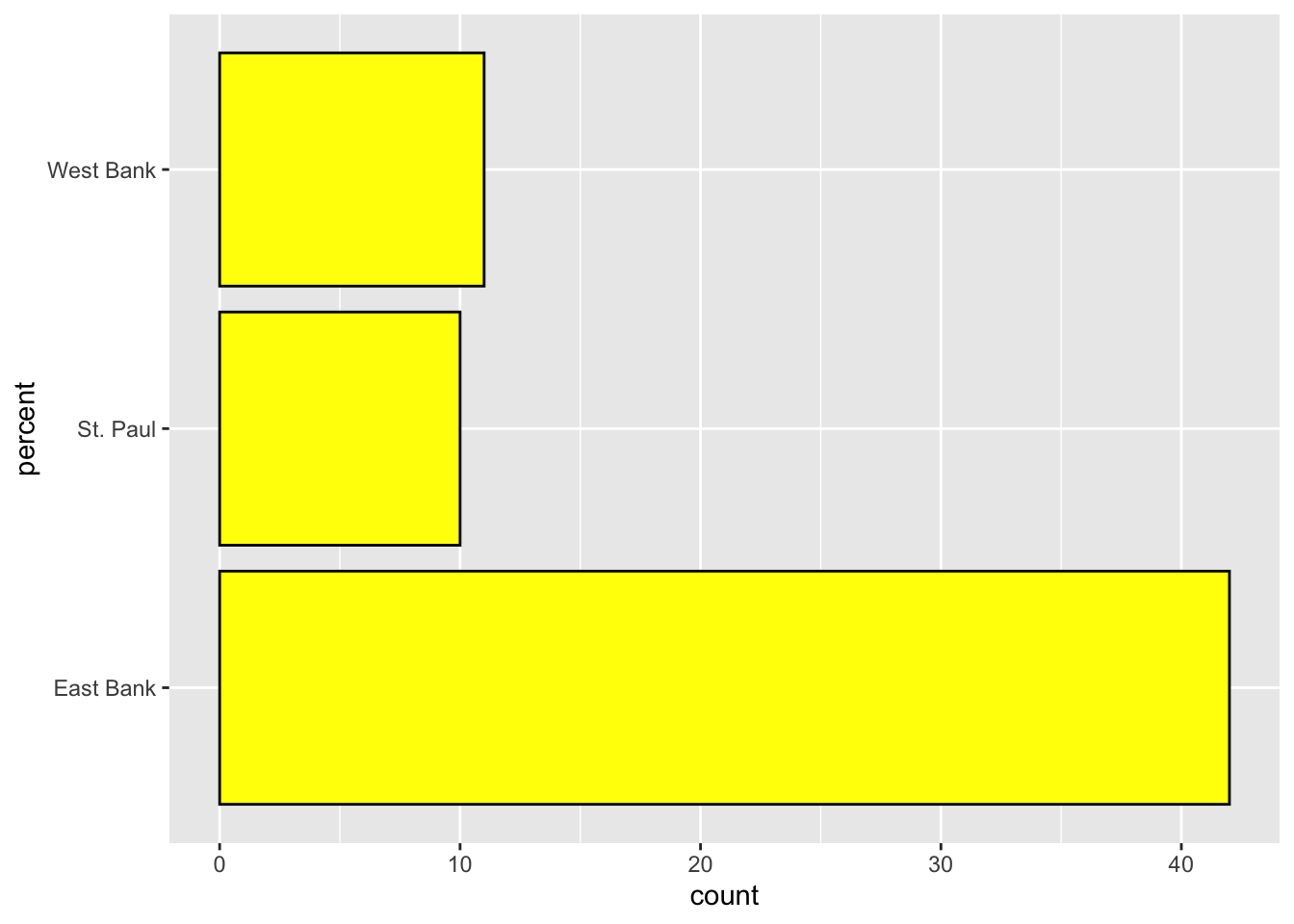
DT::datatable(bike_amenities)Imagine that this has been imported into a data object called bike_amenities. Also suppose we wanted to create a bar chart of the campus attribute, which provides the campus location (East Bank, West Bank, or St. Paul) of the bike amenities in the data.
- This is raw data, not summary data. Explain why.
- Write out the syntax to create a bar chart of the counts for the
campusattribute.
- Describe the distribution of the bar chart you created in Exercise #2.
- Write out the syntax to create a horizontal bar chart of the percentages for the
campusattribute. Also color the bar borders black and fill the bars with yellow.
To keep it simple, assume each pet owner only has a single pet.↩︎